WO2009021674A1 - Predictive markers for egfr inhibitor treatment - Google Patents
Predictive markers for egfr inhibitor treatment Download PDFInfo
- Publication number
- WO2009021674A1 WO2009021674A1 PCT/EP2008/006513 EP2008006513W WO2009021674A1 WO 2009021674 A1 WO2009021674 A1 WO 2009021674A1 EP 2008006513 W EP2008006513 W EP 2008006513W WO 2009021674 A1 WO2009021674 A1 WO 2009021674A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- gene
- expression level
- patient
- egfr inhibitor
- cancer
- Prior art date
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
- C12Q1/6883—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material
- C12Q1/6886—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material for cancer
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/15—Medicinal preparations ; Physical properties thereof, e.g. dissolubility
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/106—Pharmacogenomics, i.e. genetic variability in individual responses to drugs and drug metabolism
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/118—Prognosis of disease development
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/158—Expression markers
Definitions
- the present invention provides biomarkers that are predictive for the clinical benefit of EGFR inhibitor treatment in cancer patients.
- EGF epidermal growth factor receptor
- TGF- ⁇ transforming growth factor- ⁇
- TGF- ⁇ transforming growth factor- ⁇
- tumour cell proliferation in vitro. It has been postulated that stimulation of tumour cells via the EGFR may be important for both tumour growth and tumour survival in vivo.
- TarcevaTM an inhibitor of the EGFR tyrosine kinase
- Clinical phase I and II trials in patients with advanced disease have demonstrated that TarcevaTM has promising clinical activity in a range of epithelial tumours. Indeed, TarcevaTM has been shown to be capable of inducing durable partial remissions in previously treated patients with head and neck cancer, and NSCLC (Non small cell lung cancer) of a similar order to established second line chemotherapy, but with the added benefit of a better safety profile than chemo therapy and improved convenience (tablet instead of intravenous [i.v.] administration).
- a recently completed, randomised, double-blind, placebo-controlled trial (BR.21) has shown that single agent TarcevaTM significantly prolongs and improves the survival of NSCLC patients for whom standard therapy for advanced disease has failed.
- TarcevaTM (erlotinib) is a small chemical molecule; it is an orally active, potent, selective inhibitor of the EGFR tyrosine kinase (EGFR-TKI).
- Lung cancer is the major cause of cancer-related death in North America and Europe. In the United States, the number of deaths secondary to lung cancer exceeds the combined total deaths from the second (colon), third (breast), and fourth (prostate) leading causes of cancer deaths combined. About 75% to 80% of all lung cancers are NSCLC, with approximately 40% of patients presenting with locally advanced and/or unresectable disease. This group typically includes those with bulky stage IIIA and IIIB disease, excluding malignant pleural effusions.
- Advanced tumours often are not amenable to surgery and may also be resistant to tolerable doses of radiotherapy and chemotherapy.
- the currently most active combination chemotherapies achieved response rates of approximately 30% to 40% and a 1-year survival rate between 35% and 40%. This is really an advance over the 10% 1-year survival rate seen with supportive care alone (Shepherd 1999).
- the present invention provides an in vitro method of predicting the clinical benefit of a cancer patient in response to treatment with an EGFR inhibitor.
- Said method comprises the steps: determining an expression level of at least one gene selected from table 3 in a tumour sample of a patient and comparing the expression level of the at least one gene to a value representative of an expression level of the at least one gene in tumours of a population of patients deriving no clinical benefit from the treatment, wherein a differential expression level of the at least one gene in the tumour sample of the patient is indicative for a patient who will derive clinical benefit from the treatment.
- a value representative of an expression level of the at least one marker gene in tumours of a population of patients deriving no clinical benefit from the treatment refers to an estimate of the mean expression level of a marker gene in tumours of a population of patients who do not derive a clinical benefit from the treatment.
- Clinical benefit was defined as either having an objective response, or disease stabilization for > 12 weeks.
- the expression level of at least two genes is determined.
- the expression level of at least three genes is determined.
- the gene is selected from the group consisting of
- the gene is selected from the group consisting of SDCl, CEBPA, ST6GALNAC2, PLA2G6, PMS2L1 1, C19orf7, DDXl 7, SFPQ, PMS2L3, SLC35E2, PMSL2, URG4, PPP1R13B, NRCAM, FLJ10916, FLJ13197, GPR172B, ZNF506, ARHGAP8, CELSRl, LYK5 and said gene shows a higher expression level in the tumour sample of the patient compared to the value representative of the expression level in tumours of the population of patients deriving no clinical benefit from the treatment.
- the expression level of the at least one gene is determined by microarray technology.
- the construction and use of gene chips are well known in the art. see, U. S. Pat Nos. 5,202,231; 5,445,934; 5,525,464; 5,695,940; 5,744,305; 5,795, 716 and 1
- gene expression level can be determined by other methods that are known to a person skilled in the art such as e.g. northern blots, RT-PCR, real time quantitative PCR, primer extension, RNase protection, RNA expression profiling.
- Biomarker sets can be built from any combination of biomarkers listed in Table 3 to make predictions about the effect of EGFR inhibitor treatment in cancer patients.
- the various biomarkers and biomarkers sets described herein can be used, for example, to predict how patients with cancer will respond to therapeutic intervention with an EGFR inhibitor.
- the term "gene” as used herein comprises variants of the gene.
- the term “variant” relates to nucleic acid sequences which are substantially similar to the nucleic acid sequences given by the GenBank accession number.
- the term “substantially similar” is well understood by a person skilled in the art.
- a gene variant may be an allele which shows nucleotide exchanges compared to the nucleic acid sequence of the most prevalent allele in the human population.
- such a substantially similar nucleic acid sequence has a sequence similarity to the most prevalent allele of at least 80%, preferably at least 85%, more preferably at least 90%, most preferably at least 95%.
- variants is also meant to relate to splice variants.
- the EGFR inhibitor can be selected from the group consisting of gefitinib, erlotinib,
- the EGFR inhibitor is erlotinib.
- the cancer is NSCLC.
- Techniques for the detection of gene expression of the genes described by this invention include, but are not limited to northern blots, RT-PCR, real time quantitative PCR, primer extension, RNase protection, RNA expression profiling and related techniques. These techniques are well known to those of skill in the art see e.g. Sambrook J et al., Molecular Cloning: A Laboratory Manual, Third Edition (Cold Spring Harbor Press, Cold Spring Harbor, 2000).
- IHC immunohistochemistry
- cells from a patient tissue sample e.g., a tumour or cancer biopsy
- test cells e.g., tumour or cancer biopsy
- results or failure of a cancer treatment can be determined based on the biomarker expression pattern of the cells from the test tissue (test cells), e.g., tumour or cancer biopsy, as being relatively similar or different from the expression pattern of a control set of the one or more biomarkers.
- test cells e.g., tumour or cancer biopsy
- test cells show a biomarker expression profile which corresponds to that of a patient who responded to cancer treatment, it is highly likely or predicted that the individual's cancer or tumour will respond favorably to treatment with the EGFR inhibitor.
- biomarkers of the present invention i.e.
- the genes listed in table 3 are a first step towards an individualized therapy for patients with cancer, in particular patients with refractory NSCLC.
- This individualized therapy will allow treating physicians to select the most appropriate agent out of the existing drugs for cancer therapy, in particular NSCLC.
- the benefit of individualized therapy for each future patient are: response rates / number of benefiting patients will increase and the risk of adverse side effects due to ineffective treatment will be reduced.
- the present invention provides a therapeutic method of treating a cancer patient identified by the in vitro method of the present invention.
- Said therapeutic method comprises administering an EGFR inhibitor to the patient who has been selected for treatment based on the predictive expression pattern of at least one of the genes listed in table 3.
- a preferred EGFR inhibitor is erlotinib and a preferred cancer to be treated is NSCLC.
- tumour sample was collected at the same time and stored in paraffin (formalin fixed paraffin embedded, FFPE). This sample was analysed for alterations in the EGFR signaling pathway. The ability to perform tumour biopsies via bronchoscopy was a prerequisite for this study. Bronchoscopy is a standard procedure to confirm the diagnosis of lung cancer. Although generally safe, there is a remaining risk of complications, e.g. bleeding.
- This study was a first step towards an individualized therapy for patients with refractory NSCLC. This individualized therapy will allow treating physicians to select the most appropriate agent out of the existing drugs for this indication.
- TarcevaTM was given orally once per day at a dose of 150 mg until disease progression, intolerable toxicities or death. The selection of this dose was based on pharmacokinetic parameters, as well as the safety and tolerability profile of this dose observed in Phase I, II and III trials in heavily pre-treated patients with advanced cancer. Drug levels seen in the plasma of patients with cancer receiving the 150 mg/day dose were consistently above the average plasma concentration of 500 ng / ml targeted for clinical efficacy. BR.21 showed a survival benefit with this dose. Objectives of the Study The primary objective was the identification of differentially expressed genes that are predictive for clinical benefit (CR, PR or SD >12 weeks) of TarcevaTM treatment. Identification of differentially expressed genes predictive for "response" (CR, PR) to TarcevaTM treatment was an important additional objective.
- Tumour tissue and blood samples were obtained for molecular analyses to evaluate the effects of TarcevaTM and to identify subgroups of patients benefiting from therapy. Predictive Marker Assessments
- Biopsies of the tumour were taken within 2 weeks before start of treatment. Two different samples were collected:
- the second sample was fixed in formalin and embedded in paraffin Snap frozen tissue had the highest priority in this study.
- Figure 2 shows a scheme of the sample processing.
- the snap frozen samples were used for laser capture microdissection (LCM) of tumour cells to extract tumour RNA and RNA from tumour surrounding tissue.
- the RNA was analysed on Affymetrix microarray chips (HG-U 133A) to establish the patients' tumour gene expression profile. Quality Control of Affymetrix chips was used to select those samples of adequate quality for statistical comparison.
- the second tumour biopsy was used to perform DNA mutation, IHC and ISH analyses as described below. Similar analyses were performed on tissue collected at initial diagnosis.
- the DNA mutation status of the genes encoding EGFR and other molecules involved in the EGFR signaling pathway were analysed by DNA sequencing. Gene amplification of EGFR and related genes were be studied by FISH. Protein expression analyses included immunohistochemical [IHC] analyses of EGFR and other proteins within the EGFR signalling pathway.
- the RECIST Uni-dimensional Tumour Measurement
- RECIST Uni-dimensional Tumour Measurement
- These criteria can be found under the following link: http://www.eortc.be/recist/ Note that:To be assigned a status of CR or PR, changes in tumour measurements must be confirmed by repeated assessments at least 4 weeks apart at any time during the treatment period.
- follow-up measurements must have met the SD criteria at least once after study entry at a minimum interval of 6 weeks.
- follow-up measurements must have met the SD criteria at least once after study entry with maintenance duration of at least 12 weeks.
- RNases are RNA degrading enzymes and are found everywhere and so all procedures where RNA will be used must be strictly controlled to minimize RNA degradation. Most mRNA species themselves have rather short half-lives and so are considered quite unstable.
- RNA concentration and quality profile can be assessed using an instrument from Agilent (Agilent Technologies, Inc., Palo Alto, CA) called a 2100 Bioanalyzer®.
- the instrument software generates an RNA Integrity Number (RIN), a quantitation estimate (Schroeder, A., et al., The RIN: an RNA integrity number for assigning integrity values to RNA measurements. BMC MoI Biol, 2006. 7: p. 3), and calculates ribosomal ratios of the total RNA sample.
- the RJN is determined from the entire electrophoretic trace of the RNA sample, and so includes the presence or absence of degradation products.
- the RNA quality was analysed by a 2100 Bioanalyzer®.
- RNA samples were received from the pathology lab for further processing.
- Target labeling was carried out according to the Two-Cycle Target Labeling Amplification Protocol from Affymetrix (Affymetrix, Santa Clara, California), as per the manufacturer's instructions.
- the method is based on the standard Eberwine linear amplification procedure [but uses two cycles of this procedure to generate sufficient labeled cRNA for hybridization to a microarray.
- Total RNA input used in the labeling reaction was IOng for those samples where more than IOng RNA was available; if less than this amount was available or if there was no quantity data available (due to very low RNA concentration), half of the total sample was used in the reaction. Yields from the labeling reactions ranged from 20-180 ⁇ g cRNA.
- a normalization step was introduced at the level of hybridization where 15 ⁇ g cRNA was used for every sample.
- RNA Human Reference RNA (Stratagene, Carlsbad, CA, USA) was used as a control sample in the workflow with each batch of samples. IOng of this RNA was used as input alongside the test samples to verify that the labeling and hybridization reagents were working as expected. Microarray hybridizations
- Affymetrix HG-U 133 A microarrays contain over 22,000 probe sets targeting approximately 18,400 transcripts and variants which represent about 14,500 well- characterized genes.
- Hybridization for all samples was carried out according to Affymetrix instructions (Affymetrix Inc., Expression Analysis Technical Manual, 2004). Briefly, for each sample,
- GCOS GeneChip Operating Software
- Step 1 was quality control. The goal was to identify and exclude from analysis array data with a sub-standard quality profile.
- Step 2 was pre-processing and normalization. The goal was to create a normalized and scaled "analysis data set", amenable to inter-chip comparison. It comprised background noise estimation and subtraction, probe summarization and scaling.
- Step 3 was exploration and description. The goal was to identify potential bias and sources of variability. It consisted of applying multivariate and univariate descriptive analysis techniques to identify influential covariates.
- Step 4 was modeling and testing. The goal was to identify a list of candidate markers based on statistical evaluation of the difference in mean expression level between "clinical benefit” and "no clinical benefit” patients. It consisted in fitting an adequate statistical model to each probe-set and deriving a measure of statistical significance.
- Step 5 was a robustness analysis. The goal was to generate a qualified list of candidate markers that do not heavily depend on the pre-processing methods and statistical assumptions. It consisted in reiterating the analysis with different methodological approaches and intersecting the list of candidates.
- Step 1 Quality Control
- This step also included visual inspection of virtual chip images for detecting localized hybridization problems, and comparison of each chip to a virtual median chip for detecting any unusual departure from median behavior. Inter-chip correlation analysis was also performed to detect outlier samples. In addition, ancillary measures of RNA quality obtained from analysis of RNA samples with the Agilent BioanalyzerTM 2100 were taken into consideration.
- Step 2 Data pre-processing and normalization
- the rma algorithm (Irizarry, R. A., et al., Summaries of Affymetrix GeneChip probe level data. Nucl. Acids Res., 2003. 31(4): p. el5) was used for pre-processing and normalization.
- the mas5 algorithm (AFFYMETRIX, GeneChip® Expression: Data Analysis
- Probe-sets called “absent” or “marginal” in all samples were removed from further analysis; 5930 probe-sets were removed from analysis based on this criterion.
- the analysis data set therefore consisted of a matrix with 16353 (out of 22283) probe-sets measured in 102 patients.
- RNA processing (later referred to as batch), RIN (Schroeder, A., et al., The RIN: an RNA integrity number for assigning integrity values to RNA measurements. BMC MoI Biol, 2006. 7: p. 3) (as a measure of RNA quality/integrity), Operator and Center of sample collection.
- Clinical covariates included: Histology type, smoking status, tumour grade, performance score (Oken, M.M., et al., Toxicity and response criteria of the Eastern Cooperative Oncology Group. Am J Clin Oncol, 1982. 5(6): p. 649-55), demographic data, responder status and clinical benefit status.
- the analysis tools included univariate ANOVA and principal component analysis. For each of these covariates, univariate ANOVA was applied independently to each probe-set. A significant effect of the batch variable was identified. In practice, the batch variable captured differences between dates of sample processing and Affymetrix chip lot. After checking that the batch variable was nearly independent from the variables of interest, the batch effect was corrected using the method described in Johnson, W.E., C. Li, and A. Rabinovic, Adjusting batch effects in microarray expression data using empirical Bayes methods. Biostat, 2007. 8(1): p. 118-127.
- the normalized data set after batch effect correction served as the analysis data set in subsequent analyses.
- Step 4 Data modeling and testing.
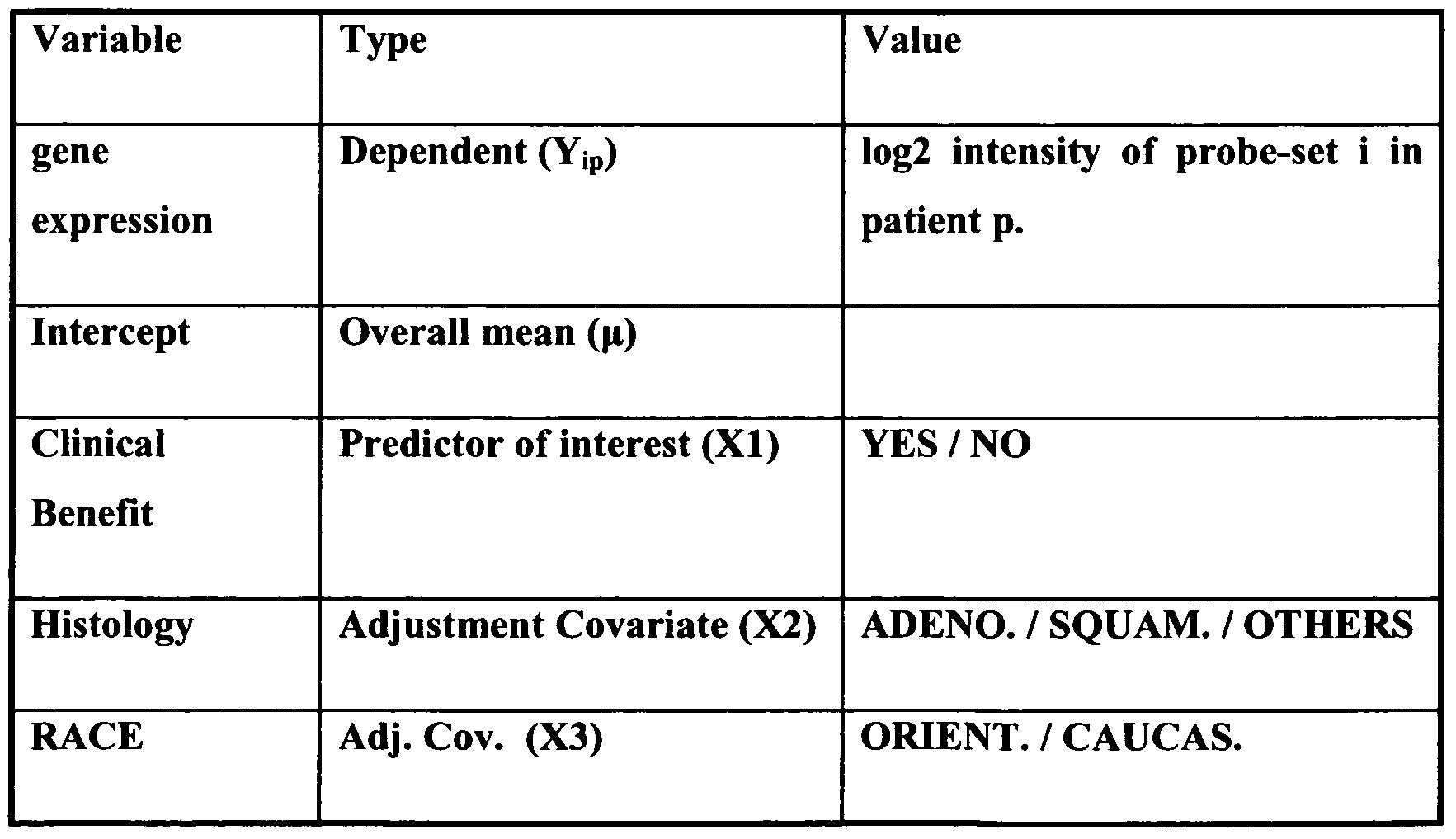
- Table 2 Description of the variables included in the linear model.
- the aim of the statistical test was to reject the hypothesis that the mean expression levels in patients with clinical benefit and patients without clinical benefit are equal, taking into account the other adjustment covariates listed in table 2.
- the null hypothesis of equality was tested against a two sided alternative. The corresponding p- values are reported in table 3.
- linear modeling is a versatile, well-characterized and robust approach that allows for adjustment of confounding variables when estimating the effect of the variable of interest.
- sample size of 102 and the normalization and scaling of the data set, the normal distribution assumption was reasonable and justified.
- Step 5 Robustness
- the goal of the robustness analysis was to reduce the risk that the results of the analysis might be artifactual and a result of the pre-processing steps or assumptions underlying the statistical analysis.
- the following three aspects were considered: a) inclusion or exclusion of a few extra chips at the quality control step; b) pre-processing and normalization algorithm; c) statistical assumptions and testing approach.
- the list of candidate markers was defined as the subset of genes consistently declared as significant with different analysis settings.
- the different applied analysis options were the following: a) An additional subset of 8 chips was identified based on more stringent quality control criteria. A "reduced data set" was defined by excluding these 8 chips.
- MAS5 was identified as an alternative to rma for pre-processing and normalization. MAS5 uses different method for background estimation, probe summarization and normalization.
- Two additional statistical tests were employed. These two additional tests rely on a different set of underlying statistical assumptions.
- Table 3 Gene markers of Clinical Benefit based on the robustness analysis after application of the composite Criterion.
- Column 1 is the Affymetrix identifier of the probe-set.
- Column 2 is the GenBank accession number of the corresponding gene sequence.
- Column 3 is the corresponding official gene name.
- Column 4 is the corresponding adjusted mean fold change in expression level between clinical and no clinical benefit patient, as estimated with the linear model.
- Column 5 is the p-value for the test of difference in expression level between clinical benefit and no clinical benefit patients as derived from the linear model.
- table 3 contains genes that are useful for discriminating different tumour categories, in particular with regard to response to the EGFR inhibitor Erlotinib.
- Column 1 is the GenBank accession number of the human gene sequence; Column 2 is the corresponding official gene name and Column 3 is the Sequence Identification number of the human nucleotide sequence as used in the present application.
- table 4 contains more than one sequence identification number since several variants of the gene are registered in the GeneBank.
Abstract
Description








Claims
Priority Applications (8)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| MX2010001571A MX2010001571A (en) | 2007-08-14 | 2008-08-07 | Predictive markers for egfr inhibitor treatment. |
| EP08785419A EP2188391A1 (en) | 2007-08-14 | 2008-08-07 | Predictive markers for egfr inhibitor treatment |
| US12/672,946 US20110184004A1 (en) | 2007-08-14 | 2008-08-07 | Predictive marker for egfr inhibitor treatment |
| BRPI0815415-5A2A BRPI0815415A2 (en) | 2007-08-14 | 2008-08-07 | PREDICTIVE MARKER FOR EGFR INHIBITOR TREATMENT |
| CA2695485A CA2695485A1 (en) | 2007-08-14 | 2008-08-07 | Predictive markers for egfr inhibitor treatment |
| CN200880103326A CN101778954A (en) | 2007-08-14 | 2008-08-07 | Predictive markers for egfr inhibitor treatment |
| AU2008286407A AU2008286407A1 (en) | 2007-08-14 | 2008-08-07 | Predictive markers for EGFR inhibitor treatment |
| JP2010520464A JP2010535517A (en) | 2007-08-14 | 2008-08-07 | Predictive marker for EGFR inhibitor treatment |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP07114292.1 | 2007-08-14 | ||
| EP07114292 | 2007-08-14 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2009021674A1 true WO2009021674A1 (en) | 2009-02-19 |
Family
ID=39884813
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/EP2008/006513 WO2009021674A1 (en) | 2007-08-14 | 2008-08-07 | Predictive markers for egfr inhibitor treatment |
Country Status (9)
| Country | Link |
|---|---|
| EP (1) | EP2188391A1 (en) |
| JP (1) | JP2010535517A (en) |
| KR (1) | KR20100037637A (en) |
| CN (1) | CN101778954A (en) |
| AU (1) | AU2008286407A1 (en) |
| BR (1) | BRPI0815415A2 (en) |
| CA (1) | CA2695485A1 (en) |
| MX (1) | MX2010001571A (en) |
| WO (1) | WO2009021674A1 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2419522A2 (en) * | 2009-04-17 | 2012-02-22 | Glen Weiss | Methods and kits to predict therapeutic outcome of tyrosine kinase inhibitors |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108732351A (en) * | 2017-04-20 | 2018-11-02 | 中国科学院上海生命科学研究院 | EPS8L2 is as tubercle and the biomarker of early warning liver cancer in instruction liver |
| CN108732349A (en) * | 2017-04-20 | 2018-11-02 | 中国科学院上海生命科学研究院 | LTA4H is as tubercle and the biomarker of early warning liver cancer in instruction liver |
| CN108732350A (en) * | 2017-04-20 | 2018-11-02 | 中国科学院上海生命科学研究院 | PLA2G6 is as tubercle and the biomarker of early warning liver cancer in instruction liver |
| CN110780072B (en) * | 2019-12-09 | 2021-08-06 | 四川大学华西医院 | Application of APOO autoantibody detection reagent in preparation of lung cancer screening kit |
Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5202231A (en) | 1987-04-01 | 1993-04-13 | Drmanac Radoje T | Method of sequencing of genomes by hybridization of oligonucleotide probes |
| US5445934A (en) | 1989-06-07 | 1995-08-29 | Affymax Technologies N.V. | Array of oligonucleotides on a solid substrate |
| US5525464A (en) | 1987-04-01 | 1996-06-11 | Hyseq, Inc. | Method of sequencing by hybridization of oligonucleotide probes |
| US5744305A (en) | 1989-06-07 | 1998-04-28 | Affymetrix, Inc. | Arrays of materials attached to a substrate |
| US5795716A (en) | 1994-10-21 | 1998-08-18 | Chee; Mark S. | Computer-aided visualization and analysis system for sequence evaluation |
| US5800992A (en) | 1989-06-07 | 1998-09-01 | Fodor; Stephen P.A. | Method of detecting nucleic acids |
| WO2001079556A2 (en) * | 2000-04-14 | 2001-10-25 | Millennium Pharmaceuticals, Inc. | Novel genes, compositions and methods for the identification, assessment, prevention, and therapy of human cancers |
| WO2004071572A2 (en) * | 2003-02-06 | 2004-08-26 | Genomic Health, Inc. | Gene expression markers for response to egfr inhibitor drugs |
| WO2005049829A1 (en) * | 2003-05-30 | 2005-06-02 | Astrazeneca Uk Limited | Process |
| WO2006101925A2 (en) | 2005-03-16 | 2006-09-28 | Osi Pharmaceuticals, Inc. | Biological markers predictive of anti-cancer response to epidermal growth factor receptor kinase inhibitors |
| WO2006119980A1 (en) * | 2005-05-11 | 2006-11-16 | F. Hoffmann-La Roche Ag | Determination of responders to chemotherapy |
| WO2007067500A2 (en) * | 2005-12-05 | 2007-06-14 | Genomic Health, Inc. | Predictors of patient response to treatment with egfr inhibitors |
-
2008
- 2008-08-07 CN CN200880103326A patent/CN101778954A/en active Pending
- 2008-08-07 MX MX2010001571A patent/MX2010001571A/en not_active Application Discontinuation
- 2008-08-07 EP EP08785419A patent/EP2188391A1/en not_active Withdrawn
- 2008-08-07 KR KR1020107003315A patent/KR20100037637A/en not_active Application Discontinuation
- 2008-08-07 BR BRPI0815415-5A2A patent/BRPI0815415A2/en not_active Application Discontinuation
- 2008-08-07 CA CA2695485A patent/CA2695485A1/en not_active Abandoned
- 2008-08-07 AU AU2008286407A patent/AU2008286407A1/en not_active Abandoned
- 2008-08-07 WO PCT/EP2008/006513 patent/WO2009021674A1/en active Application Filing
- 2008-08-07 JP JP2010520464A patent/JP2010535517A/en active Pending
Patent Citations (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5695940A (en) | 1987-04-01 | 1997-12-09 | Hyseq, Inc. | Method of sequencing by hybridization of oligonucleotide probes |
| US5202231A (en) | 1987-04-01 | 1993-04-13 | Drmanac Radoje T | Method of sequencing of genomes by hybridization of oligonucleotide probes |
| US5525464A (en) | 1987-04-01 | 1996-06-11 | Hyseq, Inc. | Method of sequencing by hybridization of oligonucleotide probes |
| US5800992A (en) | 1989-06-07 | 1998-09-01 | Fodor; Stephen P.A. | Method of detecting nucleic acids |
| US5744305A (en) | 1989-06-07 | 1998-04-28 | Affymetrix, Inc. | Arrays of materials attached to a substrate |
| US5445934A (en) | 1989-06-07 | 1995-08-29 | Affymax Technologies N.V. | Array of oligonucleotides on a solid substrate |
| US5795716A (en) | 1994-10-21 | 1998-08-18 | Chee; Mark S. | Computer-aided visualization and analysis system for sequence evaluation |
| WO2001079556A2 (en) * | 2000-04-14 | 2001-10-25 | Millennium Pharmaceuticals, Inc. | Novel genes, compositions and methods for the identification, assessment, prevention, and therapy of human cancers |
| WO2004071572A2 (en) * | 2003-02-06 | 2004-08-26 | Genomic Health, Inc. | Gene expression markers for response to egfr inhibitor drugs |
| WO2005049829A1 (en) * | 2003-05-30 | 2005-06-02 | Astrazeneca Uk Limited | Process |
| WO2006101925A2 (en) | 2005-03-16 | 2006-09-28 | Osi Pharmaceuticals, Inc. | Biological markers predictive of anti-cancer response to epidermal growth factor receptor kinase inhibitors |
| WO2006119980A1 (en) * | 2005-05-11 | 2006-11-16 | F. Hoffmann-La Roche Ag | Determination of responders to chemotherapy |
| WO2007067500A2 (en) * | 2005-12-05 | 2007-06-14 | Genomic Health, Inc. | Predictors of patient response to treatment with egfr inhibitors |
Non-Patent Citations (4)
| Title |
|---|
| IYER VR ET AL., SCIENCE, vol. 283, 1999, pages 83 - 87 |
| JOHNSTON, M. CURR. BIOL., vol. 8, 1998, pages R171 - 174 |
| MING-SOUND TSAO ET AL: "Erlotinib in Lung Cancer Molecular and Clinical Predictors of Outcome", NEW ENGLAND JOURNAL OF MEDICINE, MASSACHUSETTS MEDICAL SOCIETY, BOSTON, MA, US, vol. 353, no. 2, 14 July 2005 (2005-07-14), pages 133 - 145, XP007905868, ISSN: 1533-4406 * |
| SAMBROOK J: "Molecular Cloning A Laboratory Manual, Third Edition", 2000, COLD SPRING HARBOR PRESS |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2419522A2 (en) * | 2009-04-17 | 2012-02-22 | Glen Weiss | Methods and kits to predict therapeutic outcome of tyrosine kinase inhibitors |
| EP2419522A4 (en) * | 2009-04-17 | 2012-10-31 | Glen Weiss | Methods and kits to predict therapeutic outcome of tyrosine kinase inhibitors |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2010535517A (en) | 2010-11-25 |
| AU2008286407A1 (en) | 2009-02-19 |
| KR20100037637A (en) | 2010-04-09 |
| BRPI0815415A2 (en) | 2015-02-03 |
| EP2188391A1 (en) | 2010-05-26 |
| MX2010001571A (en) | 2010-03-15 |
| CA2695485A1 (en) | 2009-02-19 |
| CN101778954A (en) | 2010-07-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP2188391A1 (en) | Predictive markers for egfr inhibitor treatment | |
| US20110218212A1 (en) | Predictive markers for egfr inhibitors treatment | |
| AU2008286335B2 (en) | Predictive marker for EGFR inhibitor treatment | |
| US20110245279A1 (en) | Predictive marker for egfr inhibitor treatment | |
| US9121067B2 (en) | Predictive marker for EGFR inhibitor treatment | |
| EP2179056A2 (en) | Egfr inhibitor treatment marker | |
| US20110312981A1 (en) | Predictive marker for egfr inhibitor treatment | |
| US20110184004A1 (en) | Predictive marker for egfr inhibitor treatment | |
| WO2009021680A1 (en) | Predictive marker for egfr inhibitor treatment | |
| US20110190321A1 (en) | Predictive marker for egfr inhibitor treatment | |
| EP2176429A1 (en) | Predictive marker for egfr inhibitor treamtent |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WWE | Wipo information: entry into national phase |
Ref document number: 200880103326.X Country of ref document: CN |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 08785419 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2008785419 Country of ref document: EP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2008286407 Country of ref document: AU |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 203648 Country of ref document: IL |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2695485 Country of ref document: CA |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 233/MUMNP/2010 Country of ref document: IN |
|
| WWE | Wipo information: entry into national phase |
Ref document number: MX/A/2010/001571 Country of ref document: MX |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2010520464 Country of ref document: JP |
|
| ENP | Entry into the national phase |
Ref document number: 20107003315 Country of ref document: KR Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2008286407 Country of ref document: AU Date of ref document: 20080807 Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 12672946 Country of ref document: US |
|
| ENP | Entry into the national phase |
Ref document number: PI0815415 Country of ref document: BR Kind code of ref document: A2 Effective date: 20100212 |