WO2004103275A2 - Compositions and methods for the preparation of human growth hormone glycosylation mutants - Google Patents
Compositions and methods for the preparation of human growth hormone glycosylation mutants Download PDFInfo
- Publication number
- WO2004103275A2 WO2004103275A2 PCT/US2004/014254 US2004014254W WO2004103275A2 WO 2004103275 A2 WO2004103275 A2 WO 2004103275A2 US 2004014254 W US2004014254 W US 2004014254W WO 2004103275 A2 WO2004103275 A2 WO 2004103275A2
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- growth hormone
- human growth
- seq
- ofthe
- mutant human
- Prior art date
Links
- 108010000521 Human Growth Hormone Proteins 0.000 title claims abstract description 301
- 102000002265 Human Growth Hormone Human genes 0.000 title claims abstract description 300
- 239000000854 Human Growth Hormone Substances 0.000 title claims abstract description 291
- 238000000034 method Methods 0.000 title claims abstract description 213
- 230000013595 glycosylation Effects 0.000 title claims abstract description 63
- 238000006206 glycosylation reaction Methods 0.000 title claims abstract description 62
- 239000000203 mixture Substances 0.000 title claims description 29
- 238000002360 preparation method Methods 0.000 title description 10
- 230000014509 gene expression Effects 0.000 claims abstract description 47
- 230000004989 O-glycosylation Effects 0.000 claims abstract description 38
- 230000004988 N-glycosylation Effects 0.000 claims abstract description 30
- 108091033319 polynucleotide Proteins 0.000 claims abstract description 27
- 102000040430 polynucleotide Human genes 0.000 claims abstract description 27
- 239000002157 polynucleotide Substances 0.000 claims abstract description 27
- 239000008194 pharmaceutical composition Substances 0.000 claims abstract description 9
- 235000000346 sugar Nutrition 0.000 claims description 182
- -1 poly(ethylene glycol) Polymers 0.000 claims description 175
- 229920001223 polyethylene glycol Polymers 0.000 claims description 110
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 78
- 150000007523 nucleic acids Chemical class 0.000 claims description 57
- 102000039446 nucleic acids Human genes 0.000 claims description 46
- 108020004707 nucleic acids Proteins 0.000 claims description 46
- 229920003169 water-soluble polymer Polymers 0.000 claims description 39
- 125000001500 prolyl group Chemical group [H]N1C([H])(C(=O)[*])C([H])([H])C([H])([H])C1([H])[H] 0.000 claims description 17
- 206010056438 Growth hormone deficiency Diseases 0.000 claims description 4
- 230000001279 glycosylating effect Effects 0.000 claims description 4
- 108090000765 processed proteins & peptides Proteins 0.000 abstract description 250
- 102000004196 processed proteins & peptides Human genes 0.000 abstract description 91
- 229920001184 polypeptide Polymers 0.000 abstract description 41
- 108090000623 proteins and genes Proteins 0.000 description 148
- 102000004169 proteins and genes Human genes 0.000 description 117
- 235000018102 proteins Nutrition 0.000 description 95
- 125000003147 glycosyl group Chemical group 0.000 description 84
- 108700023372 Glycosyltransferases Proteins 0.000 description 81
- 125000005647 linker group Chemical group 0.000 description 77
- 210000004027 cell Anatomy 0.000 description 75
- 229940088598 enzyme Drugs 0.000 description 73
- 235000001014 amino acid Nutrition 0.000 description 72
- 102000004190 Enzymes Human genes 0.000 description 71
- 108090000790 Enzymes Proteins 0.000 description 71
- 229940024606 amino acid Drugs 0.000 description 68
- 150000001413 amino acids Chemical class 0.000 description 67
- 239000000562 conjugate Substances 0.000 description 67
- 239000002202 Polyethylene glycol Substances 0.000 description 62
- 108010015899 Glycopeptides Proteins 0.000 description 57
- 102000002068 Glycopeptides Human genes 0.000 description 57
- 230000001225 therapeutic effect Effects 0.000 description 50
- 238000006243 chemical reaction Methods 0.000 description 46
- 239000000126 substance Substances 0.000 description 42
- 239000000370 acceptor Substances 0.000 description 41
- 108700014210 glycosyltransferase activity proteins Proteins 0.000 description 40
- 239000003814 drug Substances 0.000 description 37
- 102000045442 glycosyltransferase activity proteins Human genes 0.000 description 37
- 230000015572 biosynthetic process Effects 0.000 description 36
- 239000003795 chemical substances by application Substances 0.000 description 36
- 102000051366 Glycosyltransferases Human genes 0.000 description 35
- 150000001720 carbohydrates Chemical class 0.000 description 34
- 229920001451 polypropylene glycol Polymers 0.000 description 33
- 238000003786 synthesis reaction Methods 0.000 description 33
- 229920000642 polymer Polymers 0.000 description 32
- DQJCDTNMLBYVAY-ZXXIYAEKSA-N (2S,5R,10R,13R)-16-{[(2R,3S,4R,5R)-3-{[(2S,3R,4R,5S,6R)-3-acetamido-4,5-dihydroxy-6-(hydroxymethyl)oxan-2-yl]oxy}-5-(ethylamino)-6-hydroxy-2-(hydroxymethyl)oxan-4-yl]oxy}-5-(4-aminobutyl)-10-carbamoyl-2,13-dimethyl-4,7,12,15-tetraoxo-3,6,11,14-tetraazaheptadecan-1-oic acid Chemical compound NCCCC[C@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)CC[C@H](C(N)=O)NC(=O)[C@@H](C)NC(=O)C(C)O[C@@H]1[C@@H](NCC)C(O)O[C@H](CO)[C@H]1O[C@H]1[C@H](NC(C)=O)[C@@H](O)[C@H](O)[C@@H](CO)O1 DQJCDTNMLBYVAY-ZXXIYAEKSA-N 0.000 description 31
- 102000003838 Sialyltransferases Human genes 0.000 description 30
- 108090000141 Sialyltransferases Proteins 0.000 description 30
- 239000003153 chemical reaction reagent Substances 0.000 description 30
- 239000002773 nucleotide Substances 0.000 description 30
- SQVRNKJHWKZAKO-OQPLDHBCSA-N sialic acid Chemical compound CC(=O)N[C@@H]1[C@@H](O)C[C@@](O)(C(O)=O)OC1[C@H](O)[C@H](O)CO SQVRNKJHWKZAKO-OQPLDHBCSA-N 0.000 description 30
- 150000008163 sugars Chemical class 0.000 description 30
- 229940079593 drug Drugs 0.000 description 29
- 150000002482 oligosaccharides Polymers 0.000 description 29
- 125000003729 nucleotide group Chemical group 0.000 description 28
- 108010031186 Glycoside Hydrolases Proteins 0.000 description 27
- 102000005744 Glycoside Hydrolases Human genes 0.000 description 27
- 239000000758 substrate Substances 0.000 description 25
- 125000003396 thiol group Chemical group [H]S* 0.000 description 24
- 108020004414 DNA Proteins 0.000 description 23
- 238000007792 addition Methods 0.000 description 23
- SQVRNKJHWKZAKO-UHFFFAOYSA-N beta-N-Acetyl-D-neuraminic acid Natural products CC(=O)NC1C(O)CC(O)(C(O)=O)OC1C(O)C(O)CO SQVRNKJHWKZAKO-UHFFFAOYSA-N 0.000 description 22
- 150000001412 amines Chemical class 0.000 description 21
- 230000002255 enzymatic effect Effects 0.000 description 21
- 230000000670 limiting effect Effects 0.000 description 21
- 125000000539 amino acid group Chemical group 0.000 description 20
- 125000000837 carbohydrate group Chemical group 0.000 description 20
- 230000004048 modification Effects 0.000 description 20
- 238000012986 modification Methods 0.000 description 20
- 229920001542 oligosaccharide Polymers 0.000 description 20
- 241000894007 species Species 0.000 description 20
- 239000013598 vector Substances 0.000 description 20
- OVRNDRQMDRJTHS-KEWYIRBNSA-N N-acetyl-D-galactosamine Chemical compound CC(=O)N[C@H]1C(O)O[C@H](CO)[C@H](O)[C@@H]1O OVRNDRQMDRJTHS-KEWYIRBNSA-N 0.000 description 19
- MBLBDJOUHNCFQT-UHFFFAOYSA-N N-acetyl-D-galactosamine Chemical group CC(=O)NC(C=O)C(O)C(O)C(O)CO MBLBDJOUHNCFQT-UHFFFAOYSA-N 0.000 description 19
- 238000000746 purification Methods 0.000 description 19
- 210000001519 tissue Anatomy 0.000 description 19
- 108010019236 Fucosyltransferases Proteins 0.000 description 18
- 102000006471 Fucosyltransferases Human genes 0.000 description 18
- 235000014633 carbohydrates Nutrition 0.000 description 18
- 230000035772 mutation Effects 0.000 description 18
- 239000004971 Cross linker Substances 0.000 description 17
- 230000021615 conjugation Effects 0.000 description 17
- 239000000122 growth hormone Substances 0.000 description 17
- 239000000863 peptide conjugate Substances 0.000 description 17
- 238000012546 transfer Methods 0.000 description 17
- 239000002299 complementary DNA Substances 0.000 description 16
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 15
- 241000588724 Escherichia coli Species 0.000 description 15
- 125000003277 amino group Chemical group 0.000 description 15
- 239000000523 sample Substances 0.000 description 15
- 230000008685 targeting Effects 0.000 description 15
- 102000018997 Growth Hormone Human genes 0.000 description 14
- 108010051696 Growth Hormone Proteins 0.000 description 14
- OVRNDRQMDRJTHS-RTRLPJTCSA-N N-acetyl-D-glucosamine Chemical group CC(=O)N[C@H]1C(O)O[C@H](CO)[C@@H](O)[C@@H]1O OVRNDRQMDRJTHS-RTRLPJTCSA-N 0.000 description 14
- 238000003556 assay Methods 0.000 description 14
- 210000004369 blood Anatomy 0.000 description 14
- 239000008280 blood Substances 0.000 description 14
- 150000004676 glycans Chemical class 0.000 description 14
- 230000001817 pituitary effect Effects 0.000 description 14
- 238000006467 substitution reaction Methods 0.000 description 14
- 108060003306 Galactosyltransferase Proteins 0.000 description 13
- 102000030902 Galactosyltransferase Human genes 0.000 description 13
- 108091028043 Nucleic acid sequence Proteins 0.000 description 13
- 239000002253 acid Substances 0.000 description 13
- WQZGKKKJIJFFOK-PHYPRBDBSA-N alpha-D-galactose Chemical compound OC[C@H]1O[C@H](O)[C@H](O)[C@@H](O)[C@H]1O WQZGKKKJIJFFOK-PHYPRBDBSA-N 0.000 description 13
- 239000003431 cross linking reagent Substances 0.000 description 13
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 13
- 239000000386 donor Substances 0.000 description 13
- 239000013604 expression vector Substances 0.000 description 13
- 238000004519 manufacturing process Methods 0.000 description 13
- 108020004705 Codon Proteins 0.000 description 12
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 12
- 102000003886 Glycoproteins Human genes 0.000 description 12
- 108090000288 Glycoproteins Proteins 0.000 description 12
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 12
- OVRNDRQMDRJTHS-UHFFFAOYSA-N N-acelyl-D-glucosamine Natural products CC(=O)NC1C(O)OC(CO)C(O)C1O OVRNDRQMDRJTHS-UHFFFAOYSA-N 0.000 description 12
- MBLBDJOUHNCFQT-LXGUWJNJSA-N N-acetylglucosamine Natural products CC(=O)N[C@@H](C=O)[C@@H](O)[C@H](O)[C@H](O)CO MBLBDJOUHNCFQT-LXGUWJNJSA-N 0.000 description 12
- 206010028980 Neoplasm Diseases 0.000 description 12
- 102000004357 Transferases Human genes 0.000 description 12
- 108090000992 Transferases Proteins 0.000 description 12
- WQZGKKKJIJFFOK-FPRJBGLDSA-N beta-D-galactose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@H]1O WQZGKKKJIJFFOK-FPRJBGLDSA-N 0.000 description 12
- 201000010099 disease Diseases 0.000 description 12
- 238000003752 polymerase chain reaction Methods 0.000 description 12
- 150000003141 primary amines Chemical class 0.000 description 12
- 108091026890 Coding region Proteins 0.000 description 11
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 11
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 11
- 150000001299 aldehydes Chemical class 0.000 description 11
- 239000000427 antigen Substances 0.000 description 11
- 108091007433 antigens Proteins 0.000 description 11
- 102000036639 antigens Human genes 0.000 description 11
- 150000001875 compounds Chemical class 0.000 description 11
- 230000000694 effects Effects 0.000 description 11
- 229930182470 glycoside Natural products 0.000 description 11
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 11
- 238000012552 review Methods 0.000 description 11
- 241000894006 Bacteria Species 0.000 description 10
- 241000238631 Hexapoda Species 0.000 description 10
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 10
- 238000004132 cross linking Methods 0.000 description 10
- 125000000524 functional group Chemical group 0.000 description 10
- 238000003018 immunoassay Methods 0.000 description 10
- 238000001727 in vivo Methods 0.000 description 10
- 238000002703 mutagenesis Methods 0.000 description 10
- 231100000350 mutagenesis Toxicity 0.000 description 10
- 239000000047 product Substances 0.000 description 10
- 102000005962 receptors Human genes 0.000 description 10
- 108020003175 receptors Proteins 0.000 description 10
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 10
- 108010087568 Mannosyltransferases Proteins 0.000 description 9
- 102000006722 Mannosyltransferases Human genes 0.000 description 9
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 9
- 230000001580 bacterial effect Effects 0.000 description 9
- 230000027455 binding Effects 0.000 description 9
- 150000002338 glycosides Chemical class 0.000 description 9
- 239000005556 hormone Substances 0.000 description 9
- 210000003000 inclusion body Anatomy 0.000 description 9
- 239000012528 membrane Substances 0.000 description 9
- 210000004379 membrane Anatomy 0.000 description 9
- 230000008569 process Effects 0.000 description 9
- 235000004400 serine Nutrition 0.000 description 9
- 108010088751 Albumins Proteins 0.000 description 8
- 102000009027 Albumins Human genes 0.000 description 8
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 8
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 8
- 241001465754 Metazoa Species 0.000 description 8
- 238000013459 approach Methods 0.000 description 8
- 238000004587 chromatography analysis Methods 0.000 description 8
- 239000012634 fragment Substances 0.000 description 8
- 102000037865 fusion proteins Human genes 0.000 description 8
- 108020001507 fusion proteins Proteins 0.000 description 8
- 229940088597 hormone Drugs 0.000 description 8
- 230000001976 improved effect Effects 0.000 description 8
- 239000012071 phase Substances 0.000 description 8
- 235000002639 sodium chloride Nutrition 0.000 description 8
- 238000011282 treatment Methods 0.000 description 8
- JWDFQMWEFLOOED-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 3-(pyridin-2-yldisulfanyl)propanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCSSC1=CC=CC=N1 JWDFQMWEFLOOED-UHFFFAOYSA-N 0.000 description 7
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 7
- 108700010070 Codon Usage Proteins 0.000 description 7
- 241000196324 Embryophyta Species 0.000 description 7
- SHZGCJCMOBCMKK-DHVFOXMCSA-N L-fucopyranose Chemical group C[C@@H]1OC(O)[C@@H](O)[C@H](O)[C@@H]1O SHZGCJCMOBCMKK-DHVFOXMCSA-N 0.000 description 7
- NQTADLQHYWFPDB-UHFFFAOYSA-N N-Hydroxysuccinimide Chemical compound ON1C(=O)CCC1=O NQTADLQHYWFPDB-UHFFFAOYSA-N 0.000 description 7
- 229920002684 Sepharose Polymers 0.000 description 7
- 150000001350 alkyl halides Chemical class 0.000 description 7
- 235000009582 asparagine Nutrition 0.000 description 7
- 229960001230 asparagine Drugs 0.000 description 7
- 239000002585 base Substances 0.000 description 7
- 239000000872 buffer Substances 0.000 description 7
- 230000006870 function Effects 0.000 description 7
- 239000003446 ligand Substances 0.000 description 7
- 229910052760 oxygen Inorganic materials 0.000 description 7
- 230000002829 reductive effect Effects 0.000 description 7
- 125000000341 threoninyl group Chemical group [H]OC([H])(C([H])([H])[H])C([H])(N([H])[H])C(*)=O 0.000 description 7
- 102100029962 CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase Human genes 0.000 description 6
- SHZGCJCMOBCMKK-UHFFFAOYSA-N D-mannomethylose Chemical group CC1OC(O)C(O)C(O)C1O SHZGCJCMOBCMKK-UHFFFAOYSA-N 0.000 description 6
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 6
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 6
- 108010076504 Protein Sorting Signals Proteins 0.000 description 6
- 102000004338 Transferrin Human genes 0.000 description 6
- 108090000901 Transferrin Proteins 0.000 description 6
- 230000009471 action Effects 0.000 description 6
- 230000004913 activation Effects 0.000 description 6
- BFNBIHQBYMNNAN-UHFFFAOYSA-N ammonium sulfate Chemical group N.N.OS(O)(=O)=O BFNBIHQBYMNNAN-UHFFFAOYSA-N 0.000 description 6
- 108010057005 beta-galactoside alpha-2,3-sialyltransferase Proteins 0.000 description 6
- 210000004556 brain Anatomy 0.000 description 6
- 201000011510 cancer Diseases 0.000 description 6
- 230000003197 catalytic effect Effects 0.000 description 6
- 230000001268 conjugating effect Effects 0.000 description 6
- 238000006911 enzymatic reaction Methods 0.000 description 6
- 150000002148 esters Chemical class 0.000 description 6
- 210000003527 eukaryotic cell Anatomy 0.000 description 6
- 230000004927 fusion Effects 0.000 description 6
- 229930182830 galactose Natural products 0.000 description 6
- 230000002163 immunogen Effects 0.000 description 6
- 230000005847 immunogenicity Effects 0.000 description 6
- 238000010324 immunological assay Methods 0.000 description 6
- 239000000463 material Substances 0.000 description 6
- 108020004999 messenger RNA Proteins 0.000 description 6
- 108091005601 modified peptides Proteins 0.000 description 6
- 230000000269 nucleophilic effect Effects 0.000 description 6
- 230000006320 pegylation Effects 0.000 description 6
- 238000006303 photolysis reaction Methods 0.000 description 6
- 230000015843 photosynthesis, light reaction Effects 0.000 description 6
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 6
- 230000002285 radioactive effect Effects 0.000 description 6
- 238000012216 screening Methods 0.000 description 6
- 125000005629 sialic acid group Chemical group 0.000 description 6
- 239000007787 solid Substances 0.000 description 6
- 239000002904 solvent Substances 0.000 description 6
- 239000012581 transferrin Substances 0.000 description 6
- TXCIAUNLDRJGJZ-UHFFFAOYSA-N CMP-N-acetyl neuraminic acid Natural products O1C(C(O)C(O)CO)C(NC(=O)C)C(O)CC1(C(O)=O)OP(O)(=O)OCC1C(O)C(O)C(N2C(N=C(N)C=C2)=O)O1 TXCIAUNLDRJGJZ-UHFFFAOYSA-N 0.000 description 5
- TXCIAUNLDRJGJZ-BILDWYJOSA-N CMP-N-acetyl-beta-neuraminic acid Chemical compound O1[C@@H]([C@H](O)[C@H](O)CO)[C@H](NC(=O)C)[C@@H](O)C[C@]1(C(O)=O)OP(O)(=O)OC[C@@H]1[C@@H](O)[C@@H](O)[C@H](N2C(N=C(N)C=C2)=O)O1 TXCIAUNLDRJGJZ-BILDWYJOSA-N 0.000 description 5
- WQZGKKKJIJFFOK-QTVWNMPRSA-N D-mannopyranose Chemical group OC[C@H]1OC(O)[C@@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-QTVWNMPRSA-N 0.000 description 5
- KRHYYFGTRYWZRS-UHFFFAOYSA-M Fluoride anion Chemical compound [F-] KRHYYFGTRYWZRS-UHFFFAOYSA-M 0.000 description 5
- SXRSQZLOMIGNAQ-UHFFFAOYSA-N Glutaraldehyde Chemical compound O=CCCCC=O SXRSQZLOMIGNAQ-UHFFFAOYSA-N 0.000 description 5
- 102000004269 Granulocyte Colony-Stimulating Factor Human genes 0.000 description 5
- 108010017080 Granulocyte Colony-Stimulating Factor Proteins 0.000 description 5
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 5
- 241001529936 Murinae Species 0.000 description 5
- 102000007524 N-Acetylgalactosaminyltransferases Human genes 0.000 description 5
- 108010046220 N-Acetylgalactosaminyltransferases Proteins 0.000 description 5
- 241000588650 Neisseria meningitidis Species 0.000 description 5
- 108091034117 Oligonucleotide Proteins 0.000 description 5
- 108010066816 Polypeptide N-acetylgalactosaminyltransferase Proteins 0.000 description 5
- 241000700159 Rattus Species 0.000 description 5
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 5
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 5
- 239000004473 Threonine Substances 0.000 description 5
- 229910052770 Uranium Inorganic materials 0.000 description 5
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 5
- 150000007513 acids Chemical class 0.000 description 5
- 125000000217 alkyl group Chemical group 0.000 description 5
- 229910052921 ammonium sulfate Inorganic materials 0.000 description 5
- 235000011130 ammonium sulphate Nutrition 0.000 description 5
- 125000003118 aryl group Chemical group 0.000 description 5
- 230000001588 bifunctional effect Effects 0.000 description 5
- 230000004071 biological effect Effects 0.000 description 5
- IERHLVCPSMICTF-XVFCMESISA-N cytidine 5'-monophosphate Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](COP(O)(O)=O)O1 IERHLVCPSMICTF-XVFCMESISA-N 0.000 description 5
- 230000007812 deficiency Effects 0.000 description 5
- 230000002950 deficient Effects 0.000 description 5
- 238000001212 derivatisation Methods 0.000 description 5
- 239000003599 detergent Substances 0.000 description 5
- 238000012377 drug delivery Methods 0.000 description 5
- 229960000587 glutaral Drugs 0.000 description 5
- 230000012010 growth Effects 0.000 description 5
- 229910052739 hydrogen Inorganic materials 0.000 description 5
- 230000002209 hydrophobic effect Effects 0.000 description 5
- 238000002372 labelling Methods 0.000 description 5
- 125000005439 maleimidyl group Chemical group C1(C=CC(N1*)=O)=O 0.000 description 5
- 210000004962 mammalian cell Anatomy 0.000 description 5
- 239000008188 pellet Substances 0.000 description 5
- 210000001322 periplasm Anatomy 0.000 description 5
- 229920000570 polyether Polymers 0.000 description 5
- 239000002244 precipitate Substances 0.000 description 5
- 210000001236 prokaryotic cell Anatomy 0.000 description 5
- 238000001742 protein purification Methods 0.000 description 5
- 239000011541 reaction mixture Substances 0.000 description 5
- 229920002477 rna polymer Polymers 0.000 description 5
- 150000003839 salts Chemical class 0.000 description 5
- 238000000926 separation method Methods 0.000 description 5
- 239000003053 toxin Substances 0.000 description 5
- 231100000765 toxin Toxicity 0.000 description 5
- 108700012359 toxins Proteins 0.000 description 5
- 238000013518 transcription Methods 0.000 description 5
- 230000035897 transcription Effects 0.000 description 5
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 5
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 4
- 241000283690 Bos taurus Species 0.000 description 4
- 102000003951 Erythropoietin Human genes 0.000 description 4
- 108090000394 Erythropoietin Proteins 0.000 description 4
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 4
- PNNNRSAQSRJVSB-SLPGGIOYSA-N Fucose Chemical group C[C@H](O)[C@@H](O)[C@H](O)[C@H](O)C=O PNNNRSAQSRJVSB-SLPGGIOYSA-N 0.000 description 4
- LQEBEXMHBLQMDB-UHFFFAOYSA-N GDP-L-fucose Natural products OC1C(O)C(O)C(C)OC1OP(O)(=O)OP(O)(=O)OCC1C(O)C(O)C(N2C3=C(C(N=C(N)N3)=O)N=C2)O1 LQEBEXMHBLQMDB-UHFFFAOYSA-N 0.000 description 4
- 108010055629 Glucosyltransferases Proteins 0.000 description 4
- 102000000340 Glucosyltransferases Human genes 0.000 description 4
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 4
- 102000004457 Granulocyte-Macrophage Colony-Stimulating Factor Human genes 0.000 description 4
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 description 4
- 229920002971 Heparan sulfate Polymers 0.000 description 4
- 108010002350 Interleukin-2 Proteins 0.000 description 4
- 102000000588 Interleukin-2 Human genes 0.000 description 4
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 4
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 4
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical group CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 4
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 4
- 239000004472 Lysine Substances 0.000 description 4
- OVRNDRQMDRJTHS-FMDGEEDCSA-N N-acetyl-beta-D-glucosamine Chemical group CC(=O)N[C@H]1[C@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O OVRNDRQMDRJTHS-FMDGEEDCSA-N 0.000 description 4
- 108091005461 Nucleic proteins Proteins 0.000 description 4
- 241000276498 Pollachius virens Species 0.000 description 4
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 4
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 4
- 241000293869 Salmonella enterica subsp. enterica serovar Typhimurium Species 0.000 description 4
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 4
- 235000004279 alanine Nutrition 0.000 description 4
- 239000002246 antineoplastic agent Substances 0.000 description 4
- 229940041181 antineoplastic drug Drugs 0.000 description 4
- 239000000969 carrier Substances 0.000 description 4
- 238000010367 cloning Methods 0.000 description 4
- 231100000599 cytotoxic agent Toxicity 0.000 description 4
- 230000007423 decrease Effects 0.000 description 4
- 238000005516 engineering process Methods 0.000 description 4
- 229940105423 erythropoietin Drugs 0.000 description 4
- 229940093476 ethylene glycol Drugs 0.000 description 4
- 238000005194 fractionation Methods 0.000 description 4
- 125000002519 galactosyl group Chemical group C1([C@H](O)[C@@H](O)[C@@H](O)[C@H](O1)CO)* 0.000 description 4
- 238000001502 gel electrophoresis Methods 0.000 description 4
- 230000002068 genetic effect Effects 0.000 description 4
- 239000000348 glycosyl donor Substances 0.000 description 4
- 229920000669 heparin Polymers 0.000 description 4
- 229960002897 heparin Drugs 0.000 description 4
- 230000007062 hydrolysis Effects 0.000 description 4
- 238000006460 hydrolysis reaction Methods 0.000 description 4
- 150000002463 imidates Chemical class 0.000 description 4
- 238000000338 in vitro Methods 0.000 description 4
- 238000010348 incorporation Methods 0.000 description 4
- 238000003780 insertion Methods 0.000 description 4
- 230000037431 insertion Effects 0.000 description 4
- 230000003993 interaction Effects 0.000 description 4
- 125000000311 mannosyl group Chemical group C1([C@@H](O)[C@@H](O)[C@H](O)[C@H](O1)CO)* 0.000 description 4
- 239000011159 matrix material Substances 0.000 description 4
- MYWUZJCMWCOHBA-VIFPVBQESA-N methamphetamine Chemical compound CN[C@@H](C)CC1=CC=CC=C1 MYWUZJCMWCOHBA-VIFPVBQESA-N 0.000 description 4
- 229930182817 methionine Chemical group 0.000 description 4
- 239000003068 molecular probe Substances 0.000 description 4
- 210000000865 mononuclear phagocyte system Anatomy 0.000 description 4
- 150000002772 monosaccharides Chemical class 0.000 description 4
- 229950006780 n-acetylglucosamine Drugs 0.000 description 4
- KHIWWQKSHDUIBK-UHFFFAOYSA-N periodic acid Chemical compound OI(=O)(=O)=O KHIWWQKSHDUIBK-UHFFFAOYSA-N 0.000 description 4
- 239000013612 plasmid Substances 0.000 description 4
- 229920001282 polysaccharide Polymers 0.000 description 4
- OXCMYAYHXIHQOA-UHFFFAOYSA-N potassium;[2-butyl-5-chloro-3-[[4-[2-(1,2,4-triaza-3-azanidacyclopenta-1,4-dien-5-yl)phenyl]phenyl]methyl]imidazol-4-yl]methanol Chemical compound [K+].CCCCC1=NC(Cl)=C(CO)N1CC1=CC=C(C=2C(=CC=CC=2)C2=N[N-]N=N2)C=C1 OXCMYAYHXIHQOA-UHFFFAOYSA-N 0.000 description 4
- 230000009257 reactivity Effects 0.000 description 4
- 238000004007 reversed phase HPLC Methods 0.000 description 4
- 230000028327 secretion Effects 0.000 description 4
- 230000009450 sialylation Effects 0.000 description 4
- 238000002741 site-directed mutagenesis Methods 0.000 description 4
- 238000010561 standard procedure Methods 0.000 description 4
- 239000006228 supernatant Substances 0.000 description 4
- 229920001059 synthetic polymer Polymers 0.000 description 4
- 238000012360 testing method Methods 0.000 description 4
- 229940124597 therapeutic agent Drugs 0.000 description 4
- 238000009966 trimming Methods 0.000 description 4
- 150000003923 2,5-pyrrolediones Chemical class 0.000 description 3
- NITXODYAMWZEJY-UHFFFAOYSA-N 3-(pyridin-2-yldisulfanyl)propanehydrazide Chemical compound NNC(=O)CCSSC1=CC=CC=N1 NITXODYAMWZEJY-UHFFFAOYSA-N 0.000 description 3
- HRPVXLWXLXDGHG-UHFFFAOYSA-N Acrylamide Chemical compound NC(=O)C=C HRPVXLWXLXDGHG-UHFFFAOYSA-N 0.000 description 3
- 102100029945 Beta-galactoside alpha-2,6-sialyltransferase 1 Human genes 0.000 description 3
- 102000004506 Blood Proteins Human genes 0.000 description 3
- 108010017384 Blood Proteins Proteins 0.000 description 3
- 108090000204 Dipeptidase 1 Proteins 0.000 description 3
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 3
- WSFSSNUMVMOOMR-UHFFFAOYSA-N Formaldehyde Chemical compound O=C WSFSSNUMVMOOMR-UHFFFAOYSA-N 0.000 description 3
- LQEBEXMHBLQMDB-JGQUBWHWSA-N GDP-beta-L-fucose Chemical compound O[C@H]1[C@H](O)[C@H](O)[C@H](C)O[C@@H]1OP(O)(=O)OP(O)(=O)OC[C@@H]1[C@@H](O)[C@@H](O)[C@H](N2C3=C(C(NC(N)=N3)=O)N=C2)O1 LQEBEXMHBLQMDB-JGQUBWHWSA-N 0.000 description 3
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 3
- HTTJABKRGRZYRN-UHFFFAOYSA-N Heparin Chemical compound OC1C(NC(=O)C)C(O)OC(COS(O)(=O)=O)C1OC1C(OS(O)(=O)=O)C(O)C(OC2C(C(OS(O)(=O)=O)C(OC3C(C(O)C(O)C(O3)C(O)=O)OS(O)(=O)=O)C(CO)O2)NS(O)(=O)=O)C(C(O)=O)O1 HTTJABKRGRZYRN-UHFFFAOYSA-N 0.000 description 3
- 108091092195 Intron Proteins 0.000 description 3
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 3
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 3
- OVRNDRQMDRJTHS-CBQIKETKSA-N N-Acetyl-D-Galactosamine Chemical group CC(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@H](O)[C@@H]1O OVRNDRQMDRJTHS-CBQIKETKSA-N 0.000 description 3
- 102000002493 N-Acetylglucosaminyltransferases Human genes 0.000 description 3
- 108010093077 N-Acetylglucosaminyltransferases Proteins 0.000 description 3
- 108010046068 N-Acetyllactosamine Synthase Proteins 0.000 description 3
- 241000588652 Neisseria gonorrhoeae Species 0.000 description 3
- 108010071384 Peptide T Proteins 0.000 description 3
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 3
- 239000002262 Schiff base Substances 0.000 description 3
- 150000004753 Schiff bases Chemical class 0.000 description 3
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 3
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 3
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 3
- HSCJRCZFDFQWRP-ABVWGUQPSA-N UDP-alpha-D-galactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@@H]1OP(O)(=O)OP(O)(=O)OC[C@@H]1[C@@H](O)[C@@H](O)[C@H](N2C(NC(=O)C=C2)=O)O1 HSCJRCZFDFQWRP-ABVWGUQPSA-N 0.000 description 3
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 description 3
- HSCJRCZFDFQWRP-UHFFFAOYSA-N Uridindiphosphoglukose Natural products OC1C(O)C(O)C(CO)OC1OP(O)(=O)OP(O)(=O)OCC1C(O)C(O)C(N2C(NC(=O)C=C2)=O)O1 HSCJRCZFDFQWRP-UHFFFAOYSA-N 0.000 description 3
- MZVQCMJNVPIDEA-UHFFFAOYSA-N [CH2]CN(CC)CC Chemical group [CH2]CN(CC)CC MZVQCMJNVPIDEA-UHFFFAOYSA-N 0.000 description 3
- 125000002777 acetyl group Chemical group [H]C([H])([H])C(*)=O 0.000 description 3
- 230000003213 activating effect Effects 0.000 description 3
- 150000001266 acyl halides Chemical class 0.000 description 3
- NIGUVXFURDGQKZ-UQTBNESHSA-N alpha-Neup5Ac-(2->3)-beta-D-Galp-(1->4)-[alpha-L-Fucp-(1->3)]-beta-D-GlcpNAc Chemical compound O[C@H]1[C@H](O)[C@H](O)[C@H](C)O[C@H]1O[C@H]1[C@H](O[C@H]2[C@@H]([C@@H](O[C@]3(O[C@H]([C@H](NC(C)=O)[C@@H](O)C3)[C@H](O)[C@H](O)CO)C(O)=O)[C@@H](O)[C@@H](CO)O2)O)[C@@H](CO)O[C@@H](O)[C@@H]1NC(C)=O NIGUVXFURDGQKZ-UQTBNESHSA-N 0.000 description 3
- 238000004458 analytical method Methods 0.000 description 3
- 239000003242 anti bacterial agent Substances 0.000 description 3
- 229940088710 antibiotic agent Drugs 0.000 description 3
- 230000000890 antigenic effect Effects 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- IEQCXFNWPAHHQR-YKLSGRGUSA-N beta-D-Gal-(1->4)-beta-D-GlcNAc-(1->3)-beta-D-Gal-(1->4)-D-Glc Chemical compound O([C@H]1[C@H](O)[C@H]([C@@H](O[C@@H]1CO)O[C@@H]1[C@H]([C@H](O[C@@H]2[C@H](OC(O)[C@H](O)[C@H]2O)CO)O[C@H](CO)[C@@H]1O)O)NC(=O)C)[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O IEQCXFNWPAHHQR-YKLSGRGUSA-N 0.000 description 3
- 108010064886 beta-D-galactoside alpha 2-6-sialyltransferase Proteins 0.000 description 3
- 102000006635 beta-lactamase Human genes 0.000 description 3
- 230000003115 biocidal effect Effects 0.000 description 3
- 210000000988 bone and bone Anatomy 0.000 description 3
- 150000001718 carbodiimides Chemical class 0.000 description 3
- 229910052799 carbon Inorganic materials 0.000 description 3
- 239000006285 cell suspension Substances 0.000 description 3
- 230000001413 cellular effect Effects 0.000 description 3
- 239000007795 chemical reaction product Substances 0.000 description 3
- 238000003776 cleavage reaction Methods 0.000 description 3
- 239000002619 cytotoxin Substances 0.000 description 3
- 238000012217 deletion Methods 0.000 description 3
- 230000037430 deletion Effects 0.000 description 3
- 230000001419 dependent effect Effects 0.000 description 3
- 238000001514 detection method Methods 0.000 description 3
- 238000011161 development Methods 0.000 description 3
- 230000018109 developmental process Effects 0.000 description 3
- 238000000502 dialysis Methods 0.000 description 3
- 150000002019 disulfides Chemical class 0.000 description 3
- 229960004679 doxorubicin Drugs 0.000 description 3
- CEIPQQODRKXDSB-UHFFFAOYSA-N ethyl 3-(6-hydroxynaphthalen-2-yl)-1H-indazole-5-carboximidate dihydrochloride Chemical compound Cl.Cl.C1=C(O)C=CC2=CC(C3=NNC4=CC=C(C=C43)C(=N)OCC)=CC=C21 CEIPQQODRKXDSB-UHFFFAOYSA-N 0.000 description 3
- 230000033581 fucosylation Effects 0.000 description 3
- 238000007429 general method Methods 0.000 description 3
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 3
- 235000004554 glutamine Nutrition 0.000 description 3
- 238000004128 high performance liquid chromatography Methods 0.000 description 3
- 235000014304 histidine Nutrition 0.000 description 3
- 238000009396 hybridization Methods 0.000 description 3
- 239000001257 hydrogen Substances 0.000 description 3
- RAXXELZNTBOGNW-UHFFFAOYSA-N imidazole Natural products C1=CNC=N1 RAXXELZNTBOGNW-UHFFFAOYSA-N 0.000 description 3
- 125000002883 imidazolyl group Chemical group 0.000 description 3
- 238000002347 injection Methods 0.000 description 3
- 239000007924 injection Substances 0.000 description 3
- 238000001990 intravenous administration Methods 0.000 description 3
- 239000012948 isocyanate Substances 0.000 description 3
- 150000002513 isocyanates Chemical class 0.000 description 3
- 150000002540 isothiocyanates Chemical class 0.000 description 3
- 125000000468 ketone group Chemical group 0.000 description 3
- 239000002502 liposome Substances 0.000 description 3
- 239000003550 marker Substances 0.000 description 3
- 230000007246 mechanism Effects 0.000 description 3
- 230000001404 mediated effect Effects 0.000 description 3
- 229940060155 neuac Drugs 0.000 description 3
- 229910052757 nitrogen Inorganic materials 0.000 description 3
- 229940021182 non-steroidal anti-inflammatory drug Drugs 0.000 description 3
- 229940053934 norethindrone Drugs 0.000 description 3
- VIKNJXKGJWUCNN-XGXHKTLJSA-N norethisterone Chemical compound O=C1CC[C@@H]2[C@H]3CC[C@](C)([C@](CC4)(O)C#C)[C@@H]4[C@@H]3CCC2=C1 VIKNJXKGJWUCNN-XGXHKTLJSA-N 0.000 description 3
- 210000004940 nucleus Anatomy 0.000 description 3
- 125000000636 p-nitrophenyl group Chemical group [H]C1=C([H])C(=C([H])C([H])=C1*)[N+]([O-])=O 0.000 description 3
- 230000003285 pharmacodynamic effect Effects 0.000 description 3
- 230000000144 pharmacologic effect Effects 0.000 description 3
- 230000003169 placental effect Effects 0.000 description 3
- 239000005017 polysaccharide Substances 0.000 description 3
- 239000013615 primer Substances 0.000 description 3
- 230000000069 prophylactic effect Effects 0.000 description 3
- AQHHHDLHHXJYJD-UHFFFAOYSA-N propranolol Chemical compound C1=CC=C2C(OCC(O)CNC(C)C)=CC=CC2=C1 AQHHHDLHHXJYJD-UHFFFAOYSA-N 0.000 description 3
- 230000017854 proteolysis Effects 0.000 description 3
- 230000002441 reversible effect Effects 0.000 description 3
- 230000007017 scission Effects 0.000 description 3
- 238000012163 sequencing technique Methods 0.000 description 3
- 239000011780 sodium chloride Substances 0.000 description 3
- JJAHTWIKCUJRDK-UHFFFAOYSA-N succinimidyl 4-(N-maleimidomethyl)cyclohexane-1-carboxylate Chemical compound C1CC(CN2C(C=CC2=O)=O)CCC1C(=O)ON1C(=O)CCC1=O JJAHTWIKCUJRDK-UHFFFAOYSA-N 0.000 description 3
- 238000013519 translation Methods 0.000 description 3
- 238000000108 ultra-filtration Methods 0.000 description 3
- 241000701447 unidentified baculovirus Species 0.000 description 3
- LLXVXPPXELIDGQ-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 3-(2,5-dioxopyrrol-1-yl)benzoate Chemical compound C=1C=CC(N2C(C=CC2=O)=O)=CC=1C(=O)ON1C(=O)CCC1=O LLXVXPPXELIDGQ-UHFFFAOYSA-N 0.000 description 2
- JKHVDAUOODACDU-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 3-(2,5-dioxopyrrol-1-yl)propanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCN1C(=O)C=CC1=O JKHVDAUOODACDU-UHFFFAOYSA-N 0.000 description 2
- PVGATNRYUYNBHO-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 4-(2,5-dioxopyrrol-1-yl)butanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCCN1C(=O)C=CC1=O PVGATNRYUYNBHO-UHFFFAOYSA-N 0.000 description 2
- BQWBEDSJTMWJAE-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 4-[(2-iodoacetyl)amino]benzoate Chemical compound C1=CC(NC(=O)CI)=CC=C1C(=O)ON1C(=O)CCC1=O BQWBEDSJTMWJAE-UHFFFAOYSA-N 0.000 description 2
- GKSPIZSKQWTXQG-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 4-[1-(pyridin-2-yldisulfanyl)ethyl]benzoate Chemical compound C=1C=C(C(=O)ON2C(CCC2=O)=O)C=CC=1C(C)SSC1=CC=CC=N1 GKSPIZSKQWTXQG-UHFFFAOYSA-N 0.000 description 2
- PMJWDPGOWBRILU-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 4-[4-(2,5-dioxopyrrol-1-yl)phenyl]butanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCCC(C=C1)=CC=C1N1C(=O)C=CC1=O PMJWDPGOWBRILU-UHFFFAOYSA-N 0.000 description 2
- VLARLSIGSPVYHX-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 6-(2,5-dioxopyrrol-1-yl)hexanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCCCCN1C(=O)C=CC1=O VLARLSIGSPVYHX-UHFFFAOYSA-N 0.000 description 2
- QYEAAMBIUQLHFQ-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 6-[3-(pyridin-2-yldisulfanyl)propanoylamino]hexanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCCCCNC(=O)CCSSC1=CC=CC=N1 QYEAAMBIUQLHFQ-UHFFFAOYSA-N 0.000 description 2
- OEANUJAFZLQYOD-CXAZCLJRSA-N (2r,3s,4r,5r,6r)-6-[(2r,3r,4r,5r,6r)-5-acetamido-3-hydroxy-2-(hydroxymethyl)-6-methoxyoxan-4-yl]oxy-4,5-dihydroxy-3-methoxyoxane-2-carboxylic acid Chemical compound CC(=O)N[C@H]1[C@H](OC)O[C@H](CO)[C@H](O)[C@@H]1O[C@H]1[C@H](O)[C@@H](O)[C@H](OC)[C@H](C(O)=O)O1 OEANUJAFZLQYOD-CXAZCLJRSA-N 0.000 description 2
- LAQPKDLYOBZWBT-NYLDSJSYSA-N (2s,4s,5r,6r)-5-acetamido-2-{[(2s,3r,4s,5s,6r)-2-{[(2r,3r,4r,5r)-5-acetamido-1,2-dihydroxy-6-oxo-4-{[(2s,3s,4r,5s,6s)-3,4,5-trihydroxy-6-methyloxan-2-yl]oxy}hexan-3-yl]oxy}-3,5-dihydroxy-6-(hydroxymethyl)oxan-4-yl]oxy}-4-hydroxy-6-[(1r,2r)-1,2,3-trihydrox Chemical compound O[C@H]1[C@H](O)[C@H](O)[C@H](C)O[C@H]1O[C@H]([C@@H](NC(C)=O)C=O)[C@@H]([C@H](O)CO)O[C@H]1[C@H](O)[C@@H](O[C@]2(O[C@H]([C@H](NC(C)=O)[C@@H](O)C2)[C@H](O)[C@H](O)CO)C(O)=O)[C@@H](O)[C@@H](CO)O1 LAQPKDLYOBZWBT-NYLDSJSYSA-N 0.000 description 2
- MZOFCQQQCNRIBI-VMXHOPILSA-N (3s)-4-[[(2s)-1-[[(2s)-1-[[(1s)-1-carboxy-2-hydroxyethyl]amino]-4-methyl-1-oxopentan-2-yl]amino]-5-(diaminomethylideneamino)-1-oxopentan-2-yl]amino]-3-[[2-[[(2s)-2,6-diaminohexanoyl]amino]acetyl]amino]-4-oxobutanoic acid Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN MZOFCQQQCNRIBI-VMXHOPILSA-N 0.000 description 2
- GERXSZLDSOPHJV-UHFFFAOYSA-N (4-nitrophenyl) 2-iodoacetate Chemical compound [O-][N+](=O)C1=CC=C(OC(=O)CI)C=C1 GERXSZLDSOPHJV-UHFFFAOYSA-N 0.000 description 2
- KWTSXDURSIMDCE-QMMMGPOBSA-N (S)-amphetamine Chemical compound C[C@H](N)CC1=CC=CC=C1 KWTSXDURSIMDCE-QMMMGPOBSA-N 0.000 description 2
- AASYSXRGODIQGY-UHFFFAOYSA-N 1-[1-(2,5-dioxopyrrol-1-yl)hexyl]pyrrole-2,5-dione Chemical compound O=C1C=CC(=O)N1C(CCCCC)N1C(=O)C=CC1=O AASYSXRGODIQGY-UHFFFAOYSA-N 0.000 description 2
- DIYPCWKHSODVAP-UHFFFAOYSA-N 1-[3-(2,5-dioxopyrrol-1-yl)benzoyl]oxy-2,5-dioxopyrrolidine-3-sulfonic acid Chemical compound O=C1C(S(=O)(=O)O)CC(=O)N1OC(=O)C1=CC=CC(N2C(C=CC2=O)=O)=C1 DIYPCWKHSODVAP-UHFFFAOYSA-N 0.000 description 2
- FPKVOQKZMBDBKP-UHFFFAOYSA-N 1-[4-[(2,5-dioxopyrrol-1-yl)methyl]cyclohexanecarbonyl]oxy-2,5-dioxopyrrolidine-3-sulfonic acid Chemical compound O=C1C(S(=O)(=O)O)CC(=O)N1OC(=O)C1CCC(CN2C(C=CC2=O)=O)CC1 FPKVOQKZMBDBKP-UHFFFAOYSA-N 0.000 description 2
- VHYRLCJMMJQUBY-UHFFFAOYSA-N 1-[4-[4-(2,5-dioxopyrrol-1-yl)phenyl]butanoyloxy]-2,5-dioxopyrrolidine-3-sulfonic acid Chemical compound O=C1C(S(=O)(=O)O)CC(=O)N1OC(=O)CCCC1=CC=C(N2C(C=CC2=O)=O)C=C1 VHYRLCJMMJQUBY-UHFFFAOYSA-N 0.000 description 2
- MWOOKDULMBMMPN-UHFFFAOYSA-N 3-(2-ethyl-1,2-oxazol-2-ium-5-yl)benzenesulfonate Chemical compound O1[N+](CC)=CC=C1C1=CC=CC(S([O-])(=O)=O)=C1 MWOOKDULMBMMPN-UHFFFAOYSA-N 0.000 description 2
- BYMZEXPKRSJSSO-UHFFFAOYSA-N 4-azido-n-[2-[2-(4-azido-2-nitroanilino)ethylsulfonylsulfanyl]ethyl]-2-nitroaniline Chemical compound [O-][N+](=O)C1=CC(N=[N+]=[N-])=CC=C1NCCSS(=O)(=O)CCNC1=CC=C(N=[N+]=[N-])C=C1[N+]([O-])=O BYMZEXPKRSJSSO-UHFFFAOYSA-N 0.000 description 2
- QLHLYJHNOCILIT-UHFFFAOYSA-N 4-o-(2,5-dioxopyrrolidin-1-yl) 1-o-[2-[4-(2,5-dioxopyrrolidin-1-yl)oxy-4-oxobutanoyl]oxyethyl] butanedioate Chemical compound O=C1CCC(=O)N1OC(=O)CCC(=O)OCCOC(=O)CCC(=O)ON1C(=O)CCC1=O QLHLYJHNOCILIT-UHFFFAOYSA-N 0.000 description 2
- 229920000936 Agarose Polymers 0.000 description 2
- 108700028369 Alleles Proteins 0.000 description 2
- 239000004475 Arginine Substances 0.000 description 2
- 102100032487 Beta-mannosidase Human genes 0.000 description 2
- 102000015081 Blood Coagulation Factors Human genes 0.000 description 2
- 108010039209 Blood Coagulation Factors Proteins 0.000 description 2
- 102100027098 CMP-N-acetylneuraminate-beta-galactosamide-alpha-2,3-sialyltransferase 1 Human genes 0.000 description 2
- 241000589875 Campylobacter jejuni Species 0.000 description 2
- 108010001857 Cell Surface Receptors Proteins 0.000 description 2
- 102000000844 Cell Surface Receptors Human genes 0.000 description 2
- VEXZGXHMUGYJMC-UHFFFAOYSA-M Chloride anion Chemical compound [Cl-] VEXZGXHMUGYJMC-UHFFFAOYSA-M 0.000 description 2
- 229920002567 Chondroitin Polymers 0.000 description 2
- 102000011022 Chorionic Gonadotropin Human genes 0.000 description 2
- 108010062540 Chorionic Gonadotropin Proteins 0.000 description 2
- 108091035707 Consensus sequence Proteins 0.000 description 2
- NBSCHQHZLSJFNQ-QTVWNMPRSA-N D-Mannose-6-phosphate Chemical compound OC1O[C@H](COP(O)(O)=O)[C@@H](O)[C@H](O)[C@@H]1O NBSCHQHZLSJFNQ-QTVWNMPRSA-N 0.000 description 2
- SRBFZHDQGSBBOR-IOVATXLUSA-N D-xylopyranose Chemical compound O[C@@H]1COC(O)[C@H](O)[C@H]1O SRBFZHDQGSBBOR-IOVATXLUSA-N 0.000 description 2
- 230000004544 DNA amplification Effects 0.000 description 2
- 229920000045 Dermatan sulfate Polymers 0.000 description 2
- 229920002307 Dextran Polymers 0.000 description 2
- 238000005698 Diels-Alder reaction Methods 0.000 description 2
- RTZKZFJDLAIYFH-UHFFFAOYSA-N Diethyl ether Chemical compound CCOCC RTZKZFJDLAIYFH-UHFFFAOYSA-N 0.000 description 2
- 108010089072 Dolichyl-diphosphooligosaccharide-protein glycotransferase Proteins 0.000 description 2
- 206010013883 Dwarfism Diseases 0.000 description 2
- ULGZDMOVFRHVEP-RWJQBGPGSA-N Erythromycin Chemical compound O([C@@H]1[C@@H](C)C(=O)O[C@@H]([C@@]([C@H](O)[C@@H](C)C(=O)[C@H](C)C[C@@](C)(O)[C@H](O[C@H]2[C@@H]([C@H](C[C@@H](C)O2)N(C)C)O)[C@H]1C)(C)O)CC)[C@H]1C[C@@](C)(OC)[C@@H](O)[C@H](C)O1 ULGZDMOVFRHVEP-RWJQBGPGSA-N 0.000 description 2
- 241000206602 Eukaryota Species 0.000 description 2
- 102000012673 Follicle Stimulating Hormone Human genes 0.000 description 2
- 108010079345 Follicle Stimulating Hormone Proteins 0.000 description 2
- ZHNUHDYFZUAESO-UHFFFAOYSA-N Formamide Chemical compound NC=O ZHNUHDYFZUAESO-UHFFFAOYSA-N 0.000 description 2
- IAJILQKETJEXLJ-UHFFFAOYSA-N Galacturonsaeure Natural products O=CC(O)C(O)C(O)C(O)C(O)=O IAJILQKETJEXLJ-UHFFFAOYSA-N 0.000 description 2
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 2
- 239000004471 Glycine Substances 0.000 description 2
- 229920002683 Glycosaminoglycan Polymers 0.000 description 2
- RPTUSVTUFVMDQK-UHFFFAOYSA-N Hidralazin Chemical compound C1=CC=C2C(NN)=NN=CC2=C1 RPTUSVTUFVMDQK-UHFFFAOYSA-N 0.000 description 2
- 241000701044 Human gammaherpesvirus 4 Species 0.000 description 2
- UFHFLCQGNIYNRP-UHFFFAOYSA-N Hydrogen Chemical compound [H][H] UFHFLCQGNIYNRP-UHFFFAOYSA-N 0.000 description 2
- CPELXLSAUQHCOX-UHFFFAOYSA-N Hydrogen bromide Chemical compound Br CPELXLSAUQHCOX-UHFFFAOYSA-N 0.000 description 2
- AVXURJPOCDRRFD-UHFFFAOYSA-N Hydroxylamine Chemical compound ON AVXURJPOCDRRFD-UHFFFAOYSA-N 0.000 description 2
- PMMYEEVYMWASQN-DMTCNVIQSA-N Hydroxyproline Chemical compound O[C@H]1CN[C@H](C(O)=O)C1 PMMYEEVYMWASQN-DMTCNVIQSA-N 0.000 description 2
- 102000009786 Immunoglobulin Constant Regions Human genes 0.000 description 2
- 108010009817 Immunoglobulin Constant Regions Proteins 0.000 description 2
- 102000014150 Interferons Human genes 0.000 description 2
- 108010050904 Interferons Proteins 0.000 description 2
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 2
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 2
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 2
- LRQKBLKVPFOOQJ-YFKPBYRVSA-N L-norleucine Chemical group CCCC[C@H]([NH3+])C([O-])=O LRQKBLKVPFOOQJ-YFKPBYRVSA-N 0.000 description 2
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 2
- PNNNRSAQSRJVSB-UHFFFAOYSA-N L-rhamnose Natural products CC(O)C(O)C(O)C(O)C=O PNNNRSAQSRJVSB-UHFFFAOYSA-N 0.000 description 2
- PNIWLNAGKUGXDO-UHFFFAOYSA-N Lactosamine Natural products OC1C(N)C(O)OC(CO)C1OC1C(O)C(O)C(O)C(CO)O1 PNIWLNAGKUGXDO-UHFFFAOYSA-N 0.000 description 2
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 2
- 108010070158 Lactose synthase Proteins 0.000 description 2
- 108090001090 Lectins Proteins 0.000 description 2
- 102000004856 Lectins Human genes 0.000 description 2
- 108010000817 Leuprolide Proteins 0.000 description 2
- NNJVILVZKWQKPM-UHFFFAOYSA-N Lidocaine Chemical compound CCN(CC)CC(=O)NC1=C(C)C=CC=C1C NNJVILVZKWQKPM-UHFFFAOYSA-N 0.000 description 2
- 102000003960 Ligases Human genes 0.000 description 2
- 108090000364 Ligases Proteins 0.000 description 2
- 102000007651 Macrophage Colony-Stimulating Factor Human genes 0.000 description 2
- 108010046938 Macrophage Colony-Stimulating Factor Proteins 0.000 description 2
- CSNNHWWHGAXBCP-UHFFFAOYSA-L Magnesium sulfate Chemical compound [Mg+2].[O-][S+2]([O-])([O-])[O-] CSNNHWWHGAXBCP-UHFFFAOYSA-L 0.000 description 2
- 238000006845 Michael addition reaction Methods 0.000 description 2
- 108010015197 N-acetyllactosaminide alpha-2,3-sialyltransferase Proteins 0.000 description 2
- SQVRNKJHWKZAKO-LUWBGTNYSA-N N-acetylneuraminic acid Chemical compound CC(=O)N[C@@H]1[C@@H](O)CC(O)(C(O)=O)O[C@H]1[C@H](O)[C@H](O)CO SQVRNKJHWKZAKO-LUWBGTNYSA-N 0.000 description 2
- 241000588653 Neisseria Species 0.000 description 2
- 108010006232 Neuraminidase Proteins 0.000 description 2
- 102000005348 Neuraminidase Human genes 0.000 description 2
- 239000004677 Nylon Substances 0.000 description 2
- 101710116435 Outer membrane protein Proteins 0.000 description 2
- 102000004316 Oxidoreductases Human genes 0.000 description 2
- 108090000854 Oxidoreductases Proteins 0.000 description 2
- 229910019142 PO4 Inorganic materials 0.000 description 2
- 229930012538 Paclitaxel Natural products 0.000 description 2
- 229920002873 Polyethylenimine Polymers 0.000 description 2
- 101710182846 Polyhedrin Proteins 0.000 description 2
- JUJWROOIHBZHMG-UHFFFAOYSA-N Pyridine Chemical compound C1=CC=NC=C1 JUJWROOIHBZHMG-UHFFFAOYSA-N 0.000 description 2
- 101000652822 Rattus norvegicus CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase Proteins 0.000 description 2
- 108010039491 Ricin Proteins 0.000 description 2
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 2
- WQDUMFSSJAZKTM-UHFFFAOYSA-N Sodium methoxide Chemical compound [Na+].[O-]C WQDUMFSSJAZKTM-UHFFFAOYSA-N 0.000 description 2
- 108010090804 Streptavidin Proteins 0.000 description 2
- 101000895926 Streptomyces plicatus Endo-beta-N-acetylglucosaminidase H Proteins 0.000 description 2
- 229930006000 Sucrose Natural products 0.000 description 2
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 2
- 102000004896 Sulfotransferases Human genes 0.000 description 2
- 108090001033 Sulfotransferases Proteins 0.000 description 2
- NKANXQFJJICGDU-QPLCGJKRSA-N Tamoxifen Chemical compound C=1C=CC=CC=1C(/CC)=C(C=1C=CC(OCCN(C)C)=CC=1)/C1=CC=CC=C1 NKANXQFJJICGDU-QPLCGJKRSA-N 0.000 description 2
- MUMGGOZAMZWBJJ-DYKIIFRCSA-N Testostosterone Chemical compound O=C1CC[C@]2(C)[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 MUMGGOZAMZWBJJ-DYKIIFRCSA-N 0.000 description 2
- 108700009124 Transcription Initiation Site Proteins 0.000 description 2
- ZZHLYYDVIOPZBE-UHFFFAOYSA-N Trimeprazine Chemical compound C1=CC=C2N(CC(CN(C)C)C)C3=CC=CC=C3SC2=C1 ZZHLYYDVIOPZBE-UHFFFAOYSA-N 0.000 description 2
- 108060008683 Tumor Necrosis Factor Receptor Proteins 0.000 description 2
- 108010090473 UDP-N-acetylglucosamine-peptide beta-N-acetylglucosaminyltransferase Proteins 0.000 description 2
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 2
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 2
- 241000700605 Viruses Species 0.000 description 2
- 102000010199 Xylosyltransferases Human genes 0.000 description 2
- 238000010521 absorption reaction Methods 0.000 description 2
- 230000002378 acidificating effect Effects 0.000 description 2
- RJURFGZVJUQBHK-UHFFFAOYSA-N actinomycin D Natural products CC1OC(=O)C(C(C)C)N(C)C(=O)CN(C)C(=O)C2CCCN2C(=O)C(C(C)C)NC(=O)C1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)NC4C(=O)NC(C(N5CCCC5C(=O)N(C)CC(=O)N(C)C(C(C)C)C(=O)OC4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-UHFFFAOYSA-N 0.000 description 2
- 125000002252 acyl group Chemical group 0.000 description 2
- 239000002671 adjuvant Substances 0.000 description 2
- 238000001042 affinity chromatography Methods 0.000 description 2
- HAXFWIACAGNFHA-UHFFFAOYSA-N aldrithiol Chemical group C=1C=CC=NC=1SSC1=CC=CC=N1 HAXFWIACAGNFHA-UHFFFAOYSA-N 0.000 description 2
- 125000001931 aliphatic group Chemical group 0.000 description 2
- 150000001408 amides Chemical class 0.000 description 2
- 150000001409 amidines Chemical class 0.000 description 2
- 230000000340 anti-metabolite Effects 0.000 description 2
- 230000000845 anti-microbial effect Effects 0.000 description 2
- 239000000739 antihistaminic agent Substances 0.000 description 2
- 229940100197 antimetabolite Drugs 0.000 description 2
- 239000002256 antimetabolite Substances 0.000 description 2
- 239000008365 aqueous carrier Substances 0.000 description 2
- 239000007864 aqueous solution Substances 0.000 description 2
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 2
- 235000009697 arginine Nutrition 0.000 description 2
- 150000001502 aryl halides Chemical class 0.000 description 2
- 150000001540 azides Chemical class 0.000 description 2
- 239000011324 bead Substances 0.000 description 2
- RWCCWEUUXYIKHB-UHFFFAOYSA-N benzophenone Chemical group C=1C=CC=CC=1C(=O)C1=CC=CC=C1 RWCCWEUUXYIKHB-UHFFFAOYSA-N 0.000 description 2
- WGQKYBSKWIADBV-UHFFFAOYSA-N benzylamine Chemical compound NCC1=CC=CC=C1 WGQKYBSKWIADBV-UHFFFAOYSA-N 0.000 description 2
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 2
- 108010055059 beta-Mannosidase Proteins 0.000 description 2
- 239000012867 bioactive agent Substances 0.000 description 2
- 229960002685 biotin Drugs 0.000 description 2
- 235000020958 biotin Nutrition 0.000 description 2
- 239000011616 biotin Substances 0.000 description 2
- NXVYSVARUKNFNF-NXEZZACHSA-N bis(2,5-dioxopyrrolidin-1-yl) (2r,3r)-2,3-dihydroxybutanedioate Chemical compound O=C([C@H](O)[C@@H](O)C(=O)ON1C(CCC1=O)=O)ON1C(=O)CCC1=O NXVYSVARUKNFNF-NXEZZACHSA-N 0.000 description 2
- LNQHREYHFRFJAU-UHFFFAOYSA-N bis(2,5-dioxopyrrolidin-1-yl) pentanedioate Chemical compound O=C1CCC(=O)N1OC(=O)CCCC(=O)ON1C(=O)CCC1=O LNQHREYHFRFJAU-UHFFFAOYSA-N 0.000 description 2
- VYLDEYYOISNGST-UHFFFAOYSA-N bissulfosuccinimidyl suberate Chemical compound O=C1C(S(=O)(=O)O)CC(=O)N1OC(=O)CCCCCCC(=O)ON1C(=O)C(S(O)(=O)=O)CC1=O VYLDEYYOISNGST-UHFFFAOYSA-N 0.000 description 2
- 239000003114 blood coagulation factor Substances 0.000 description 2
- 230000010478 bone regeneration Effects 0.000 description 2
- 238000004364 calculation method Methods 0.000 description 2
- 150000004649 carbonic acid derivatives Chemical class 0.000 description 2
- 125000002057 carboxymethyl group Chemical group [H]OC(=O)C([H])([H])[*] 0.000 description 2
- 238000009903 catalytic hydrogenation reaction Methods 0.000 description 2
- 230000010261 cell growth Effects 0.000 description 2
- 239000013592 cell lysate Substances 0.000 description 2
- 238000005119 centrifugation Methods 0.000 description 2
- 239000002738 chelating agent Substances 0.000 description 2
- DLGJWSVWTWEWBJ-HGGSSLSASA-N chondroitin Chemical compound CC(O)=N[C@@H]1[C@H](O)O[C@H](CO)[C@H](O)[C@@H]1OC1[C@H](O)[C@H](O)C=C(C(O)=O)O1 DLGJWSVWTWEWBJ-HGGSSLSASA-N 0.000 description 2
- AQIXAKUUQRKLND-UHFFFAOYSA-N cimetidine Chemical compound N#C/N=C(/NC)NCCSCC=1N=CNC=1C AQIXAKUUQRKLND-UHFFFAOYSA-N 0.000 description 2
- 229960001380 cimetidine Drugs 0.000 description 2
- MYSWGUAQZAJSOK-UHFFFAOYSA-N ciprofloxacin Chemical compound C12=CC(N3CCNCC3)=C(F)C=C2C(=O)C(C(=O)O)=CN1C1CC1 MYSWGUAQZAJSOK-UHFFFAOYSA-N 0.000 description 2
- 230000004087 circulation Effects 0.000 description 2
- OROGSEYTTFOCAN-DNJOTXNNSA-N codeine Chemical compound C([C@H]1[C@H](N(CC[C@@]112)C)C3)=C[C@H](O)[C@@H]1OC1=C2C3=CC=C1OC OROGSEYTTFOCAN-DNJOTXNNSA-N 0.000 description 2
- 238000004440 column chromatography Methods 0.000 description 2
- 229940126214 compound 3 Drugs 0.000 description 2
- 238000007796 conventional method Methods 0.000 description 2
- 229920001577 copolymer Polymers 0.000 description 2
- 150000003983 crown ethers Chemical class 0.000 description 2
- 239000013078 crystal Substances 0.000 description 2
- 235000018417 cysteine Nutrition 0.000 description 2
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 2
- 230000022811 deglycosylation Effects 0.000 description 2
- 108010005905 delta-hGHR Proteins 0.000 description 2
- 239000003398 denaturant Substances 0.000 description 2
- 238000004925 denaturation Methods 0.000 description 2
- 230000036425 denaturation Effects 0.000 description 2
- 206010012601 diabetes mellitus Diseases 0.000 description 2
- 239000000032 diagnostic agent Substances 0.000 description 2
- 229940039227 diagnostic agent Drugs 0.000 description 2
- 150000001991 dicarboxylic acids Chemical class 0.000 description 2
- 238000010790 dilution Methods 0.000 description 2
- 239000012895 dilution Substances 0.000 description 2
- MFXIAHWTYXXWPO-UHFFFAOYSA-N dimethyl butanediimidate Chemical compound COC(=N)CCC(=N)OC MFXIAHWTYXXWPO-UHFFFAOYSA-N 0.000 description 2
- ZLFRJHOBQVVTOJ-UHFFFAOYSA-N dimethyl hexanediimidate Chemical compound COC(=N)CCCCC(=N)OC ZLFRJHOBQVVTOJ-UHFFFAOYSA-N 0.000 description 2
- FRTGEIHSCHXMTI-UHFFFAOYSA-N dimethyl octanediimidate Chemical compound COC(=N)CCCCCCC(=N)OC FRTGEIHSCHXMTI-UHFFFAOYSA-N 0.000 description 2
- LRPQMNYCTSPGCX-UHFFFAOYSA-N dimethyl pimelimidate Chemical compound COC(=N)CCCCCC(=N)OC LRPQMNYCTSPGCX-UHFFFAOYSA-N 0.000 description 2
- AQVMGRVHEOWKRT-UHFFFAOYSA-N dimethyl propanediimidate Chemical compound COC(=N)CC(=N)OC AQVMGRVHEOWKRT-UHFFFAOYSA-N 0.000 description 2
- 150000002016 disaccharides Chemical class 0.000 description 2
- 238000009826 distribution Methods 0.000 description 2
- ZWIBGKZDAWNIFC-UHFFFAOYSA-N disuccinimidyl suberate Chemical compound O=C1CCC(=O)N1OC(=O)CCCCCCC(=O)ON1C(=O)CCC1=O ZWIBGKZDAWNIFC-UHFFFAOYSA-N 0.000 description 2
- PMMYEEVYMWASQN-UHFFFAOYSA-N dl-hydroxyproline Natural products OC1C[NH2+]C(C([O-])=O)C1 PMMYEEVYMWASQN-UHFFFAOYSA-N 0.000 description 2
- 239000003937 drug carrier Substances 0.000 description 2
- 229960005501 duocarmycin Drugs 0.000 description 2
- 229930184221 duocarmycin Natural products 0.000 description 2
- 239000000839 emulsion Substances 0.000 description 2
- 230000009144 enzymatic modification Effects 0.000 description 2
- AEUTYOVWOVBAKS-UWVGGRQHSA-N ethambutol Chemical compound CC[C@@H](CO)NCCN[C@@H](CC)CO AEUTYOVWOVBAKS-UWVGGRQHSA-N 0.000 description 2
- 238000012869 ethanol precipitation Methods 0.000 description 2
- JYILPERKVHXLNF-QMNUTNMBSA-N ethynodiol Chemical compound O[C@H]1CC[C@@H]2[C@H]3CC[C@](C)([C@](CC4)(O)C#C)[C@@H]4[C@@H]3CCC2=C1 JYILPERKVHXLNF-QMNUTNMBSA-N 0.000 description 2
- 229960000218 etynodiol Drugs 0.000 description 2
- 238000000605 extraction Methods 0.000 description 2
- 239000000706 filtrate Substances 0.000 description 2
- 238000001914 filtration Methods 0.000 description 2
- 239000007850 fluorescent dye Substances 0.000 description 2
- 229940028334 follicle stimulating hormone Drugs 0.000 description 2
- 235000019256 formaldehyde Nutrition 0.000 description 2
- 238000009472 formulation Methods 0.000 description 2
- 238000002825 functional assay Methods 0.000 description 2
- 238000007306 functionalization reaction Methods 0.000 description 2
- 230000002538 fungal effect Effects 0.000 description 2
- 108010001671 galactoside 3-fucosyltransferase Proteins 0.000 description 2
- 239000000499 gel Substances 0.000 description 2
- 238000010353 genetic engineering Methods 0.000 description 2
- 239000003862 glucocorticoid Substances 0.000 description 2
- 239000008103 glucose Substances 0.000 description 2
- LEQAOMBKQFMDFZ-UHFFFAOYSA-N glyoxal Chemical compound O=CC=O LEQAOMBKQFMDFZ-UHFFFAOYSA-N 0.000 description 2
- 229960000789 guanidine hydrochloride Drugs 0.000 description 2
- PJJJBBJSCAKJQF-UHFFFAOYSA-N guanidinium chloride Chemical compound [Cl-].NC(N)=[NH2+] PJJJBBJSCAKJQF-UHFFFAOYSA-N 0.000 description 2
- 150000004820 halides Chemical class 0.000 description 2
- LNEPOXFFQSENCJ-UHFFFAOYSA-N haloperidol Chemical compound C1CC(O)(C=2C=CC(Cl)=CC=2)CCN1CCCC(=O)C1=CC=C(F)C=C1 LNEPOXFFQSENCJ-UHFFFAOYSA-N 0.000 description 2
- 125000000487 histidyl group Chemical class [H]N([H])C(C(=O)O*)C([H])([H])C1=C([H])N([H])C([H])=N1 0.000 description 2
- 229940084986 human chorionic gonadotropin Drugs 0.000 description 2
- JYGXADMDTFJGBT-VWUMJDOOSA-N hydrocortisone Chemical compound O=C1CC[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 JYGXADMDTFJGBT-VWUMJDOOSA-N 0.000 description 2
- 229960002591 hydroxyproline Drugs 0.000 description 2
- 210000000987 immune system Anatomy 0.000 description 2
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 description 2
- 102000006495 integrins Human genes 0.000 description 2
- 108010044426 integrins Proteins 0.000 description 2
- 229940079322 interferon Drugs 0.000 description 2
- 238000007918 intramuscular administration Methods 0.000 description 2
- 238000007912 intraperitoneal administration Methods 0.000 description 2
- 238000004255 ion exchange chromatography Methods 0.000 description 2
- 230000002427 irreversible effect Effects 0.000 description 2
- 238000002955 isolation Methods 0.000 description 2
- KXCLCNHUUKTANI-RBIYJLQWSA-N keratan Chemical compound CC(=O)N[C@@H]1[C@@H](O)C[C@@H](COS(O)(=O)=O)O[C@H]1O[C@@H]1[C@@H](O)[C@H](O[C@@H]2[C@H](O[C@@H](O[C@H]3[C@H]([C@@H](COS(O)(=O)=O)O[C@@H](O)[C@@H]3O)O)[C@H](NC(C)=O)[C@H]2O)COS(O)(=O)=O)O[C@H](COS(O)(=O)=O)[C@@H]1O KXCLCNHUUKTANI-RBIYJLQWSA-N 0.000 description 2
- DOVBXGDYENZJBJ-ONMPCKGSSA-N lactosamine Chemical compound O=C[C@H](N)[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O DOVBXGDYENZJBJ-ONMPCKGSSA-N 0.000 description 2
- 239000008101 lactose Substances 0.000 description 2
- 239000002523 lectin Substances 0.000 description 2
- GFIJNRVAKGFPGQ-LIJARHBVSA-N leuprolide Chemical compound CCNC(=O)[C@@H]1CCCN1C(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H]1NC(=O)CC1)CC1=CC=C(O)C=C1 GFIJNRVAKGFPGQ-LIJARHBVSA-N 0.000 description 2
- 229960004338 leuprorelin Drugs 0.000 description 2
- 229960004194 lidocaine Drugs 0.000 description 2
- 150000002632 lipids Chemical class 0.000 description 2
- 210000004185 liver Anatomy 0.000 description 2
- 230000004807 localization Effects 0.000 description 2
- RLSSMJSEOOYNOY-UHFFFAOYSA-N m-cresol Chemical compound CC1=CC=CC(O)=C1 RLSSMJSEOOYNOY-UHFFFAOYSA-N 0.000 description 2
- 210000002540 macrophage Anatomy 0.000 description 2
- 229960004616 medroxyprogesterone Drugs 0.000 description 2
- FRQMUZJSZHZSGN-HBNHAYAOSA-N medroxyprogesterone Chemical compound C([C@@]12C)CC(=O)C=C1[C@@H](C)C[C@@H]1[C@@H]2CC[C@]2(C)[C@@](O)(C(C)=O)CC[C@H]21 FRQMUZJSZHZSGN-HBNHAYAOSA-N 0.000 description 2
- 238000005374 membrane filtration Methods 0.000 description 2
- BDAGIHXWWSANSR-UHFFFAOYSA-N methanoic acid Natural products OC=O BDAGIHXWWSANSR-UHFFFAOYSA-N 0.000 description 2
- 235000013336 milk Nutrition 0.000 description 2
- 239000008267 milk Substances 0.000 description 2
- 210000004080 milk Anatomy 0.000 description 2
- NKAAEMMYHLFEFN-UHFFFAOYSA-M monosodium tartrate Chemical compound [Na+].OC(=O)C(O)C(O)C([O-])=O NKAAEMMYHLFEFN-UHFFFAOYSA-M 0.000 description 2
- 201000000585 muscular atrophy Diseases 0.000 description 2
- 230000000869 mutational effect Effects 0.000 description 2
- 229920005615 natural polymer Polymers 0.000 description 2
- CERZMXAJYMMUDR-UHFFFAOYSA-N neuraminic acid Natural products NC1C(O)CC(O)(C(O)=O)OC1C(O)C(O)CO CERZMXAJYMMUDR-UHFFFAOYSA-N 0.000 description 2
- 230000036963 noncompetitive effect Effects 0.000 description 2
- 238000010534 nucleophilic substitution reaction Methods 0.000 description 2
- 229920001778 nylon Polymers 0.000 description 2
- 239000003921 oil Substances 0.000 description 2
- 230000003204 osmotic effect Effects 0.000 description 2
- 150000002924 oxiranes Chemical class 0.000 description 2
- 229960001592 paclitaxel Drugs 0.000 description 2
- XQYZDYMELSJDRZ-UHFFFAOYSA-N papaverine Chemical compound C1=C(OC)C(OC)=CC=C1CC1=NC=CC2=CC(OC)=C(OC)C=C12 XQYZDYMELSJDRZ-UHFFFAOYSA-N 0.000 description 2
- 238000007911 parenteral administration Methods 0.000 description 2
- 230000037361 pathway Effects 0.000 description 2
- WXZMFSXDPGVJKK-UHFFFAOYSA-N pentaerythritol Chemical compound OCC(CO)(CO)CO WXZMFSXDPGVJKK-UHFFFAOYSA-N 0.000 description 2
- 239000000546 pharmaceutical excipient Substances 0.000 description 2
- DHHVAGZRUROJKS-UHFFFAOYSA-N phentermine Chemical compound CC(C)(N)CC1=CC=CC=C1 DHHVAGZRUROJKS-UHFFFAOYSA-N 0.000 description 2
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 2
- 239000002953 phosphate buffered saline Substances 0.000 description 2
- 230000026731 phosphorylation Effects 0.000 description 2
- 238000006366 phosphorylation reaction Methods 0.000 description 2
- 230000004962 physiological condition Effects 0.000 description 2
- 229920001308 poly(aminoacid) Polymers 0.000 description 2
- 238000002264 polyacrylamide gel electrophoresis Methods 0.000 description 2
- 229920000656 polylysine Polymers 0.000 description 2
- 239000011148 porous material Substances 0.000 description 2
- 125000006239 protecting group Chemical group 0.000 description 2
- RXWNCPJZOCPEPQ-NVWDDTSBSA-N puromycin Chemical compound C1=CC(OC)=CC=C1C[C@H](N)C(=O)N[C@H]1[C@@H](O)[C@H](N2C3=NC=NC(=C3N=C2)N(C)C)O[C@@H]1CO RXWNCPJZOCPEPQ-NVWDDTSBSA-N 0.000 description 2
- LOUPRKONTZGTKE-LHHVKLHASA-N quinidine Chemical compound C([C@H]([C@H](C1)C=C)C2)C[N@@]1[C@H]2[C@@H](O)C1=CC=NC2=CC=C(OC)C=C21 LOUPRKONTZGTKE-LHHVKLHASA-N 0.000 description 2
- VMXUWOKSQNHOCA-LCYFTJDESA-N ranitidine Chemical compound [O-][N+](=O)/C=C(/NC)NCCSCC1=CC=C(CN(C)C)O1 VMXUWOKSQNHOCA-LCYFTJDESA-N 0.000 description 2
- 229960000620 ranitidine Drugs 0.000 description 2
- 238000010188 recombinant method Methods 0.000 description 2
- 238000011084 recovery Methods 0.000 description 2
- 230000001105 regulatory effect Effects 0.000 description 2
- 230000010076 replication Effects 0.000 description 2
- 108010066476 ribonuclease B Proteins 0.000 description 2
- 239000000741 silica gel Substances 0.000 description 2
- 229910002027 silica gel Inorganic materials 0.000 description 2
- 238000001542 size-exclusion chromatography Methods 0.000 description 2
- JQWHASGSAFIOCM-UHFFFAOYSA-M sodium periodate Chemical compound [Na+].[O-]I(=O)(=O)=O JQWHASGSAFIOCM-UHFFFAOYSA-M 0.000 description 2
- 238000005063 solubilization Methods 0.000 description 2
- 230000007928 solubilization Effects 0.000 description 2
- 239000007858 starting material Substances 0.000 description 2
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 2
- 238000007920 subcutaneous administration Methods 0.000 description 2
- 238000010254 subcutaneous injection Methods 0.000 description 2
- 239000007929 subcutaneous injection Substances 0.000 description 2
- 125000001424 substituent group Chemical group 0.000 description 2
- 239000005720 sucrose Substances 0.000 description 2
- 229940124530 sulfonamide Drugs 0.000 description 2
- 150000003456 sulfonamides Chemical class 0.000 description 2
- 208000024891 symptom Diseases 0.000 description 2
- 230000002194 synthesizing effect Effects 0.000 description 2
- 229940037128 systemic glucocorticoids Drugs 0.000 description 2
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 2
- 238000002560 therapeutic procedure Methods 0.000 description 2
- CNHYKKNIIGEXAY-UHFFFAOYSA-N thiolan-2-imine Chemical compound N=C1CCCS1 CNHYKKNIIGEXAY-UHFFFAOYSA-N 0.000 description 2
- 150000003573 thiols Chemical class 0.000 description 2
- WYWHKKSPHMUBEB-UHFFFAOYSA-N tioguanine Chemical compound N1C(N)=NC(=S)C2=C1N=CN2 WYWHKKSPHMUBEB-UHFFFAOYSA-N 0.000 description 2
- 230000000699 topical effect Effects 0.000 description 2
- FGMPLJWBKKVCDB-UHFFFAOYSA-N trans-L-hydroxy-proline Natural products ON1CCCC1C(O)=O FGMPLJWBKKVCDB-UHFFFAOYSA-N 0.000 description 2
- 238000003151 transfection method Methods 0.000 description 2
- 230000009466 transformation Effects 0.000 description 2
- 230000009261 transgenic effect Effects 0.000 description 2
- 229960005294 triamcinolone Drugs 0.000 description 2
- GFNANZIMVAIWHM-OBYCQNJPSA-N triamcinolone Chemical compound O=C1C=C[C@]2(C)[C@@]3(F)[C@@H](O)C[C@](C)([C@@]([C@H](O)C4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 GFNANZIMVAIWHM-OBYCQNJPSA-N 0.000 description 2
- 239000001226 triphosphate Substances 0.000 description 2
- 235000011178 triphosphate Nutrition 0.000 description 2
- 125000002264 triphosphate group Chemical group [H]OP(=O)(O[H])OP(=O)(O[H])OP(=O)(O[H])O* 0.000 description 2
- 150000004043 trisaccharides Chemical class 0.000 description 2
- 102000003298 tumor necrosis factor receptor Human genes 0.000 description 2
- 238000005406 washing Methods 0.000 description 2
- 239000000080 wetting agent Substances 0.000 description 2
- HDTRYLNUVZCQOY-UHFFFAOYSA-N α-D-glucopyranosyl-α-D-glucopyranoside Natural products OC1C(O)C(O)C(CO)OC1OC1C(O)C(O)C(O)C(CO)O1 HDTRYLNUVZCQOY-UHFFFAOYSA-N 0.000 description 1
- WWYNJERNGUHSAO-XUDSTZEESA-N (+)-Norgestrel Chemical compound O=C1CC[C@@H]2[C@H]3CC[C@](CC)([C@](CC4)(O)C#C)[C@@H]4[C@@H]3CCC2=C1 WWYNJERNGUHSAO-XUDSTZEESA-N 0.000 description 1
- DBGIVFWFUFKIQN-UHFFFAOYSA-N (+-)-Fenfluramine Chemical compound CCNC(C)CC1=CC=CC(C(F)(F)F)=C1 DBGIVFWFUFKIQN-UHFFFAOYSA-N 0.000 description 1
- TYKASZBHFXBROF-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 2-(2,5-dioxopyrrol-1-yl)acetate Chemical compound O=C1CCC(=O)N1OC(=O)CN1C(=O)C=CC1=O TYKASZBHFXBROF-UHFFFAOYSA-N 0.000 description 1
- FLCQLSRLQIPNLM-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 2-acetylsulfanylacetate Chemical compound CC(=O)SCC(=O)ON1C(=O)CCC1=O FLCQLSRLQIPNLM-UHFFFAOYSA-N 0.000 description 1
- AASBXERNXVFUEJ-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) propanoate Chemical compound CCC(=O)ON1C(=O)CCC1=O AASBXERNXVFUEJ-UHFFFAOYSA-N 0.000 description 1
- DIGQNXIGRZPYDK-WKSCXVIASA-N (2R)-6-amino-2-[[2-[[(2S)-2-[[2-[[(2R)-2-[[(2S)-2-[[(2R,3S)-2-[[2-[[(2S)-2-[[2-[[(2S)-2-[[(2S)-2-[[(2R)-2-[[(2S,3S)-2-[[(2R)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[2-[[(2S)-2-[[(2R)-2-[[2-[[2-[[2-[(2-amino-1-hydroxyethylidene)amino]-3-carboxy-1-hydroxypropylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxybutylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1,5-dihydroxy-5-iminopentylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxybutylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxyethylidene]amino]hexanoic acid Chemical compound C[C@@H]([C@@H](C(=N[C@@H](CS)C(=N[C@@H](C)C(=N[C@@H](CO)C(=NCC(=N[C@@H](CCC(=N)O)C(=NC(CS)C(=N[C@H]([C@H](C)O)C(=N[C@H](CS)C(=N[C@H](CO)C(=NCC(=N[C@H](CS)C(=NCC(=N[C@H](CCCCN)C(=O)O)O)O)O)O)O)O)O)O)O)O)O)O)O)N=C([C@H](CS)N=C([C@H](CO)N=C([C@H](CO)N=C([C@H](C)N=C(CN=C([C@H](CO)N=C([C@H](CS)N=C(CN=C(C(CS)N=C(C(CC(=O)O)N=C(CN)O)O)O)O)O)O)O)O)O)O)O)O DIGQNXIGRZPYDK-WKSCXVIASA-N 0.000 description 1
- NEMRTLVVBHEBLV-KGJVWPDLSA-N (2R,3S,4R,5S,6S)-2-fluoro-6-methyloxane-3,4,5-triol Chemical compound C[C@@H]1O[C@H](F)[C@@H](O)[C@H](O)[C@@H]1O NEMRTLVVBHEBLV-KGJVWPDLSA-N 0.000 description 1
- WHVNYMMWPUHYES-LECHCGJUSA-N (2r,3r,4s,5r)-2-fluorooxane-3,4,5-triol Chemical compound O[C@@H]1CO[C@H](F)[C@H](O)[C@H]1O WHVNYMMWPUHYES-LECHCGJUSA-N 0.000 description 1
- ATMYEINZLWEOQU-PHYPRBDBSA-N (2r,3r,4s,5r,6r)-2-fluoro-6-(hydroxymethyl)oxane-3,4,5-triol Chemical compound OC[C@H]1O[C@H](F)[C@H](O)[C@@H](O)[C@H]1O ATMYEINZLWEOQU-PHYPRBDBSA-N 0.000 description 1
- ATMYEINZLWEOQU-DVKNGEFBSA-N (2r,3r,4s,5s,6r)-2-fluoro-6-(hydroxymethyl)oxane-3,4,5-triol Chemical compound OC[C@H]1O[C@H](F)[C@H](O)[C@@H](O)[C@@H]1O ATMYEINZLWEOQU-DVKNGEFBSA-N 0.000 description 1
- ATMYEINZLWEOQU-PQMKYFCFSA-N (2r,3s,4s,5s,6r)-2-fluoro-6-(hydroxymethyl)oxane-3,4,5-triol Chemical compound OC[C@H]1O[C@H](F)[C@@H](O)[C@@H](O)[C@@H]1O ATMYEINZLWEOQU-PQMKYFCFSA-N 0.000 description 1
- KYBXNPIASYUWLN-WUCPZUCCSA-N (2s)-5-hydroxypyrrolidine-2-carboxylic acid Chemical compound OC1CC[C@@H](C(O)=O)N1 KYBXNPIASYUWLN-WUCPZUCCSA-N 0.000 description 1
- WHVNYMMWPUHYES-KKQCNMDGSA-N (2s,3r,4s,5r)-2-fluorooxane-3,4,5-triol Chemical compound O[C@@H]1CO[C@@H](F)[C@H](O)[C@H]1O WHVNYMMWPUHYES-KKQCNMDGSA-N 0.000 description 1
- ATMYEINZLWEOQU-FPRJBGLDSA-N (2s,3r,4s,5r,6r)-2-fluoro-6-(hydroxymethyl)oxane-3,4,5-triol Chemical compound OC[C@H]1O[C@@H](F)[C@H](O)[C@@H](O)[C@H]1O ATMYEINZLWEOQU-FPRJBGLDSA-N 0.000 description 1
- ATMYEINZLWEOQU-VFUOTHLCSA-N (2s,3r,4s,5s,6r)-2-fluoro-6-(hydroxymethyl)oxane-3,4,5-triol Chemical compound OC[C@H]1O[C@@H](F)[C@H](O)[C@@H](O)[C@@H]1O ATMYEINZLWEOQU-VFUOTHLCSA-N 0.000 description 1
- NEMRTLVVBHEBLV-SXUWKVJYSA-N (2s,3s,4r,5s,6s)-2-fluoro-6-methyloxane-3,4,5-triol Chemical compound C[C@@H]1O[C@@H](F)[C@@H](O)[C@H](O)[C@@H]1O NEMRTLVVBHEBLV-SXUWKVJYSA-N 0.000 description 1
- ATMYEINZLWEOQU-RWOPYEJCSA-N (2s,3s,4s,5s,6r)-2-fluoro-6-(hydroxymethyl)oxane-3,4,5-triol Chemical compound OC[C@H]1O[C@@H](F)[C@@H](O)[C@@H](O)[C@@H]1O ATMYEINZLWEOQU-RWOPYEJCSA-N 0.000 description 1
- VCOPTHOUUNAYKQ-WBTCAYNUSA-N (3s)-3,6-diamino-n-[[(2s,5s,8e,11s,15s)-15-amino-11-[(6r)-2-amino-1,4,5,6-tetrahydropyrimidin-6-yl]-8-[(carbamoylamino)methylidene]-2-(hydroxymethyl)-3,6,9,12,16-pentaoxo-1,4,7,10,13-pentazacyclohexadec-5-yl]methyl]hexanamide;(3s)-3,6-diamino-n-[[(2s,5s,8 Chemical compound N1C(=O)\C(=C/NC(N)=O)NC(=O)[C@H](CNC(=O)C[C@@H](N)CCCN)NC(=O)[C@H](C)NC(=O)[C@@H](N)CNC(=O)[C@@H]1[C@@H]1NC(N)=NCC1.N1C(=O)\C(=C/NC(N)=O)NC(=O)[C@H](CNC(=O)C[C@@H](N)CCCN)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CNC(=O)[C@@H]1[C@@H]1NC(N)=NCC1 VCOPTHOUUNAYKQ-WBTCAYNUSA-N 0.000 description 1
- DEQANNDTNATYII-OULOTJBUSA-N (4r,7s,10s,13r,16s,19r)-10-(4-aminobutyl)-19-[[(2r)-2-amino-3-phenylpropanoyl]amino]-16-benzyl-n-[(2r,3r)-1,3-dihydroxybutan-2-yl]-7-[(1r)-1-hydroxyethyl]-13-(1h-indol-3-ylmethyl)-6,9,12,15,18-pentaoxo-1,2-dithia-5,8,11,14,17-pentazacycloicosane-4-carboxa Chemical compound C([C@@H](N)C(=O)N[C@H]1CSSC[C@H](NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](CC=2C3=CC=CC=C3NC=2)NC(=O)[C@H](CC=2C=CC=CC=2)NC1=O)C(=O)N[C@H](CO)[C@H](O)C)C1=CC=CC=C1 DEQANNDTNATYII-OULOTJBUSA-N 0.000 description 1
- XIYOPDCBBDCGOE-IWVLMIASSA-N (4s,4ar,5s,5ar,12ar)-4-(dimethylamino)-1,5,10,11,12a-pentahydroxy-6-methylidene-3,12-dioxo-4,4a,5,5a-tetrahydrotetracene-2-carboxamide Chemical compound C=C1C2=CC=CC(O)=C2C(O)=C2[C@@H]1[C@H](O)[C@H]1[C@H](N(C)C)C(=O)C(C(N)=O)=C(O)[C@@]1(O)C2=O XIYOPDCBBDCGOE-IWVLMIASSA-N 0.000 description 1
- SGKRLCUYIXIAHR-AKNGSSGZSA-N (4s,4ar,5s,5ar,6r,12ar)-4-(dimethylamino)-1,5,10,11,12a-pentahydroxy-6-methyl-3,12-dioxo-4a,5,5a,6-tetrahydro-4h-tetracene-2-carboxamide Chemical compound C1=CC=C2[C@H](C)[C@@H]([C@H](O)[C@@H]3[C@](C(O)=C(C(N)=O)C(=O)[C@H]3N(C)C)(O)C3=O)C3=C(O)C2=C1O SGKRLCUYIXIAHR-AKNGSSGZSA-N 0.000 description 1
- FFTVPQUHLQBXQZ-KVUCHLLUSA-N (4s,4as,5ar,12ar)-4,7-bis(dimethylamino)-1,10,11,12a-tetrahydroxy-3,12-dioxo-4a,5,5a,6-tetrahydro-4h-tetracene-2-carboxamide Chemical compound C1C2=C(N(C)C)C=CC(O)=C2C(O)=C2[C@@H]1C[C@H]1[C@H](N(C)C)C(=O)C(C(N)=O)=C(O)[C@@]1(O)C2=O FFTVPQUHLQBXQZ-KVUCHLLUSA-N 0.000 description 1
- UNBRKDKAWYKMIV-QWQRMKEZSA-N (6aR,9R)-N-[(2S)-1-hydroxybutan-2-yl]-7-methyl-6,6a,8,9-tetrahydro-4H-indolo[4,3-fg]quinoline-9-carboxamide Chemical compound C1=CC(C=2[C@H](N(C)C[C@@H](C=2)C(=O)N[C@H](CO)CC)C2)=C3C2=CNC3=C1 UNBRKDKAWYKMIV-QWQRMKEZSA-N 0.000 description 1
- GMVPRGQOIOIIMI-UHFFFAOYSA-N (8R,11R,12R,13E,15S)-11,15-Dihydroxy-9-oxo-13-prostenoic acid Natural products CCCCCC(O)C=CC1C(O)CC(=O)C1CCCCCCC(O)=O GMVPRGQOIOIIMI-UHFFFAOYSA-N 0.000 description 1
- VMSLCPKYRPDHLN-UHFFFAOYSA-N (R)-Humulone Chemical compound CC(C)CC(=O)C1=C(O)C(CC=C(C)C)=C(O)C(O)(CC=C(C)C)C1=O VMSLCPKYRPDHLN-UHFFFAOYSA-N 0.000 description 1
- IAKHMKGGTNLKSZ-INIZCTEOSA-N (S)-colchicine Chemical compound C1([C@@H](NC(C)=O)CC2)=CC(=O)C(OC)=CC=C1C1=C2C=C(OC)C(OC)=C1OC IAKHMKGGTNLKSZ-INIZCTEOSA-N 0.000 description 1
- TWBNMYSKRDRHAT-RCWTXCDDSA-N (S)-timolol hemihydrate Chemical compound O.CC(C)(C)NC[C@H](O)COC1=NSN=C1N1CCOCC1.CC(C)(C)NC[C@H](O)COC1=NSN=C1N1CCOCC1 TWBNMYSKRDRHAT-RCWTXCDDSA-N 0.000 description 1
- WSPOMRSOLSGNFJ-AUWJEWJLSA-N (Z)-chlorprothixene Chemical compound C1=C(Cl)C=C2C(=C/CCN(C)C)\C3=CC=CC=C3SC2=C1 WSPOMRSOLSGNFJ-AUWJEWJLSA-N 0.000 description 1
- UKAUYVFTDYCKQA-UHFFFAOYSA-N -2-Amino-4-hydroxybutanoic acid Natural products OC(=O)C(N)CCO UKAUYVFTDYCKQA-UHFFFAOYSA-N 0.000 description 1
- VILFTWLXLYIEMV-UHFFFAOYSA-N 1,5-difluoro-2,4-dinitrobenzene Chemical compound [O-][N+](=O)C1=CC([N+]([O-])=O)=C(F)C=C1F VILFTWLXLYIEMV-UHFFFAOYSA-N 0.000 description 1
- REMUISGGSZKZTD-UHFFFAOYSA-N 1-(2,5-dioxopyrrolidin-1-yl)-4-[[(2-iodoacetyl)amino]methyl]cyclohexane-1-carboxylic acid Chemical compound O=C1CCC(=O)N1C1(C(=O)O)CCC(CNC(=O)CI)CC1 REMUISGGSZKZTD-UHFFFAOYSA-N 0.000 description 1
- ASOKPJOREAFHNY-UHFFFAOYSA-N 1-Hydroxybenzotriazole Chemical class C1=CC=C2N(O)N=NC2=C1 ASOKPJOREAFHNY-UHFFFAOYSA-N 0.000 description 1
- UTRLJOWPWILGSB-UHFFFAOYSA-N 1-[(2,5-dioxopyrrol-1-yl)methoxymethyl]pyrrole-2,5-dione Chemical compound O=C1C=CC(=O)N1COCN1C(=O)C=CC1=O UTRLJOWPWILGSB-UHFFFAOYSA-N 0.000 description 1
- OZOMQRBLCMDCEG-CHHVJCJISA-N 1-[(z)-[5-(4-nitrophenyl)furan-2-yl]methylideneamino]imidazolidine-2,4-dione Chemical compound C1=CC([N+](=O)[O-])=CC=C1C(O1)=CC=C1\C=N/N1C(=O)NC(=O)C1 OZOMQRBLCMDCEG-CHHVJCJISA-N 0.000 description 1
- UFFVWIGGYXLXPC-UHFFFAOYSA-N 1-[2-(2,5-dioxopyrrol-1-yl)phenyl]pyrrole-2,5-dione Chemical compound O=C1C=CC(=O)N1C1=CC=CC=C1N1C(=O)C=CC1=O UFFVWIGGYXLXPC-UHFFFAOYSA-N 0.000 description 1
- IPJGAEWUPXWFPL-UHFFFAOYSA-N 1-[3-(2,5-dioxopyrrol-1-yl)phenyl]pyrrole-2,5-dione Chemical compound O=C1C=CC(=O)N1C1=CC=CC(N2C(C=CC2=O)=O)=C1 IPJGAEWUPXWFPL-UHFFFAOYSA-N 0.000 description 1
- FUWZBLSXACKFQX-IBGZPJMESA-N 1-[4-[ethyl-[(2s)-1-(4-methoxyphenyl)propan-2-yl]amino]butanoyl]-n,n-dimethylpiperidine-4-carboxamide Chemical compound CCN([C@@H](C)CC=1C=CC(OC)=CC=1)CCCC(=O)N1CCC(C(=O)N(C)C)CC1 FUWZBLSXACKFQX-IBGZPJMESA-N 0.000 description 1
- DWBCXGZVCAKDGO-UHFFFAOYSA-N 1-azido-4-[(4-azidophenyl)disulfanyl]benzene Chemical compound C1=CC(N=[N+]=[N-])=CC=C1SSC1=CC=C(N=[N+]=[N-])C=C1 DWBCXGZVCAKDGO-UHFFFAOYSA-N 0.000 description 1
- LEBVLXFERQHONN-UHFFFAOYSA-N 1-butyl-N-(2,6-dimethylphenyl)piperidine-2-carboxamide Chemical compound CCCCN1CCCCC1C(=O)NC1=C(C)C=CC=C1C LEBVLXFERQHONN-UHFFFAOYSA-N 0.000 description 1
- VCRPKWLNHWPCSR-UHFFFAOYSA-N 1-diazonio-3-(4-nitrophenoxy)-3-oxoprop-1-en-2-olate Chemical compound [O-][N+](=O)C1=CC=C(OC(=O)C(=O)C=[N+]=[N-])C=C1 VCRPKWLNHWPCSR-UHFFFAOYSA-N 0.000 description 1
- MBDUIEKYVPVZJH-UHFFFAOYSA-N 1-ethylsulfonylethane Chemical compound CCS(=O)(=O)CC MBDUIEKYVPVZJH-UHFFFAOYSA-N 0.000 description 1
- VSNHCAURESNICA-NJFSPNSNSA-N 1-oxidanylurea Chemical compound N[14C](=O)NO VSNHCAURESNICA-NJFSPNSNSA-N 0.000 description 1
- CFJMRBQWBDQYMK-UHFFFAOYSA-N 1-phenyl-1-cyclopentanecarboxylic acid 2-[2-(diethylamino)ethoxy]ethyl ester Chemical compound C=1C=CC=CC=1C1(C(=O)OCCOCCN(CC)CC)CCCC1 CFJMRBQWBDQYMK-UHFFFAOYSA-N 0.000 description 1
- MVMSCBBUIHUTGJ-UHFFFAOYSA-N 10108-97-1 Natural products C1=2NC(N)=NC(=O)C=2N=CN1C(C(C1O)O)OC1COP(O)(=O)OP(O)(=O)OC1OC(CO)C(O)C(O)C1O MVMSCBBUIHUTGJ-UHFFFAOYSA-N 0.000 description 1
- FUFLCEKSBBHCMO-UHFFFAOYSA-N 11-dehydrocorticosterone Natural products O=C1CCC2(C)C3C(=O)CC(C)(C(CC4)C(=O)CO)C4C3CCC2=C1 FUFLCEKSBBHCMO-UHFFFAOYSA-N 0.000 description 1
- BFPYWIDHMRZLRN-UHFFFAOYSA-N 17alpha-ethynyl estradiol Natural products OC1=CC=C2C3CCC(C)(C(CC4)(O)C#C)C4C3CCC2=C1 BFPYWIDHMRZLRN-UHFFFAOYSA-N 0.000 description 1
- GCKMFJBGXUYNAG-UHFFFAOYSA-N 17alpha-methyltestosterone Natural products C1CC2=CC(=O)CCC2(C)C2C1C1CCC(C)(O)C1(C)CC2 GCKMFJBGXUYNAG-UHFFFAOYSA-N 0.000 description 1
- VOXZDWNPVJITMN-ZBRFXRBCSA-N 17β-estradiol Chemical compound OC1=CC=C2[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 VOXZDWNPVJITMN-ZBRFXRBCSA-N 0.000 description 1
- NBSLIHUMUUEJER-UHFFFAOYSA-N 1h-imidazol-2-yl formate Chemical class O=COC1=NC=CN1 NBSLIHUMUUEJER-UHFFFAOYSA-N 0.000 description 1
- VGONTNSXDCQUGY-RRKCRQDMSA-N 2'-deoxyinosine Chemical group C1[C@H](O)[C@@H](CO)O[C@H]1N1C(N=CNC2=O)=C2N=C1 VGONTNSXDCQUGY-RRKCRQDMSA-N 0.000 description 1
- ZMYAKSMZTVWUJB-UHFFFAOYSA-N 2,3-dibromopropanoic acid Chemical compound OC(=O)C(Br)CBr ZMYAKSMZTVWUJB-UHFFFAOYSA-N 0.000 description 1
- YAQBDPUSNJBCNO-UHFFFAOYSA-N 2,5-bis(bromomethyl)benzenesulfonic acid Chemical compound OS(=O)(=O)C1=CC(CBr)=CC=C1CBr YAQBDPUSNJBCNO-UHFFFAOYSA-N 0.000 description 1
- ASNTZYQMIUCEBV-UHFFFAOYSA-N 2,5-dioxo-1-[6-[3-(pyridin-2-yldisulfanyl)propanoylamino]hexanoyloxy]pyrrolidine-3-sulfonic acid Chemical compound O=C1C(S(=O)(=O)O)CC(=O)N1OC(=O)CCCCCNC(=O)CCSSC1=CC=CC=N1 ASNTZYQMIUCEBV-UHFFFAOYSA-N 0.000 description 1
- YYDMSFVTLYEPOH-UHFFFAOYSA-N 2,5-dioxo-1-propanoyloxypyrrolidine-3-sulfonic acid Chemical compound CCC(=O)ON1C(=O)CC(S(O)(=O)=O)C1=O YYDMSFVTLYEPOH-UHFFFAOYSA-N 0.000 description 1
- QZWBOYMQPQVGPM-UHFFFAOYSA-N 2-(1h-indol-2-yl)guanidine Chemical compound C1=CC=C2NC(NC(=N)N)=CC2=C1 QZWBOYMQPQVGPM-UHFFFAOYSA-N 0.000 description 1
- SYEKJCKNTHYWOJ-UHFFFAOYSA-N 2-(2,5-dioxopyrrolidin-1-yl)-2-sulfobutanedioic acid;ethane-1,2-diol Chemical compound OCCO.OC(=O)CC(S(O)(=O)=O)(C(O)=O)N1C(=O)CCC1=O.OC(=O)CC(S(O)(=O)=O)(C(O)=O)N1C(=O)CCC1=O SYEKJCKNTHYWOJ-UHFFFAOYSA-N 0.000 description 1
- JWTOSPIRLDBBOA-UHFFFAOYSA-N 2-(2,5-dioxopyrrolidin-1-yl)-6-[(2-iodoacetyl)amino]hexanoic acid Chemical compound ICC(=O)NCCCCC(C(=O)O)N1C(=O)CCC1=O JWTOSPIRLDBBOA-UHFFFAOYSA-N 0.000 description 1
- YDLZAUQGOOEOBO-UHFFFAOYSA-N 2-(2,5-dioxopyrrolidin-1-yl)-6-[6-[(2-iodoacetyl)amino]hexanoylamino]hexanoic acid Chemical compound ICC(=O)NCCCCCC(=O)NCCCCC(C(=O)O)N1C(=O)CCC1=O YDLZAUQGOOEOBO-UHFFFAOYSA-N 0.000 description 1
- SGTNSNPWRIOYBX-UHFFFAOYSA-N 2-(3,4-dimethoxyphenyl)-5-{[2-(3,4-dimethoxyphenyl)ethyl](methyl)amino}-2-(propan-2-yl)pentanenitrile Chemical compound C1=C(OC)C(OC)=CC=C1CCN(C)CCCC(C#N)(C(C)C)C1=CC=C(OC)C(OC)=C1 SGTNSNPWRIOYBX-UHFFFAOYSA-N 0.000 description 1
- NXOXTPQHYPYNJO-UHFFFAOYSA-N 2-[(2-carboxyacetyl)amino]-3-iodo-6-[(4-iodophenyl)diazenyl]benzoic acid Chemical compound OC(=O)CC(=O)NC1=C(I)C=CC(N=NC=2C=CC(I)=CC=2)=C1C(O)=O NXOXTPQHYPYNJO-UHFFFAOYSA-N 0.000 description 1
- YGDVXSDNEFDTGV-UHFFFAOYSA-N 2-[6-[bis(carboxymethyl)amino]hexyl-(carboxymethyl)amino]acetic acid Chemical compound OC(=O)CN(CC(O)=O)CCCCCCN(CC(O)=O)CC(O)=O YGDVXSDNEFDTGV-UHFFFAOYSA-N 0.000 description 1
- YMJMZFPZRVMNCH-FMIVXFBMSA-N 2-[methyl-[(e)-3-phenylprop-2-enyl]amino]-1-phenylpropan-1-ol Chemical compound C=1C=CC=CC=1/C=C/CN(C)C(C)C(O)C1=CC=CC=C1 YMJMZFPZRVMNCH-FMIVXFBMSA-N 0.000 description 1
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 1
- 125000000979 2-amino-2-oxoethyl group Chemical group [H]C([*])([H])C(=O)N([H])[H] 0.000 description 1
- XVOQMYDCUKPPIP-UHFFFAOYSA-N 2-bromo-n-[2-[(2-bromoacetyl)amino]-3-phenylpropyl]acetamide Chemical compound BrCC(=O)NCC(NC(=O)CBr)CC1=CC=CC=C1 XVOQMYDCUKPPIP-UHFFFAOYSA-N 0.000 description 1
- SGUAFYQXFOLMHL-UHFFFAOYSA-N 2-hydroxy-5-{1-hydroxy-2-[(4-phenylbutan-2-yl)amino]ethyl}benzamide Chemical compound C=1C=C(O)C(C(N)=O)=CC=1C(O)CNC(C)CCC1=CC=CC=C1 SGUAFYQXFOLMHL-UHFFFAOYSA-N 0.000 description 1
- HKWBUHMGDKKEGW-UHFFFAOYSA-N 2-isocyanato-4-isothiocyanato-1-methylbenzene Chemical compound CC1=CC=C(N=C=S)C=C1N=C=O HKWBUHMGDKKEGW-UHFFFAOYSA-N 0.000 description 1
- ILYSAKHOYBPSPC-UHFFFAOYSA-N 2-phenylbenzoic acid Chemical class OC(=O)C1=CC=CC=C1C1=CC=CC=C1 ILYSAKHOYBPSPC-UHFFFAOYSA-N 0.000 description 1
- ZSLUVFAKFWKJRC-IGMARMGPSA-N 232Th Chemical compound [232Th] ZSLUVFAKFWKJRC-IGMARMGPSA-N 0.000 description 1
- VYVKHNNGDFVQGA-UHFFFAOYSA-N 3,4-dimethoxybenzoic acid 4-[ethyl-[1-(4-methoxyphenyl)propan-2-yl]amino]butyl ester Chemical compound C=1C=C(OC)C=CC=1CC(C)N(CC)CCCCOC(=O)C1=CC=C(OC)C(OC)=C1 VYVKHNNGDFVQGA-UHFFFAOYSA-N 0.000 description 1
- JMUAKWNHKQBPGJ-UHFFFAOYSA-N 3-(pyridin-2-yldisulfanyl)-n-[4-[3-(pyridin-2-yldisulfanyl)propanoylamino]butyl]propanamide Chemical compound C=1C=CC=NC=1SSCCC(=O)NCCCCNC(=O)CCSSC1=CC=CC=N1 JMUAKWNHKQBPGJ-UHFFFAOYSA-N 0.000 description 1
- HVCOBJNICQPDBP-UHFFFAOYSA-N 3-[3-[3,5-dihydroxy-6-methyl-4-(3,4,5-trihydroxy-6-methyloxan-2-yl)oxyoxan-2-yl]oxydecanoyloxy]decanoic acid;hydrate Chemical compound O.OC1C(OC(CC(=O)OC(CCCCCCC)CC(O)=O)CCCCCCC)OC(C)C(O)C1OC1C(O)C(O)C(O)C(C)O1 HVCOBJNICQPDBP-UHFFFAOYSA-N 0.000 description 1
- DLYIXSSECJQHOL-UHFFFAOYSA-N 3-diazo-2-oxopropanamide Chemical class NC(=O)C(=O)C=[N+]=[N-] DLYIXSSECJQHOL-UHFFFAOYSA-N 0.000 description 1
- MZJVXDGQPDYGBY-UHFFFAOYSA-N 3-diazo-2-oxopropanoic acid Chemical class [N+](=[N-])=CC(C(=O)O)=O MZJVXDGQPDYGBY-UHFFFAOYSA-N 0.000 description 1
- YSCNMFDFYJUPEF-OWOJBTEDSA-N 4,4'-diisothiocyano-trans-stilbene-2,2'-disulfonic acid Chemical compound OS(=O)(=O)C1=CC(N=C=S)=CC=C1\C=C\C1=CC=C(N=C=S)C=C1S(O)(=O)=O YSCNMFDFYJUPEF-OWOJBTEDSA-N 0.000 description 1
- LZKGFGLOQNSMBS-UHFFFAOYSA-N 4,5,6-trichlorotriazine Chemical compound ClC1=NN=NC(Cl)=C1Cl LZKGFGLOQNSMBS-UHFFFAOYSA-N 0.000 description 1
- WEQPBCSPRXFQQS-UHFFFAOYSA-N 4,5-dihydro-1,2-oxazole Chemical group C1CC=NO1 WEQPBCSPRXFQQS-UHFFFAOYSA-N 0.000 description 1
- OSWFIVFLDKOXQC-UHFFFAOYSA-N 4-(3-methoxyphenyl)aniline Chemical compound COC1=CC=CC(C=2C=CC(N)=CC=2)=C1 OSWFIVFLDKOXQC-UHFFFAOYSA-N 0.000 description 1
- BMUKKTUHUDJSNZ-UHFFFAOYSA-N 4-[1-hydroxy-2-(1-phenoxypropan-2-ylamino)propyl]phenol Chemical compound C=1C=C(O)C=CC=1C(O)C(C)NC(C)COC1=CC=CC=C1 BMUKKTUHUDJSNZ-UHFFFAOYSA-N 0.000 description 1
- PTGXAUBQBSGPKF-UHFFFAOYSA-N 4-[1-hydroxy-2-(4-phenylbutan-2-ylamino)propyl]phenol Chemical compound C=1C=C(O)C=CC=1C(O)C(C)NC(C)CCC1=CC=CC=C1 PTGXAUBQBSGPKF-UHFFFAOYSA-N 0.000 description 1
- DAUMUVRLMYMPLB-UHFFFAOYSA-N 4-hydroxybenzene-1,3-disulfonyl chloride Chemical compound OC1=CC=C(S(Cl)(=O)=O)C=C1S(Cl)(=O)=O DAUMUVRLMYMPLB-UHFFFAOYSA-N 0.000 description 1
- JLJZRAUDCHWQPS-NYONGVCJSA-N 4-oxo-n-[(3s,4r,5s,6r)-2,4,5-trihydroxy-6-(hydroxymethyl)oxan-3-yl]pentanamide Chemical compound CC(=O)CCC(=O)N[C@@H]1C(O)O[C@H](CO)[C@@H](O)[C@@H]1O JLJZRAUDCHWQPS-NYONGVCJSA-N 0.000 description 1
- 229940117976 5-hydroxylysine Drugs 0.000 description 1
- VHRSUDSXCMQTMA-PJHHCJLFSA-N 6alpha-methylprednisolone Chemical compound C([C@@]12C)=CC(=O)C=C1[C@@H](C)C[C@@H]1[C@@H]2[C@@H](O)C[C@]2(C)[C@@](O)(C(=O)CO)CC[C@H]21 VHRSUDSXCMQTMA-PJHHCJLFSA-N 0.000 description 1
- STQGQHZAVUOBTE-UHFFFAOYSA-N 7-Cyan-hept-2t-en-4,6-diinsaeure Natural products C1=2C(O)=C3C(=O)C=4C(OC)=CC=CC=4C(=O)C3=C(O)C=2CC(O)(C(C)=O)CC1OC1CC(N)C(O)C(C)O1 STQGQHZAVUOBTE-UHFFFAOYSA-N 0.000 description 1
- 229930008281 A03AD01 - Papaverine Natural products 0.000 description 1
- 229930000680 A04AD01 - Scopolamine Natural products 0.000 description 1
- DLFVBJFMPXGRIB-UHFFFAOYSA-N Acetamide Chemical class CC(N)=O DLFVBJFMPXGRIB-UHFFFAOYSA-N 0.000 description 1
- QTBSBXVTEAMEQO-UHFFFAOYSA-M Acetate Chemical compound CC([O-])=O QTBSBXVTEAMEQO-UHFFFAOYSA-M 0.000 description 1
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 1
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 1
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 1
- 101710098620 Alpha-1,2-fucosyltransferase Proteins 0.000 description 1
- 102100022622 Alpha-1,3-mannosyl-glycoprotein 2-beta-N-acetylglucosaminyltransferase Human genes 0.000 description 1
- 102100031970 Alpha-N-acetylgalactosaminide alpha-2,6-sialyltransferase 2 Human genes 0.000 description 1
- 102100031971 Alpha-N-acetylgalactosaminide alpha-2,6-sialyltransferase 3 Human genes 0.000 description 1
- ITPDYQOUSLNIHG-UHFFFAOYSA-N Amiodarone hydrochloride Chemical compound [Cl-].CCCCC=1OC2=CC=CC=C2C=1C(=O)C1=CC(I)=C(OCC[NH+](CC)CC)C(I)=C1 ITPDYQOUSLNIHG-UHFFFAOYSA-N 0.000 description 1
- 229920000856 Amylose Polymers 0.000 description 1
- 108010024976 Asparaginase Proteins 0.000 description 1
- 102000015790 Asparaginase Human genes 0.000 description 1
- 201000001320 Atherosclerosis Diseases 0.000 description 1
- 229930003347 Atropine Natural products 0.000 description 1
- 238000012935 Averaging Methods 0.000 description 1
- 108090001008 Avidin Proteins 0.000 description 1
- 241000194110 Bacillus sp. (in: Bacteria) Species 0.000 description 1
- 108010077805 Bacterial Proteins Proteins 0.000 description 1
- 102100029963 Beta-galactoside alpha-2,6-sialyltransferase 2 Human genes 0.000 description 1
- 101710136188 Beta-galactoside alpha-2,6-sialyltransferase 2 Proteins 0.000 description 1
- 241001436672 Bhatia Species 0.000 description 1
- 206010006187 Breast cancer Diseases 0.000 description 1
- CPELXLSAUQHCOX-UHFFFAOYSA-M Bromide Chemical compound [Br-] CPELXLSAUQHCOX-UHFFFAOYSA-M 0.000 description 1
- COVZYZSDYWQREU-UHFFFAOYSA-N Busulfan Chemical compound CS(=O)(=O)OCCCCOS(C)(=O)=O COVZYZSDYWQREU-UHFFFAOYSA-N 0.000 description 1
- NDQATBHZAHUEFM-UHFFFAOYSA-N COC(CCOCOCCC(OC)=N)=N Chemical compound COC(CCOCOCCC(OC)=N)=N NDQATBHZAHUEFM-UHFFFAOYSA-N 0.000 description 1
- KORNTPPJEAJQIU-KJXAQDMKSA-N Cabaser Chemical compound C1=CC([C@H]2C[C@H](CN(CC=C)[C@@H]2C2)C(=O)N(CCCN(C)C)C(=O)NCC)=C3C2=CNC3=C1 KORNTPPJEAJQIU-KJXAQDMKSA-N 0.000 description 1
- 206010006895 Cachexia Diseases 0.000 description 1
- 241000202785 Calyptronoma Species 0.000 description 1
- 108010065839 Capreomycin Proteins 0.000 description 1
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 1
- BVKZGUZCCUSVTD-UHFFFAOYSA-L Carbonate Chemical compound [O-]C([O-])=O BVKZGUZCCUSVTD-UHFFFAOYSA-L 0.000 description 1
- 102000014914 Carrier Proteins Human genes 0.000 description 1
- 108010078791 Carrier Proteins Proteins 0.000 description 1
- GHXZTYHSJHQHIJ-UHFFFAOYSA-N Chlorhexidine Chemical compound C=1C=C(Cl)C=CC=1NC(N)=NC(N)=NCCCCCCN=C(N)N=C(N)NC1=CC=C(Cl)C=C1 GHXZTYHSJHQHIJ-UHFFFAOYSA-N 0.000 description 1
- RKWGIWYCVPQPMF-UHFFFAOYSA-N Chloropropamide Chemical compound CCCNC(=O)NS(=O)(=O)C1=CC=C(Cl)C=C1 RKWGIWYCVPQPMF-UHFFFAOYSA-N 0.000 description 1
- JZUFKLXOESDKRF-UHFFFAOYSA-N Chlorothiazide Chemical compound C1=C(Cl)C(S(=O)(=O)N)=CC2=C1NCNS2(=O)=O JZUFKLXOESDKRF-UHFFFAOYSA-N 0.000 description 1
- ZCKAMNXUHHNZLN-UHFFFAOYSA-N Chlorphentermine Chemical compound CC(C)(N)CC1=CC=C(Cl)C=C1 ZCKAMNXUHHNZLN-UHFFFAOYSA-N 0.000 description 1
- 239000004099 Chlortetracycline Substances 0.000 description 1
- VYZAMTAEIAYCRO-UHFFFAOYSA-N Chromium Chemical compound [Cr] VYZAMTAEIAYCRO-UHFFFAOYSA-N 0.000 description 1
- 208000006545 Chronic Obstructive Pulmonary Disease Diseases 0.000 description 1
- GJSURZIOUXUGAL-UHFFFAOYSA-N Clonidine Chemical compound ClC1=CC=CC(Cl)=C1NC1=NCCN1 GJSURZIOUXUGAL-UHFFFAOYSA-N 0.000 description 1
- GUTLYIVDDKVIGB-OUBTZVSYSA-N Cobalt-60 Chemical compound [60Co] GUTLYIVDDKVIGB-OUBTZVSYSA-N 0.000 description 1
- 101100007328 Cocos nucifera COS-1 gene Proteins 0.000 description 1
- MFYSYFVPBJMHGN-ZPOLXVRWSA-N Cortisone Chemical compound O=C1CC[C@]2(C)[C@H]3C(=O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 MFYSYFVPBJMHGN-ZPOLXVRWSA-N 0.000 description 1
- MFYSYFVPBJMHGN-UHFFFAOYSA-N Cortisone Natural products O=C1CCC2(C)C3C(=O)CC(C)(C(CC4)(O)C(=O)CO)C4C3CCC2=C1 MFYSYFVPBJMHGN-UHFFFAOYSA-N 0.000 description 1
- 229920000858 Cyclodextrin Polymers 0.000 description 1
- XDTMQSROBMDMFD-UHFFFAOYSA-N Cyclohexane Chemical compound C1CCCCC1 XDTMQSROBMDMFD-UHFFFAOYSA-N 0.000 description 1
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 description 1
- PMATZTZNYRCHOR-CGLBZJNRSA-N Cyclosporin A Chemical compound CC[C@@H]1NC(=O)[C@H]([C@H](O)[C@H](C)C\C=C\C)N(C)C(=O)[C@H](C(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)N(C)C(=O)CN(C)C1=O PMATZTZNYRCHOR-CGLBZJNRSA-N 0.000 description 1
- 229930105110 Cyclosporin A Natural products 0.000 description 1
- 108010036949 Cyclosporine Proteins 0.000 description 1
- 102100035149 Cytosolic endo-beta-N-acetylglucosaminidase Human genes 0.000 description 1
- 101710112752 Cytotoxin Proteins 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 1
- 102000053602 DNA Human genes 0.000 description 1
- 230000009946 DNA mutation Effects 0.000 description 1
- 239000003155 DNA primer Substances 0.000 description 1
- 108010092160 Dactinomycin Proteins 0.000 description 1
- 108010000437 Deamino Arginine Vasopressin Proteins 0.000 description 1
- HCYAFALTSJYZDH-UHFFFAOYSA-N Desimpramine Chemical compound C1CC2=CC=CC=C2N(CCCNC)C2=CC=CC=C21 HCYAFALTSJYZDH-UHFFFAOYSA-N 0.000 description 1
- CETBSQOFQKLHHZ-UHFFFAOYSA-N Diethyl disulfide Chemical compound CCSSCC CETBSQOFQKLHHZ-UHFFFAOYSA-N 0.000 description 1
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 1
- 108010016626 Dipeptides Proteins 0.000 description 1
- JRWZLRBJNMZMFE-UHFFFAOYSA-N Dobutamine Chemical compound C=1C=C(O)C(O)=CC=1CCNC(C)CCC1=CC=C(O)C=C1 JRWZLRBJNMZMFE-UHFFFAOYSA-N 0.000 description 1
- 108700035678 EC 2.4.1.45 Proteins 0.000 description 1
- 238000002965 ELISA Methods 0.000 description 1
- MBYXEBXZARTUSS-QLWBXOBMSA-N Emetamine Natural products O(C)c1c(OC)cc2c(c(C[C@@H]3[C@H](CC)CN4[C@H](c5c(cc(OC)c(OC)c5)CC4)C3)ncc2)c1 MBYXEBXZARTUSS-QLWBXOBMSA-N 0.000 description 1
- 108010061435 Enalapril Proteins 0.000 description 1
- 101710144190 Endo-beta-N-acetylglucosaminidase Proteins 0.000 description 1
- BRLQWZUYTZBJKN-UHFFFAOYSA-N Epichlorohydrin Chemical compound ClCC1CO1 BRLQWZUYTZBJKN-UHFFFAOYSA-N 0.000 description 1
- 101001091269 Escherichia coli Hygromycin-B 4-O-kinase Proteins 0.000 description 1
- 241000701959 Escherichia virus Lambda Species 0.000 description 1
- 108090000371 Esterases Proteins 0.000 description 1
- BFPYWIDHMRZLRN-SLHNCBLASA-N Ethinyl estradiol Chemical compound OC1=CC=C2[C@H]3CC[C@](C)([C@](CC4)(O)C#C)[C@@H]4[C@@H]3CCC2=C1 BFPYWIDHMRZLRN-SLHNCBLASA-N 0.000 description 1
- JOYRKODLDBILNP-UHFFFAOYSA-N Ethyl urethane Chemical compound CCOC(N)=O JOYRKODLDBILNP-UHFFFAOYSA-N 0.000 description 1
- IAYPIBMASNFSPL-UHFFFAOYSA-N Ethylene oxide Chemical compound C1CO1 IAYPIBMASNFSPL-UHFFFAOYSA-N 0.000 description 1
- 108700024394 Exon Proteins 0.000 description 1
- 102000001690 Factor VIII Human genes 0.000 description 1
- 108010054218 Factor VIII Proteins 0.000 description 1
- 208000007984 Female Infertility Diseases 0.000 description 1
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 description 1
- PLDUPXSUYLZYBN-UHFFFAOYSA-N Fluphenazine Chemical compound C1CN(CCO)CCN1CCCN1C2=CC(C(F)(F)F)=CC=C2SC2=CC=CC=C21 PLDUPXSUYLZYBN-UHFFFAOYSA-N 0.000 description 1
- 102000001390 Fructose-Bisphosphate Aldolase Human genes 0.000 description 1
- 108010068561 Fructose-Bisphosphate Aldolase Proteins 0.000 description 1
- 108030004655 Fucosylgalactoside 3-alpha-galactosyltransferases Proteins 0.000 description 1
- 241000233866 Fungi Species 0.000 description 1
- MVMSCBBUIHUTGJ-GDJBGNAASA-N GDP-alpha-D-mannose Chemical compound C([C@H]1O[C@H]([C@@H]([C@@H]1O)O)N1C=2N=C(NC(=O)C=2N=C1)N)OP(O)(=O)OP(O)(=O)O[C@H]1O[C@H](CO)[C@@H](O)[C@H](O)[C@@H]1O MVMSCBBUIHUTGJ-GDJBGNAASA-N 0.000 description 1
- 108010015133 Galactose oxidase Proteins 0.000 description 1
- 241000287828 Gallus gallus Species 0.000 description 1
- 108020004206 Gamma-glutamyltransferase Proteins 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- JRZJKWGQFNTSRN-UHFFFAOYSA-N Geldanamycin Natural products C1C(C)CC(OC)C(O)C(C)C=C(C)C(OC(N)=O)C(OC)CCC=C(C)C(=O)NC2=CC(=O)C(OC)=C1C2=O JRZJKWGQFNTSRN-UHFFFAOYSA-N 0.000 description 1
- 229930182566 Gentamicin Natural products 0.000 description 1
- CEAZRRDELHUEMR-URQXQFDESA-N Gentamicin Chemical compound O1[C@H](C(C)NC)CC[C@@H](N)[C@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](NC)[C@@](C)(O)CO2)O)[C@H](N)C[C@@H]1N CEAZRRDELHUEMR-URQXQFDESA-N 0.000 description 1
- 108010092364 Glucuronosyltransferase Proteins 0.000 description 1
- 102000016354 Glucuronosyltransferase Human genes 0.000 description 1
- 229930186217 Glycolipid Natural products 0.000 description 1
- BLCLNMBMMGCOAS-URPVMXJPSA-N Goserelin Chemical compound C([C@@H](C(=O)N[C@H](COC(C)(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1[C@@H](CCC1)C(=O)NNC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H]1NC(=O)CC1)C1=CC=C(O)C=C1 BLCLNMBMMGCOAS-URPVMXJPSA-N 0.000 description 1
- 108010069236 Goserelin Proteins 0.000 description 1
- 108010026389 Gramicidin Proteins 0.000 description 1
- 229910004373 HOAc Inorganic materials 0.000 description 1
- 241000256244 Heliothis virescens Species 0.000 description 1
- 229920000209 Hexadimethrine bromide Polymers 0.000 description 1
- 239000005057 Hexamethylene diisocyanate Substances 0.000 description 1
- ZTVIKZXZYLEVOL-MCOXGKPRSA-N Homatropine Chemical compound O([C@H]1C[C@H]2CC[C@@H](C1)N2C)C(=O)C(O)C1=CC=CC=C1 ZTVIKZXZYLEVOL-MCOXGKPRSA-N 0.000 description 1
- 101000972916 Homo sapiens Alpha-1,3-mannosyl-glycoprotein 2-beta-N-acetylglucosaminyltransferase Proteins 0.000 description 1
- 101000863898 Homo sapiens CMP-N-acetylneuraminate-beta-1,4-galactoside alpha-2,3-sialyltransferase Proteins 0.000 description 1
- 101001002657 Homo sapiens Interleukin-2 Proteins 0.000 description 1
- 101000766306 Homo sapiens Serotransferrin Proteins 0.000 description 1
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 1
- 102000003918 Hyaluronan Synthases Human genes 0.000 description 1
- 108090000320 Hyaluronan Synthases Proteins 0.000 description 1
- VEXZGXHMUGYJMC-UHFFFAOYSA-N Hydrochloric acid Chemical compound Cl VEXZGXHMUGYJMC-UHFFFAOYSA-N 0.000 description 1
- RKUNBYITZUJHSG-UHFFFAOYSA-N Hyosciamin-hydrochlorid Natural products CN1C(C2)CCC1CC2OC(=O)C(CO)C1=CC=CC=C1 RKUNBYITZUJHSG-UHFFFAOYSA-N 0.000 description 1
- STECJAGHUSJQJN-GAUPFVANSA-N Hyoscine Natural products C1([C@H](CO)C(=O)OC2C[C@@H]3N([C@H](C2)[C@@H]2[C@H]3O2)C)=CC=CC=C1 STECJAGHUSJQJN-GAUPFVANSA-N 0.000 description 1
- 108010093096 Immobilized Enzymes Proteins 0.000 description 1
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 1
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 1
- 206010021928 Infertility female Diseases 0.000 description 1
- 102000004877 Insulin Human genes 0.000 description 1
- 108090001061 Insulin Proteins 0.000 description 1
- 102000006992 Interferon-alpha Human genes 0.000 description 1
- 108010047761 Interferon-alpha Proteins 0.000 description 1
- 108010063738 Interleukins Proteins 0.000 description 1
- 102000015696 Interleukins Human genes 0.000 description 1
- 206010065973 Iron Overload Diseases 0.000 description 1
- 241000588747 Klebsiella pneumoniae Species 0.000 description 1
- WTDRDQBEARUVNC-LURJTMIESA-N L-DOPA Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C(O)=C1 WTDRDQBEARUVNC-LURJTMIESA-N 0.000 description 1
- WTDRDQBEARUVNC-UHFFFAOYSA-N L-Dopa Natural products OC(=O)C(N)CC1=CC=C(O)C(O)=C1 WTDRDQBEARUVNC-UHFFFAOYSA-N 0.000 description 1
- SHZGCJCMOBCMKK-PQMKYFCFSA-N L-Fucose Natural products C[C@H]1O[C@H](O)[C@@H](O)[C@@H](O)[C@@H]1O SHZGCJCMOBCMKK-PQMKYFCFSA-N 0.000 description 1
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 1
- UKAUYVFTDYCKQA-VKHMYHEASA-N L-homoserine Chemical group OC(=O)[C@@H](N)CCO UKAUYVFTDYCKQA-VKHMYHEASA-N 0.000 description 1
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 1
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 1
- QEFRNWWLZKMPFJ-ZXPFJRLXSA-N L-methionine (R)-S-oxide Chemical group C[S@@](=O)CC[C@H]([NH3+])C([O-])=O QEFRNWWLZKMPFJ-ZXPFJRLXSA-N 0.000 description 1
- QEFRNWWLZKMPFJ-UHFFFAOYSA-N L-methionine sulphoxide Chemical group CS(=O)CCC(N)C(O)=O QEFRNWWLZKMPFJ-UHFFFAOYSA-N 0.000 description 1
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 1
- XUIIKFGFIJCVMT-LBPRGKRZSA-N L-thyroxine Chemical compound IC1=CC(C[C@H]([NH3+])C([O-])=O)=CC(I)=C1OC1=CC(I)=C(O)C(I)=C1 XUIIKFGFIJCVMT-LBPRGKRZSA-N 0.000 description 1
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 1
- MKXZASYAUGDDCJ-SZMVWBNQSA-N LSM-2525 Chemical compound C1CCC[C@H]2[C@@]3([H])N(C)CC[C@]21C1=CC(OC)=CC=C1C3 MKXZASYAUGDDCJ-SZMVWBNQSA-N 0.000 description 1
- 235000014647 Lens culinaris subsp culinaris Nutrition 0.000 description 1
- 244000043158 Lens esculenta Species 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 206010049287 Lipodystrophy acquired Diseases 0.000 description 1
- 101710105045 Lipoprotein E Proteins 0.000 description 1
- FYYHWMGAXLPEAU-UHFFFAOYSA-N Magnesium Chemical compound [Mg] FYYHWMGAXLPEAU-UHFFFAOYSA-N 0.000 description 1
- WSMYVTOQOOLQHP-UHFFFAOYSA-N Malondialdehyde Chemical compound O=CCC=O WSMYVTOQOOLQHP-UHFFFAOYSA-N 0.000 description 1
- OCJYIGYOJCODJL-UHFFFAOYSA-N Meclizine Chemical compound CC1=CC=CC(CN2CCN(CC2)C(C=2C=CC=CC=2)C=2C=CC(Cl)=CC=2)=C1 OCJYIGYOJCODJL-UHFFFAOYSA-N 0.000 description 1
- 102000003792 Metallothionein Human genes 0.000 description 1
- 108090000157 Metallothionein Proteins 0.000 description 1
- 239000012359 Methanesulfonyl chloride Substances 0.000 description 1
- DUGOZIWVEXMGBE-UHFFFAOYSA-N Methylphenidate Chemical compound C=1C=CC=CC=1C(C(=O)OC)C1CCCCN1 DUGOZIWVEXMGBE-UHFFFAOYSA-N 0.000 description 1
- GCKMFJBGXUYNAG-HLXURNFRSA-N Methyltestosterone Chemical compound C1CC2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@](C)(O)[C@@]1(C)CC2 GCKMFJBGXUYNAG-HLXURNFRSA-N 0.000 description 1
- 238000006957 Michael reaction Methods 0.000 description 1
- BYBLEWFAAKGYCD-UHFFFAOYSA-N Miconazole Chemical compound ClC1=CC(Cl)=CC=C1COC(C=1C(=CC(Cl)=CC=1)Cl)CN1C=NC=C1 BYBLEWFAAKGYCD-UHFFFAOYSA-N 0.000 description 1
- ZFMITUMMTDLWHR-UHFFFAOYSA-N Minoxidil Chemical compound NC1=[N+]([O-])C(N)=CC(N2CCCCC2)=N1 ZFMITUMMTDLWHR-UHFFFAOYSA-N 0.000 description 1
- 229930192392 Mitomycin Natural products 0.000 description 1
- KLPWJLBORRMFGK-UHFFFAOYSA-N Molindone Chemical compound O=C1C=2C(CC)=C(C)NC=2CCC1CN1CCOCC1 KLPWJLBORRMFGK-UHFFFAOYSA-N 0.000 description 1
- 108010014251 Muramidase Proteins 0.000 description 1
- 102000016943 Muramidase Human genes 0.000 description 1
- 241000699670 Mus sp. Species 0.000 description 1
- 206010028289 Muscle atrophy Diseases 0.000 description 1
- 108010021466 Mutant Proteins Proteins 0.000 description 1
- 102000008300 Mutant Proteins Human genes 0.000 description 1
- 101710135898 Myc proto-oncogene protein Proteins 0.000 description 1
- 102100038895 Myc proto-oncogene protein Human genes 0.000 description 1
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 description 1
- 108010062010 N-Acetylmuramoyl-L-alanine Amidase Proteins 0.000 description 1
- STECJAGHUSJQJN-UHFFFAOYSA-N N-Methyl-scopolamin Natural products C1C(C2C3O2)N(C)C3CC1OC(=O)C(CO)C1=CC=CC=C1 STECJAGHUSJQJN-UHFFFAOYSA-N 0.000 description 1
- 108010033644 N-acylsphingosine galactosyltransferase Proteins 0.000 description 1
- 229930193140 Neomycin Natural products 0.000 description 1
- 108010052465 Neu5Ac N-acetylgalactosamine 2,6-sialyltransferase Proteins 0.000 description 1
- 101100108611 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) alg-8 gene Proteins 0.000 description 1
- 239000000020 Nitrocellulose Substances 0.000 description 1
- 238000000636 Northern blotting Methods 0.000 description 1
- PHVGLTMQBUFIQQ-UHFFFAOYSA-N Nortryptiline Chemical compound C1CC2=CC=CC=C2C(=CCCNC)C2=CC=CC=C21 PHVGLTMQBUFIQQ-UHFFFAOYSA-N 0.000 description 1
- 108010016076 Octreotide Proteins 0.000 description 1
- 108020005187 Oligonucleotide Probes Proteins 0.000 description 1
- 102000043276 Oncogene Human genes 0.000 description 1
- 108700020796 Oncogene Proteins 0.000 description 1
- 108700026244 Open Reading Frames Proteins 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 208000001132 Osteoporosis Diseases 0.000 description 1
- 239000004100 Oxytetracycline Substances 0.000 description 1
- 102400000050 Oxytocin Human genes 0.000 description 1
- XNOPRXBHLZRZKH-UHFFFAOYSA-N Oxytocin Natural products N1C(=O)C(N)CSSCC(C(=O)N2C(CCC2)C(=O)NC(CC(C)C)C(=O)NCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(CCC(N)=O)NC(=O)C(C(C)CC)NC(=O)C1CC1=CC=C(O)C=C1 XNOPRXBHLZRZKH-UHFFFAOYSA-N 0.000 description 1
- 101800000989 Oxytocin Proteins 0.000 description 1
- 101710137390 P-selectin glycoprotein ligand 1 Proteins 0.000 description 1
- 102100034925 P-selectin glycoprotein ligand 1 Human genes 0.000 description 1
- 241001631646 Papillomaviridae Species 0.000 description 1
- UOZODPSAJZTQNH-UHFFFAOYSA-N Paromomycin II Natural products NC1C(O)C(O)C(CN)OC1OC1C(O)C(OC2C(C(N)CC(N)C2O)OC2C(C(O)C(O)C(CO)O2)N)OC1CO UOZODPSAJZTQNH-UHFFFAOYSA-N 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 101710195435 Periplasmic oligopeptide-binding protein Proteins 0.000 description 1
- ABLZXFCXXLZCGV-UHFFFAOYSA-N Phosphorous acid Chemical class OP(O)=O ABLZXFCXXLZCGV-UHFFFAOYSA-N 0.000 description 1
- 206010035226 Plasma cell myeloma Diseases 0.000 description 1
- 239000004952 Polyamide Substances 0.000 description 1
- 108010039918 Polylysine Proteins 0.000 description 1
- 239000004743 Polypropylene Substances 0.000 description 1
- 229920001213 Polysorbate 20 Polymers 0.000 description 1
- 239000004793 Polystyrene Substances 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- ZGUGWUXLJSTTMA-UHFFFAOYSA-N Promazinum Chemical compound C1=CC=C2N(CCCN(C)C)C3=CC=CC=C3SC2=C1 ZGUGWUXLJSTTMA-UHFFFAOYSA-N 0.000 description 1
- 229940124158 Protease/peptidase inhibitor Drugs 0.000 description 1
- 108010029485 Protein Isoforms Proteins 0.000 description 1
- 102000001708 Protein Isoforms Human genes 0.000 description 1
- 102100030944 Protein-glutamine gamma-glutamyltransferase K Human genes 0.000 description 1
- 241000589517 Pseudomonas aeruginosa Species 0.000 description 1
- 108010083644 Ribonucleases Proteins 0.000 description 1
- 102000006382 Ribonucleases Human genes 0.000 description 1
- 241000714474 Rous sarcoma virus Species 0.000 description 1
- AUVVAXYIELKVAI-UHFFFAOYSA-N SJ000285215 Natural products N1CCC2=CC(OC)=C(OC)C=C2C1CC1CC2C3=CC(OC)=C(OC)C=C3CCN2CC1CC AUVVAXYIELKVAI-UHFFFAOYSA-N 0.000 description 1
- 241000235070 Saccharomyces Species 0.000 description 1
- 241000607142 Salmonella Species 0.000 description 1
- 241001138501 Salmonella enterica Species 0.000 description 1
- 241000235347 Schizosaccharomyces pombe Species 0.000 description 1
- 229920005654 Sephadex Polymers 0.000 description 1
- 239000012507 Sephadex™ Substances 0.000 description 1
- 208000037492 Sex Chromosome Aberrations Diseases 0.000 description 1
- 206010061513 Sex chromosome abnormality Diseases 0.000 description 1
- 208000020221 Short stature Diseases 0.000 description 1
- 206010049416 Short-bowel syndrome Diseases 0.000 description 1
- BQCADISMDOOEFD-UHFFFAOYSA-N Silver Chemical compound [Ag] BQCADISMDOOEFD-UHFFFAOYSA-N 0.000 description 1
- 229920002125 Sokalan® Polymers 0.000 description 1
- 102000005157 Somatostatin Human genes 0.000 description 1
- 108010056088 Somatostatin Proteins 0.000 description 1
- 238000002105 Southern blotting Methods 0.000 description 1
- LKAJKIOFIWVMDJ-IYRCEVNGSA-N Stanazolol Chemical compound C([C@@H]1CC[C@H]2[C@@H]3CC[C@@]([C@]3(CC[C@@H]2[C@@]1(C)C1)C)(O)C)C2=C1C=NN2 LKAJKIOFIWVMDJ-IYRCEVNGSA-N 0.000 description 1
- 229920002472 Starch Polymers 0.000 description 1
- 235000021355 Stearic acid Nutrition 0.000 description 1
- PJANXHGTPQOBST-VAWYXSNFSA-N Stilbene Natural products C=1C=CC=CC=1/C=C/C1=CC=CC=C1 PJANXHGTPQOBST-VAWYXSNFSA-N 0.000 description 1
- 101000874347 Streptococcus agalactiae IgA FC receptor Proteins 0.000 description 1
- 101001091268 Streptomyces hygroscopicus Hygromycin-B 7''-O-kinase Proteins 0.000 description 1
- 102000019197 Superoxide Dismutase Human genes 0.000 description 1
- 108010012715 Superoxide dismutase Proteins 0.000 description 1
- 239000004098 Tetracycline Substances 0.000 description 1
- NSOXQYCFHDMMGV-UHFFFAOYSA-N Tetrakis(2-hydroxypropyl)ethylenediamine Chemical compound CC(O)CN(CC(C)O)CCN(CC(C)O)CC(C)O NSOXQYCFHDMMGV-UHFFFAOYSA-N 0.000 description 1
- KLBQZWRITKRQQV-UHFFFAOYSA-N Thioridazine Chemical compound C12=CC(SC)=CC=C2SC2=CC=CC=C2N1CCC1CCCCN1C KLBQZWRITKRQQV-UHFFFAOYSA-N 0.000 description 1
- 229910052776 Thorium Inorganic materials 0.000 description 1
- 108010022394 Threonine synthase Proteins 0.000 description 1
- 102000006601 Thymidine Kinase Human genes 0.000 description 1
- 108020004440 Thymidine kinase Proteins 0.000 description 1
- AUYYCJSJGJYCDS-LBPRGKRZSA-N Thyrolar Chemical compound IC1=CC(C[C@H](N)C(O)=O)=CC(I)=C1OC1=CC=C(O)C(I)=C1 AUYYCJSJGJYCDS-LBPRGKRZSA-N 0.000 description 1
- 102000003978 Tissue Plasminogen Activator Human genes 0.000 description 1
- 108090000373 Tissue Plasminogen Activator Proteins 0.000 description 1
- 101710120037 Toxin CcdB Proteins 0.000 description 1
- 101710150448 Transcriptional regulator Myc Proteins 0.000 description 1
- 108060008539 Transglutaminase Proteins 0.000 description 1
- HDTRYLNUVZCQOY-WSWWMNSNSA-N Trehalose Natural products O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@H](O)[C@@H](O)[C@@H](O)[C@@H](CO)O1 HDTRYLNUVZCQOY-WSWWMNSNSA-N 0.000 description 1
- XEFQLINVKFYRCS-UHFFFAOYSA-N Triclosan Chemical compound OC1=CC(Cl)=CC=C1OC1=CC=C(Cl)C=C1Cl XEFQLINVKFYRCS-UHFFFAOYSA-N 0.000 description 1
- 101100537665 Trypanosoma cruzi TOR gene Proteins 0.000 description 1
- 208000026928 Turner syndrome Diseases 0.000 description 1
- 108010065282 UDP xylose-protein xylosyltransferase Proteins 0.000 description 1
- 102100038413 UDP-N-acetylglucosamine-dolichyl-phosphate N-acetylglucosaminephosphotransferase Human genes 0.000 description 1
- CYKLRRKFBPBYEI-KBQKSTHMSA-N UDP-alpha-D-galactosamine Chemical compound O1[C@H](CO)[C@H](O)[C@H](O)[C@@H](N)[C@H]1OP(O)(=O)OP(O)(=O)OC[C@@H]1[C@@H](O)[C@@H](O)[C@H](N2C(NC(=O)C=C2)=O)O1 CYKLRRKFBPBYEI-KBQKSTHMSA-N 0.000 description 1
- CYKLRRKFBPBYEI-NQQHDEILSA-N UDP-alpha-D-glucosamine Chemical compound O1[C@H](CO)[C@@H](O)[C@H](O)[C@@H](N)[C@H]1OP(O)(=O)OP(O)(=O)OC[C@@H]1[C@@H](O)[C@@H](O)[C@H](N2C(NC(=O)C=C2)=O)O1 CYKLRRKFBPBYEI-NQQHDEILSA-N 0.000 description 1
- HSCJRCZFDFQWRP-JZMIEXBBSA-N UDP-alpha-D-glucose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1OP(O)(=O)OP(O)(=O)OC[C@@H]1[C@@H](O)[C@@H](O)[C@H](N2C(NC(=O)C=C2)=O)O1 HSCJRCZFDFQWRP-JZMIEXBBSA-N 0.000 description 1
- 108010024501 UDPacetylglucosamine-dolichyl-phosphate acetylglucosamine-1-phosphate transferase Proteins 0.000 description 1
- GBOGMAARMMDZGR-UHFFFAOYSA-N UNPD149280 Natural products N1C(=O)C23OC(=O)C=CC(O)CCCC(C)CC=CC3C(O)C(=C)C(C)C2C1CC1=CC=CC=C1 GBOGMAARMMDZGR-UHFFFAOYSA-N 0.000 description 1
- AXQLFFDZXPOFPO-UHFFFAOYSA-N UNPD216 Natural products O1C(CO)C(O)C(OC2C(C(O)C(O)C(CO)O2)O)C(NC(=O)C)C1OC(C1O)C(O)C(CO)OC1OC1C(O)C(O)C(O)OC1CO AXQLFFDZXPOFPO-UHFFFAOYSA-N 0.000 description 1
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 1
- JXLYSJRDGCGARV-WWYNWVTFSA-N Vinblastine Natural products O=C(O[C@H]1[C@](O)(C(=O)OC)[C@@H]2N(C)c3c(cc(c(OC)c3)[C@]3(C(=O)OC)c4[nH]c5c(c4CCN4C[C@](O)(CC)C[C@H](C3)C4)cccc5)[C@@]32[C@H]2[C@@]1(CC)C=CCN2CC3)C JXLYSJRDGCGARV-WWYNWVTFSA-N 0.000 description 1
- 108050001741 Xylosyltransferases Proteins 0.000 description 1
- 241000607447 Yersinia enterocolitica Species 0.000 description 1
- JSZILQVIPPROJI-CEXWTWQISA-N [(2R,3R,11bS)-3-(diethylcarbamoyl)-9,10-dimethoxy-2,3,4,6,7,11b-hexahydro-1H-benzo[a]quinolizin-2-yl] acetate Chemical compound C1CC2=CC(OC)=C(OC)C=C2[C@H]2N1C[C@@H](C(=O)N(CC)CC)[C@H](OC(C)=O)C2 JSZILQVIPPROJI-CEXWTWQISA-N 0.000 description 1
- XAKBSHICSHRJCL-UHFFFAOYSA-N [CH2]C(=O)C1=CC=CC=C1 Chemical group [CH2]C(=O)C1=CC=CC=C1 XAKBSHICSHRJCL-UHFFFAOYSA-N 0.000 description 1
- GOEMGAFJFRBGGG-UHFFFAOYSA-N acebutolol Chemical compound CCCC(=O)NC1=CC=C(OCC(O)CNC(C)C)C(C(C)=O)=C1 GOEMGAFJFRBGGG-UHFFFAOYSA-N 0.000 description 1
- 229960002122 acebutolol Drugs 0.000 description 1
- 150000001242 acetic acid derivatives Chemical class 0.000 description 1
- 230000000397 acetylating effect Effects 0.000 description 1
- RJURFGZVJUQBHK-IIXSONLDSA-N actinomycin D Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)N[C@@H]4C(=O)N[C@@H](C(N5CCC[C@H]5C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-IIXSONLDSA-N 0.000 description 1
- 230000010933 acylation Effects 0.000 description 1
- 238000005917 acylation reaction Methods 0.000 description 1
- 239000000654 additive Substances 0.000 description 1
- 229940009456 adriamycin Drugs 0.000 description 1
- 239000000443 aerosol Substances 0.000 description 1
- 239000000556 agonist Substances 0.000 description 1
- 150000001298 alcohols Chemical class 0.000 description 1
- 229960003790 alimemazine Drugs 0.000 description 1
- 150000001336 alkenes Chemical class 0.000 description 1
- 125000003342 alkenyl group Chemical group 0.000 description 1
- 125000003545 alkoxy group Chemical group 0.000 description 1
- 239000002168 alkylating agent Substances 0.000 description 1
- 229940100198 alkylating agent Drugs 0.000 description 1
- 125000000304 alkynyl group Chemical group 0.000 description 1
- 208000026935 allergic disease Diseases 0.000 description 1
- HDTRYLNUVZCQOY-LIZSDCNHSA-N alpha,alpha-trehalose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 HDTRYLNUVZCQOY-LIZSDCNHSA-N 0.000 description 1
- GZCGUPFRVQAUEE-UHFFFAOYSA-N alpha-D-galactose Natural products OCC(O)C(O)C(O)C(O)C=O GZCGUPFRVQAUEE-UHFFFAOYSA-N 0.000 description 1
- WQZGKKKJIJFFOK-UHFFFAOYSA-N alpha-D-glucopyranose Natural products OCC1OC(O)C(O)C(O)C1O WQZGKKKJIJFFOK-UHFFFAOYSA-N 0.000 description 1
- 229960000711 alprostadil Drugs 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 229960003805 amantadine Drugs 0.000 description 1
- DKNWSYNQZKUICI-UHFFFAOYSA-N amantadine Chemical compound C1C(C2)CC3CC2CC1(N)C3 DKNWSYNQZKUICI-UHFFFAOYSA-N 0.000 description 1
- 125000003368 amide group Chemical group 0.000 description 1
- 229960004821 amikacin Drugs 0.000 description 1
- LKCWBDHBTVXHDL-RMDFUYIESA-N amikacin Chemical compound O([C@@H]1[C@@H](N)C[C@H]([C@@H]([C@H]1O)O[C@@H]1[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O1)O)NC(=O)[C@@H](O)CCN)[C@H]1O[C@H](CN)[C@@H](O)[C@H](O)[C@H]1O LKCWBDHBTVXHDL-RMDFUYIESA-N 0.000 description 1
- XSDQTOBWRPYKKA-UHFFFAOYSA-N amiloride Chemical compound NC(=N)NC(=O)C1=NC(Cl)=C(N)N=C1N XSDQTOBWRPYKKA-UHFFFAOYSA-N 0.000 description 1
- 229960002576 amiloride Drugs 0.000 description 1
- 150000003862 amino acid derivatives Chemical class 0.000 description 1
- LSTJLLHJASXKIV-UHFFFAOYSA-N amino hexanoate Chemical compound CCCCCC(=O)ON LSTJLLHJASXKIV-UHFFFAOYSA-N 0.000 description 1
- 229940126575 aminoglycoside Drugs 0.000 description 1
- 229960005260 amiodarone Drugs 0.000 description 1
- 229960000836 amitriptyline Drugs 0.000 description 1
- KRMDCWKBEZIMAB-UHFFFAOYSA-N amitriptyline Chemical compound C1CC2=CC=CC=C2C(=CCCN(C)C)C2=CC=CC=C21 KRMDCWKBEZIMAB-UHFFFAOYSA-N 0.000 description 1
- 238000012870 ammonium sulfate precipitation Methods 0.000 description 1
- 229940025084 amphetamine Drugs 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- RNLQIBCLLYYYFJ-UHFFFAOYSA-N amrinone Chemical compound N1C(=O)C(N)=CC(C=2C=CN=CC=2)=C1 RNLQIBCLLYYYFJ-UHFFFAOYSA-N 0.000 description 1
- 229960002105 amrinone Drugs 0.000 description 1
- 229940124325 anabolic agent Drugs 0.000 description 1
- 230000001195 anabolic effect Effects 0.000 description 1
- 239000002269 analeptic agent Substances 0.000 description 1
- 239000012491 analyte Substances 0.000 description 1
- 238000013103 analytical ultracentrifugation Methods 0.000 description 1
- 238000004873 anchoring Methods 0.000 description 1
- 239000003098 androgen Substances 0.000 description 1
- 229940030486 androgens Drugs 0.000 description 1
- 238000005571 anion exchange chromatography Methods 0.000 description 1
- 239000003957 anion exchange resin Substances 0.000 description 1
- 229940045799 anthracyclines and related substance Drugs 0.000 description 1
- 230000002280 anti-androgenic effect Effects 0.000 description 1
- 230000000844 anti-bacterial effect Effects 0.000 description 1
- 230000001078 anti-cholinergic effect Effects 0.000 description 1
- 230000002686 anti-diuretic effect Effects 0.000 description 1
- 230000003474 anti-emetic effect Effects 0.000 description 1
- 229940046836 anti-estrogen Drugs 0.000 description 1
- 230000001833 anti-estrogenic effect Effects 0.000 description 1
- 230000000843 anti-fungal effect Effects 0.000 description 1
- 230000001387 anti-histamine Effects 0.000 description 1
- 229940121363 anti-inflammatory agent Drugs 0.000 description 1
- 239000002260 anti-inflammatory agent Substances 0.000 description 1
- 229940124599 anti-inflammatory drug Drugs 0.000 description 1
- 230000003110 anti-inflammatory effect Effects 0.000 description 1
- 230000000842 anti-protozoal effect Effects 0.000 description 1
- 230000000259 anti-tumor effect Effects 0.000 description 1
- 239000000051 antiandrogen Substances 0.000 description 1
- 229940030495 antiandrogen sex hormone and modulator of the genital system Drugs 0.000 description 1
- 239000003416 antiarrhythmic agent Substances 0.000 description 1
- 239000000935 antidepressant agent Substances 0.000 description 1
- 229940124538 antidiuretic agent Drugs 0.000 description 1
- 239000002111 antiemetic agent Substances 0.000 description 1
- 229940121375 antifungal agent Drugs 0.000 description 1
- 229940125715 antihistaminic agent Drugs 0.000 description 1
- 239000002220 antihypertensive agent Substances 0.000 description 1
- 229940127088 antihypertensive drug Drugs 0.000 description 1
- 229940111133 antiinflammatory and antirheumatic drug oxicams Drugs 0.000 description 1
- 229940111131 antiinflammatory and antirheumatic product propionic acid derivative Drugs 0.000 description 1
- 239000003080 antimitotic agent Substances 0.000 description 1
- 229940127248 antinauseant drug Drugs 0.000 description 1
- 239000003904 antiprotozoal agent Substances 0.000 description 1
- 239000003908 antipruritic agent Substances 0.000 description 1
- 239000000164 antipsychotic agent Substances 0.000 description 1
- 239000003200 antithyroid agent Substances 0.000 description 1
- 229940043671 antithyroid preparations Drugs 0.000 description 1
- 239000003434 antitussive agent Substances 0.000 description 1
- 229940124584 antitussives Drugs 0.000 description 1
- 239000003699 antiulcer agent Substances 0.000 description 1
- 239000003443 antiviral agent Substances 0.000 description 1
- 230000006907 apoptotic process Effects 0.000 description 1
- 239000002830 appetite depressant Substances 0.000 description 1
- PYMYPHUHKUWMLA-UHFFFAOYSA-N arabinose Natural products OCC(O)C(O)C(O)C=O PYMYPHUHKUWMLA-UHFFFAOYSA-N 0.000 description 1
- 229960003272 asparaginase Drugs 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-M asparaginate Chemical compound [O-]C(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-M 0.000 description 1
- 125000000613 asparagine group Chemical group N[C@@H](CC(N)=O)C(=O)* 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 238000002820 assay format Methods 0.000 description 1
- 125000004429 atom Chemical group 0.000 description 1
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical compound [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 1
- RKUNBYITZUJHSG-SPUOUPEWSA-N atropine Chemical compound O([C@H]1C[C@H]2CC[C@@H](C1)N2C)C(=O)C(CO)C1=CC=CC=C1 RKUNBYITZUJHSG-SPUOUPEWSA-N 0.000 description 1
- 229960000396 atropine Drugs 0.000 description 1
- 229960002170 azathioprine Drugs 0.000 description 1
- LMEKQMALGUDUQG-UHFFFAOYSA-N azathioprine Chemical compound CN1C=NC([N+]([O-])=O)=C1SC1=NC=NC2=C1NC=N2 LMEKQMALGUDUQG-UHFFFAOYSA-N 0.000 description 1
- 210000003719 b-lymphocyte Anatomy 0.000 description 1
- 229940092705 beclomethasone Drugs 0.000 description 1
- NBMKJKDGKREAPL-DVTGEIKXSA-N beclomethasone Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(Cl)[C@@H]1[C@@H]1C[C@H](C)[C@@](C(=O)CO)(O)[C@@]1(C)C[C@@H]2O NBMKJKDGKREAPL-DVTGEIKXSA-N 0.000 description 1
- ISAOCJYIOMOJEB-UHFFFAOYSA-N benzoin Chemical group C=1C=CC=CC=1C(O)C(=O)C1=CC=CC=C1 ISAOCJYIOMOJEB-UHFFFAOYSA-N 0.000 description 1
- 239000012965 benzophenone Substances 0.000 description 1
- YXKTVDFXDRQTKV-HNNXBMFYSA-N benzphetamine Chemical compound C([C@H](C)N(C)CC=1C=CC=CC=1)C1=CC=CC=C1 YXKTVDFXDRQTKV-HNNXBMFYSA-N 0.000 description 1
- 229960002837 benzphetamine Drugs 0.000 description 1
- 229960004564 benzquinamide Drugs 0.000 description 1
- 125000001797 benzyl group Chemical group [H]C1=C([H])C([H])=C(C([H])=C1[H])C([H])([H])* 0.000 description 1
- 239000002876 beta blocker Substances 0.000 description 1
- AXQLFFDZXPOFPO-UNTPKZLMSA-N beta-D-Galp-(1->3)-beta-D-GlcpNAc-(1->3)-beta-D-Galp-(1->4)-beta-D-Glcp Chemical compound O([C@@H]1O[C@H](CO)[C@H](O)[C@@H]([C@H]1O)O[C@H]1[C@@H]([C@H]([C@H](O)[C@@H](CO)O1)O[C@H]1[C@@H]([C@@H](O)[C@@H](O)[C@@H](CO)O1)O)NC(=O)C)[C@H]1[C@H](O)[C@@H](O)[C@H](O)O[C@@H]1CO AXQLFFDZXPOFPO-UNTPKZLMSA-N 0.000 description 1
- SRBFZHDQGSBBOR-UHFFFAOYSA-N beta-D-Pyranose-Lyxose Natural products OC1COC(O)C(O)C1O SRBFZHDQGSBBOR-UHFFFAOYSA-N 0.000 description 1
- 102000006995 beta-Glucosidase Human genes 0.000 description 1
- 108010047754 beta-Glucosidase Proteins 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 229960002537 betamethasone Drugs 0.000 description 1
- UREBDLICKHMUKA-DVTGEIKXSA-N betamethasone Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@H](C)[C@@](C(=O)CO)(O)[C@@]1(C)C[C@@H]2O UREBDLICKHMUKA-DVTGEIKXSA-N 0.000 description 1
- 229960004324 betaxolol Drugs 0.000 description 1
- CHDPSNLJFOQTRK-UHFFFAOYSA-N betaxolol hydrochloride Chemical compound [Cl-].C1=CC(OCC(O)C[NH2+]C(C)C)=CC=C1CCOCC1CC1 CHDPSNLJFOQTRK-UHFFFAOYSA-N 0.000 description 1
- 230000008827 biological function Effects 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- OMWQUXGVXQELIX-UHFFFAOYSA-N bitoscanate Chemical compound S=C=NC1=CC=C(N=C=S)C=C1 OMWQUXGVXQELIX-UHFFFAOYSA-N 0.000 description 1
- 230000017531 blood circulation Effects 0.000 description 1
- 230000037396 body weight Effects 0.000 description 1
- RSIHSRDYCUFFLA-DYKIIFRCSA-N boldenone Chemical compound O=C1C=C[C@]2(C)[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 RSIHSRDYCUFFLA-DYKIIFRCSA-N 0.000 description 1
- 229960001705 buclizine Drugs 0.000 description 1
- MOYGZHXDRJNJEP-UHFFFAOYSA-N buclizine Chemical compound C1=CC(C(C)(C)C)=CC=C1CN1CCN(C(C=2C=CC=CC=2)C=2C=CC(Cl)=CC=2)CC1 MOYGZHXDRJNJEP-UHFFFAOYSA-N 0.000 description 1
- 239000006172 buffering agent Substances 0.000 description 1
- 229960003455 buphenine Drugs 0.000 description 1
- 229960003150 bupivacaine Drugs 0.000 description 1
- 229960002092 busulfan Drugs 0.000 description 1
- 125000000484 butyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 239000006227 byproduct Substances 0.000 description 1
- 210000004899 c-terminal region Anatomy 0.000 description 1
- 229960004596 cabergoline Drugs 0.000 description 1
- 239000001506 calcium phosphate Substances 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- CJZGTCYPCWQAJB-UHFFFAOYSA-L calcium stearate Chemical compound [Ca+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O CJZGTCYPCWQAJB-UHFFFAOYSA-L 0.000 description 1
- 235000013539 calcium stearate Nutrition 0.000 description 1
- 239000008116 calcium stearate Substances 0.000 description 1
- 238000005251 capillar electrophoresis Methods 0.000 description 1
- 229960004602 capreomycin Drugs 0.000 description 1
- 239000002775 capsule Substances 0.000 description 1
- OFAIGZWCDGNZGT-UHFFFAOYSA-N caramiphen Chemical compound C=1C=CC=CC=1C1(C(=O)OCCN(CC)CC)CCCC1 OFAIGZWCDGNZGT-UHFFFAOYSA-N 0.000 description 1
- 229960004160 caramiphen Drugs 0.000 description 1
- 239000004202 carbamide Substances 0.000 description 1
- CREMABGTGYGIQB-UHFFFAOYSA-N carbon carbon Chemical compound C.C CREMABGTGYGIQB-UHFFFAOYSA-N 0.000 description 1
- 239000011203 carbon fibre reinforced carbon Substances 0.000 description 1
- 125000002915 carbonyl group Chemical group [*:2]C([*:1])=O 0.000 description 1
- PFKFTWBEEFSNDU-UHFFFAOYSA-N carbonyldiimidazole Chemical compound C1=CN=CN1C(=O)N1C=CN=C1 PFKFTWBEEFSNDU-UHFFFAOYSA-N 0.000 description 1
- 125000005392 carboxamide group Chemical group NC(=O)* 0.000 description 1
- UHBYWPGGCSDKFX-UHFFFAOYSA-N carboxyglutamic acid Chemical compound OC(=O)C(N)CC(C(O)=O)C(O)=O UHBYWPGGCSDKFX-UHFFFAOYSA-N 0.000 description 1
- 239000000496 cardiotonic agent Substances 0.000 description 1
- 238000005341 cation exchange Methods 0.000 description 1
- 150000001768 cations Chemical class 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 239000006143 cell culture medium Substances 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 210000002421 cell wall Anatomy 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 239000013522 chelant Substances 0.000 description 1
- NDAYQJDHGXTBJL-MWWSRJDJSA-N chembl557217 Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](CC(C)C)NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H](CC(C)C)NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H](CC(C)C)NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H](C(C)C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](C(C)C)NC(=O)[C@H](C)NC(=O)[C@H](NC(=O)CNC(=O)[C@@H](NC=O)C(C)C)CC(C)C)C(=O)NCCO)=CNC2=C1 NDAYQJDHGXTBJL-MWWSRJDJSA-N 0.000 description 1
- 238000009614 chemical analysis method Methods 0.000 description 1
- 238000012412 chemical coupling Methods 0.000 description 1
- 125000003636 chemical group Chemical group 0.000 description 1
- 238000007385 chemical modification Methods 0.000 description 1
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 1
- ANTSCNMPPGJYLG-UHFFFAOYSA-N chlordiazepoxide Chemical compound O=N=1CC(NC)=NC2=CC=C(Cl)C=C2C=1C1=CC=CC=C1 ANTSCNMPPGJYLG-UHFFFAOYSA-N 0.000 description 1
- 229960004782 chlordiazepoxide Drugs 0.000 description 1
- 229960003260 chlorhexidine Drugs 0.000 description 1
- VDANGULDQQJODZ-UHFFFAOYSA-N chloroprocaine Chemical compound CCN(CC)CCOC(=O)C1=CC=C(N)C=C1Cl VDANGULDQQJODZ-UHFFFAOYSA-N 0.000 description 1
- 229960002023 chloroprocaine Drugs 0.000 description 1
- CYDMQBQPVICBEU-UHFFFAOYSA-N chlorotetracycline Natural products C1=CC(Cl)=C2C(O)(C)C3CC4C(N(C)C)C(O)=C(C(N)=O)C(=O)C4(O)C(O)=C3C(=O)C2=C1O CYDMQBQPVICBEU-UHFFFAOYSA-N 0.000 description 1
- SOYKEARSMXGVTM-UHFFFAOYSA-N chlorphenamine Chemical compound C=1C=CC=NC=1C(CCN(C)C)C1=CC=C(Cl)C=C1 SOYKEARSMXGVTM-UHFFFAOYSA-N 0.000 description 1
- 229960003291 chlorphenamine Drugs 0.000 description 1
- 229950007046 chlorphentermine Drugs 0.000 description 1
- ZPEIMTDSQAKGNT-UHFFFAOYSA-N chlorpromazine Chemical compound C1=C(Cl)C=C2N(CCCN(C)C)C3=CC=CC=C3SC2=C1 ZPEIMTDSQAKGNT-UHFFFAOYSA-N 0.000 description 1
- 229960001076 chlorpromazine Drugs 0.000 description 1
- 229960001761 chlorpropamide Drugs 0.000 description 1
- 229960001552 chlorprothixene Drugs 0.000 description 1
- 229960004475 chlortetracycline Drugs 0.000 description 1
- CYDMQBQPVICBEU-XRNKAMNCSA-N chlortetracycline Chemical compound C1=CC(Cl)=C2[C@](O)(C)[C@H]3C[C@H]4[C@H](N(C)C)C(O)=C(C(N)=O)C(=O)[C@@]4(O)C(O)=C3C(=O)C2=C1O CYDMQBQPVICBEU-XRNKAMNCSA-N 0.000 description 1
- 235000019365 chlortetracycline Nutrition 0.000 description 1
- 239000000812 cholinergic antagonist Substances 0.000 description 1
- 238000011098 chromatofocusing Methods 0.000 description 1
- 229960001265 ciclosporin Drugs 0.000 description 1
- 229960001747 cinchocaine Drugs 0.000 description 1
- PUFQVTATUTYEAL-UHFFFAOYSA-N cinchocaine Chemical compound C1=CC=CC2=NC(OCCCC)=CC(C(=O)NCCN(CC)CC)=C21 PUFQVTATUTYEAL-UHFFFAOYSA-N 0.000 description 1
- LOUPRKONTZGTKE-UHFFFAOYSA-N cinchonine Natural products C1C(C(C2)C=C)CCN2C1C(O)C1=CC=NC2=CC=C(OC)C=C21 LOUPRKONTZGTKE-UHFFFAOYSA-N 0.000 description 1
- 229960001750 cinnamedrine Drugs 0.000 description 1
- 229960003405 ciprofloxacin Drugs 0.000 description 1
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 1
- 229960004316 cisplatin Drugs 0.000 description 1
- 239000004927 clay Substances 0.000 description 1
- 230000010405 clearance mechanism Effects 0.000 description 1
- 229960002227 clindamycin Drugs 0.000 description 1
- KDLRVYVGXIQJDK-AWPVFWJPSA-N clindamycin Chemical compound CN1C[C@H](CCC)C[C@H]1C(=O)N[C@H]([C@H](C)Cl)[C@@H]1[C@H](O)[C@H](O)[C@@H](O)[C@@H](SC)O1 KDLRVYVGXIQJDK-AWPVFWJPSA-N 0.000 description 1
- 229960002842 clobetasol Drugs 0.000 description 1
- FCSHDIVRCWTZOX-DVTGEIKXSA-N clobetasol Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@H](C)[C@@](C(=O)CCl)(O)[C@@]1(C)C[C@@H]2O FCSHDIVRCWTZOX-DVTGEIKXSA-N 0.000 description 1
- 229960002896 clonidine Drugs 0.000 description 1
- 238000012411 cloning technique Methods 0.000 description 1
- 229940105778 coagulation factor viii Drugs 0.000 description 1
- 239000002642 cobra venom Substances 0.000 description 1
- 229960004126 codeine Drugs 0.000 description 1
- 238000012875 competitive assay Methods 0.000 description 1
- 230000002860 competitive effect Effects 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 229940125782 compound 2 Drugs 0.000 description 1
- 238000013329 compounding Methods 0.000 description 1
- 239000012141 concentrate Substances 0.000 description 1
- 238000009833 condensation Methods 0.000 description 1
- 230000005494 condensation Effects 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 239000000356 contaminant Substances 0.000 description 1
- 229940124558 contraceptive agent Drugs 0.000 description 1
- 239000003433 contraceptive agent Substances 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- 239000003246 corticosteroid Substances 0.000 description 1
- 229960001334 corticosteroids Drugs 0.000 description 1
- 229960004544 cortisone Drugs 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 229960000265 cromoglicic acid Drugs 0.000 description 1
- 230000009260 cross reactivity Effects 0.000 description 1
- 239000002739 cryptand Substances 0.000 description 1
- ATDGTVJJHBUTRL-UHFFFAOYSA-N cyanogen bromide Chemical compound BrC#N ATDGTVJJHBUTRL-UHFFFAOYSA-N 0.000 description 1
- 229920005565 cyclic polymer Polymers 0.000 description 1
- 229960003564 cyclizine Drugs 0.000 description 1
- UVKZSORBKUEBAZ-UHFFFAOYSA-N cyclizine Chemical compound C1CN(C)CCN1C(C=1C=CC=CC=1)C1=CC=CC=C1 UVKZSORBKUEBAZ-UHFFFAOYSA-N 0.000 description 1
- 238000006352 cycloaddition reaction Methods 0.000 description 1
- JURKNVYFZMSNLP-UHFFFAOYSA-N cyclobenzaprine Chemical compound C1=CC2=CC=CC=C2C(=CCCN(C)C)C2=CC=CC=C21 JURKNVYFZMSNLP-UHFFFAOYSA-N 0.000 description 1
- 229960003572 cyclobenzaprine Drugs 0.000 description 1
- 229940097362 cyclodextrins Drugs 0.000 description 1
- 229960004397 cyclophosphamide Drugs 0.000 description 1
- 229930182912 cyclosporin Natural products 0.000 description 1
- IERHLVCPSMICTF-UHFFFAOYSA-N cytidine monophosphate Natural products O=C1N=C(N)C=CN1C1C(O)C(O)C(COP(O)(O)=O)O1 IERHLVCPSMICTF-UHFFFAOYSA-N 0.000 description 1
- GBOGMAARMMDZGR-TYHYBEHESA-N cytochalasin B Chemical compound C([C@H]1[C@@H]2[C@@H](C([C@@H](O)[C@@H]3/C=C/C[C@H](C)CCC[C@@H](O)/C=C/C(=O)O[C@@]23C(=O)N1)=C)C)C1=CC=CC=C1 GBOGMAARMMDZGR-TYHYBEHESA-N 0.000 description 1
- GBOGMAARMMDZGR-JREHFAHYSA-N cytochalasin B Natural products C[C@H]1CCC[C@@H](O)C=CC(=O)O[C@@]23[C@H](C=CC1)[C@H](O)C(=C)[C@@H](C)[C@@H]2[C@H](Cc4ccccc4)NC3=O GBOGMAARMMDZGR-JREHFAHYSA-N 0.000 description 1
- 231100000409 cytocidal Toxicity 0.000 description 1
- 230000000445 cytocidal effect Effects 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- 229940127089 cytotoxic agent Drugs 0.000 description 1
- 239000002254 cytotoxic agent Substances 0.000 description 1
- 229960000640 dactinomycin Drugs 0.000 description 1
- POZRVZJJTULAOH-LHZXLZLDSA-N danazol Chemical compound C1[C@]2(C)[C@H]3CC[C@](C)([C@](CC4)(O)C#C)[C@@H]4[C@@H]3CCC2=CC2=C1C=NO2 POZRVZJJTULAOH-LHZXLZLDSA-N 0.000 description 1
- 229960000766 danazol Drugs 0.000 description 1
- 229960001987 dantrolene Drugs 0.000 description 1
- STQGQHZAVUOBTE-VGBVRHCVSA-N daunorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(C)=O)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 STQGQHZAVUOBTE-VGBVRHCVSA-N 0.000 description 1
- 229960000975 daunorubicin Drugs 0.000 description 1
- 230000018044 dehydration Effects 0.000 description 1
- 238000006297 dehydration reaction Methods 0.000 description 1
- RSIHSRDYCUFFLA-UHFFFAOYSA-N dehydrotestosterone Natural products O=C1C=CC2(C)C3CCC(C)(C(CC4)O)C4C3CCC2=C1 RSIHSRDYCUFFLA-UHFFFAOYSA-N 0.000 description 1
- YSMODUONRAFBET-UHFFFAOYSA-N delta-DL-hydroxylysine Natural products NCC(O)CCC(N)C(O)=O YSMODUONRAFBET-UHFFFAOYSA-N 0.000 description 1
- 239000000412 dendrimer Substances 0.000 description 1
- 229920000736 dendritic polymer Polymers 0.000 description 1
- CFCUWKMKBJTWLW-UHFFFAOYSA-N deoliosyl-3C-alpha-L-digitoxosyl-MTM Natural products CC=1C(O)=C2C(O)=C3C(=O)C(OC4OC(C)C(O)C(OC5OC(C)C(O)C(OC6OC(C)C(O)C(C)(O)C6)C5)C4)C(C(OC)C(=O)C(O)C(C)O)CC3=CC2=CC=1OC(OC(C)C1O)CC1OC1CC(O)C(O)C(C)O1 CFCUWKMKBJTWLW-UHFFFAOYSA-N 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 229960003914 desipramine Drugs 0.000 description 1
- NFLWUMRGJYTJIN-NXBWRCJVSA-N desmopressin Chemical compound C([C@H]1C(=O)N[C@H](C(N[C@@H](CC(N)=O)C(=O)N[C@@H](CSSCCC(=O)N[C@@H](CC=2C=CC(O)=CC=2)C(=O)N1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(N)=O)=O)CCC(=O)N)C1=CC=CC=C1 NFLWUMRGJYTJIN-NXBWRCJVSA-N 0.000 description 1
- 229960004281 desmopressin Drugs 0.000 description 1
- 229960004976 desogestrel Drugs 0.000 description 1
- RPLCPCMSCLEKRS-BPIQYHPVSA-N desogestrel Chemical compound C1CC[C@@H]2[C@H]3C(=C)C[C@](CC)([C@](CC4)(O)C#C)[C@@H]4[C@@H]3CCC2=C1 RPLCPCMSCLEKRS-BPIQYHPVSA-N 0.000 description 1
- 238000003795 desorption Methods 0.000 description 1
- 230000001627 detrimental effect Effects 0.000 description 1
- 229960003957 dexamethasone Drugs 0.000 description 1
- UREBDLICKHMUKA-CXSFZGCWSA-N dexamethasone Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@@H](C)[C@@](C(=O)CO)(O)[C@@]1(C)C[C@@H]2O UREBDLICKHMUKA-CXSFZGCWSA-N 0.000 description 1
- 229960000632 dexamfetamine Drugs 0.000 description 1
- 229960001985 dextromethorphan Drugs 0.000 description 1
- LSXWFXONGKSEMY-UHFFFAOYSA-N di-tert-butyl peroxide Chemical compound CC(C)(C)OOC(C)(C)C LSXWFXONGKSEMY-UHFFFAOYSA-N 0.000 description 1
- 239000012969 di-tertiary-butyl peroxide Substances 0.000 description 1
- 230000001904 diabetogenic effect Effects 0.000 description 1
- 238000011026 diafiltration Methods 0.000 description 1
- 238000003745 diagnosis Methods 0.000 description 1
- 150000008049 diazo compounds Chemical class 0.000 description 1
- RGLYKWWBQGJZGM-ISLYRVAYSA-N diethylstilbestrol Chemical compound C=1C=C(O)C=CC=1C(/CC)=C(\CC)C1=CC=C(O)C=C1 RGLYKWWBQGJZGM-ISLYRVAYSA-N 0.000 description 1
- HESHRHUZIWVEAJ-JGRZULCMSA-N dihydroergotamine Chemical compound C([C@H]1C(=O)N2CCC[C@H]2[C@]2(O)O[C@@](C(N21)=O)(C)NC(=O)[C@H]1CN([C@H]2[C@@H](C3=CC=CC4=NC=C([C]34)C2)C1)C)C1=CC=CC=C1 HESHRHUZIWVEAJ-JGRZULCMSA-N 0.000 description 1
- 229960004704 dihydroergotamine Drugs 0.000 description 1
- 102000004419 dihydrofolate reductase Human genes 0.000 description 1
- KZNICNPSHKQLFF-UHFFFAOYSA-N dihydromaleimide Natural products O=C1CCC(=O)N1 KZNICNPSHKQLFF-UHFFFAOYSA-N 0.000 description 1
- HSUGRBWQSSZJOP-RTWAWAEBSA-N diltiazem Chemical compound C1=CC(OC)=CC=C1[C@H]1[C@@H](OC(C)=O)C(=O)N(CCN(C)C)C2=CC=CC=C2S1 HSUGRBWQSSZJOP-RTWAWAEBSA-N 0.000 description 1
- 229960004166 diltiazem Drugs 0.000 description 1
- SPCNPOWOBZQWJK-UHFFFAOYSA-N dimethoxy-(2-propan-2-ylsulfanylethylsulfanyl)-sulfanylidene-$l^{5}-phosphane Chemical compound COP(=S)(OC)SCCSC(C)C SPCNPOWOBZQWJK-UHFFFAOYSA-N 0.000 description 1
- 125000000118 dimethyl group Chemical group [H]C([H])([H])* 0.000 description 1
- 230000003292 diminished effect Effects 0.000 description 1
- XEYBRNLFEZDVAW-ARSRFYASSA-N dinoprostone Chemical compound CCCCC[C@H](O)\C=C\[C@H]1[C@H](O)CC(=O)[C@@H]1C\C=C/CCCC(O)=O XEYBRNLFEZDVAW-ARSRFYASSA-N 0.000 description 1
- 229960002986 dinoprostone Drugs 0.000 description 1
- HYPPXZBJBPSRLK-UHFFFAOYSA-N diphenoxylate Chemical compound C1CC(C(=O)OCC)(C=2C=CC=CC=2)CCN1CCC(C#N)(C=1C=CC=CC=1)C1=CC=CC=C1 HYPPXZBJBPSRLK-UHFFFAOYSA-N 0.000 description 1
- 229960004192 diphenoxylate Drugs 0.000 description 1
- XQRLCLUYWUNEEH-UHFFFAOYSA-L diphosphonate(2-) Chemical compound [O-]P(=O)OP([O-])=O XQRLCLUYWUNEEH-UHFFFAOYSA-L 0.000 description 1
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 1
- VLARUOGDXDTHEH-UHFFFAOYSA-L disodium cromoglycate Chemical compound [Na+].[Na+].O1C(C([O-])=O)=CC(=O)C2=C1C=CC=C2OCC(O)COC1=CC=CC2=C1C(=O)C=C(C([O-])=O)O2 VLARUOGDXDTHEH-UHFFFAOYSA-L 0.000 description 1
- 229960001066 disopyramide Drugs 0.000 description 1
- UVTNFZQICZKOEM-UHFFFAOYSA-N disopyramide Chemical compound C=1C=CC=NC=1C(C(N)=O)(CCN(C(C)C)C(C)C)C1=CC=CC=C1 UVTNFZQICZKOEM-UHFFFAOYSA-N 0.000 description 1
- 208000035475 disorder Diseases 0.000 description 1
- 230000006334 disulfide bridging Effects 0.000 description 1
- 125000002228 disulfide group Chemical group 0.000 description 1
- 239000002934 diuretic Substances 0.000 description 1
- 230000001882 diuretic effect Effects 0.000 description 1
- AFOSIXZFDONLBT-UHFFFAOYSA-N divinyl sulfone Chemical compound C=CS(=O)(=O)C=C AFOSIXZFDONLBT-UHFFFAOYSA-N 0.000 description 1
- 229960001089 dobutamine Drugs 0.000 description 1
- 108010088016 dolichyl-phosphate beta-D-mannosyltransferase Proteins 0.000 description 1
- 239000002552 dosage form Substances 0.000 description 1
- 230000012361 double-strand break repair Effects 0.000 description 1
- 229960003722 doxycycline Drugs 0.000 description 1
- 230000002196 ecbolic effect Effects 0.000 description 1
- 238000007336 electrophilic substitution reaction Methods 0.000 description 1
- 238000001962 electrophoresis Methods 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- AUVVAXYIELKVAI-CKBKHPSWSA-N emetine Chemical compound N1CCC2=CC(OC)=C(OC)C=C2[C@H]1C[C@H]1C[C@H]2C3=CC(OC)=C(OC)C=C3CCN2C[C@@H]1CC AUVVAXYIELKVAI-CKBKHPSWSA-N 0.000 description 1
- 229960002694 emetine Drugs 0.000 description 1
- AUVVAXYIELKVAI-UWBTVBNJSA-N emetine Natural products N1CCC2=CC(OC)=C(OC)C=C2[C@H]1C[C@H]1C[C@H]2C3=CC(OC)=C(OC)C=C3CCN2C[C@H]1CC AUVVAXYIELKVAI-UWBTVBNJSA-N 0.000 description 1
- GBXSMTUPTTWBMN-XIRDDKMYSA-N enalapril Chemical compound C([C@@H](C(=O)OCC)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(O)=O)CC1=CC=CC=C1 GBXSMTUPTTWBMN-XIRDDKMYSA-N 0.000 description 1
- 229960000873 enalapril Drugs 0.000 description 1
- 150000002081 enamines Chemical class 0.000 description 1
- PJWPNDMDCLXCOM-UHFFFAOYSA-N encainide Chemical compound C1=CC(OC)=CC=C1C(=O)NC1=CC=CC=C1CCC1N(C)CCCC1 PJWPNDMDCLXCOM-UHFFFAOYSA-N 0.000 description 1
- 229960001142 encainide Drugs 0.000 description 1
- 230000002124 endocrine Effects 0.000 description 1
- 230000001159 endocytotic effect Effects 0.000 description 1
- 210000002889 endothelial cell Anatomy 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 210000002919 epithelial cell Anatomy 0.000 description 1
- OFKDAAIKGIBASY-VFGNJEKYSA-N ergotamine Chemical compound C([C@H]1C(=O)N2CCC[C@H]2[C@]2(O)O[C@@](C(N21)=O)(C)NC(=O)[C@H]1CN([C@H]2C(C3=CC=CC4=NC=C([C]34)C2)=C1)C)C1=CC=CC=C1 OFKDAAIKGIBASY-VFGNJEKYSA-N 0.000 description 1
- 229960004943 ergotamine Drugs 0.000 description 1
- XCGSFFUVFURLIX-UHFFFAOYSA-N ergotaminine Natural products C1=C(C=2C=CC=C3NC=C(C=23)C2)C2N(C)CC1C(=O)NC(C(N12)=O)(C)OC1(O)C1CCCN1C(=O)C2CC1=CC=CC=C1 XCGSFFUVFURLIX-UHFFFAOYSA-N 0.000 description 1
- YSMODUONRAFBET-UHNVWZDZSA-N erythro-5-hydroxy-L-lysine Chemical compound NC[C@H](O)CC[C@H](N)C(O)=O YSMODUONRAFBET-UHNVWZDZSA-N 0.000 description 1
- 210000003743 erythrocyte Anatomy 0.000 description 1
- 229960003276 erythromycin Drugs 0.000 description 1
- 125000004185 ester group Chemical group 0.000 description 1
- 229960005309 estradiol Drugs 0.000 description 1
- 229930182833 estradiol Natural products 0.000 description 1
- 229940011871 estrogen Drugs 0.000 description 1
- 239000000262 estrogen Substances 0.000 description 1
- 239000000328 estrogen antagonist Substances 0.000 description 1
- 229960000285 ethambutol Drugs 0.000 description 1
- 150000002170 ethers Chemical class 0.000 description 1
- ZMMJGEGLRURXTF-UHFFFAOYSA-N ethidium bromide Chemical compound [Br-].C12=CC(N)=CC=C2C2=CC=C(N)C=C2[N+](CC)=C1C1=CC=CC=C1 ZMMJGEGLRURXTF-UHFFFAOYSA-N 0.000 description 1
- 229960005542 ethidium bromide Drugs 0.000 description 1
- 229960002568 ethinylestradiol Drugs 0.000 description 1
- RIFGWPKJUGCATF-UHFFFAOYSA-N ethyl chloroformate Chemical compound CCOC(Cl)=O RIFGWPKJUGCATF-UHFFFAOYSA-N 0.000 description 1
- IYBKWXQWKPSYDT-UHFFFAOYSA-L ethylene glycol disuccinate bis(sulfo-N-succinimidyl) ester sodium salt Chemical compound [Na+].[Na+].O=C1C(S(=O)(=O)[O-])CC(=O)N1OC(=O)CCC(=O)OCCOC(=O)CCC(=O)ON1C(=O)C(S([O-])(=O)=O)CC1=O IYBKWXQWKPSYDT-UHFFFAOYSA-L 0.000 description 1
- XFBVBWWRPKNWHW-UHFFFAOYSA-N etodolac Chemical compound C1COC(CC)(CC(O)=O)C2=N[C]3C(CC)=CC=CC3=C21 XFBVBWWRPKNWHW-UHFFFAOYSA-N 0.000 description 1
- 229960005293 etodolac Drugs 0.000 description 1
- VJJPUSNTGOMMGY-MRVIYFEKSA-N etoposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@H](C)OC[C@H]4O3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 VJJPUSNTGOMMGY-MRVIYFEKSA-N 0.000 description 1
- 229960005420 etoposide Drugs 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 229960001596 famotidine Drugs 0.000 description 1
- XUFQPHANEAPEMJ-UHFFFAOYSA-N famotidine Chemical compound NC(N)=NC1=NC(CSCCC(N)=NS(N)(=O)=O)=CS1 XUFQPHANEAPEMJ-UHFFFAOYSA-N 0.000 description 1
- ZWJINEZUASEZBH-UHFFFAOYSA-N fenamic acid Chemical class OC(=O)C1=CC=CC=C1NC1=CC=CC=C1 ZWJINEZUASEZBH-UHFFFAOYSA-N 0.000 description 1
- 229960001582 fenfluramine Drugs 0.000 description 1
- 238000000855 fermentation Methods 0.000 description 1
- 230000004151 fermentation Effects 0.000 description 1
- 102000013361 fetuin Human genes 0.000 description 1
- 108060002885 fetuin Proteins 0.000 description 1
- 239000000796 flavoring agent Substances 0.000 description 1
- 235000019634 flavors Nutrition 0.000 description 1
- SPIUTQOUKAMGCX-UHFFFAOYSA-N flavoxate Chemical compound C1=CC=C2C(=O)C(C)=C(C=3C=CC=CC=3)OC2=C1C(=O)OCCN1CCCCC1 SPIUTQOUKAMGCX-UHFFFAOYSA-N 0.000 description 1
- 229960000855 flavoxate Drugs 0.000 description 1
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 1
- 238000001215 fluorescent labelling Methods 0.000 description 1
- 150000004673 fluoride salts Chemical class 0.000 description 1
- 125000001153 fluoro group Chemical group F* 0.000 description 1
- 229960002949 fluorouracil Drugs 0.000 description 1
- YLRFCQOZQXIBAB-RBZZARIASA-N fluoxymesterone Chemical compound C1CC2=CC(=O)CC[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1CC[C@](C)(O)[C@@]1(C)C[C@@H]2O YLRFCQOZQXIBAB-RBZZARIASA-N 0.000 description 1
- 229960001751 fluoxymesterone Drugs 0.000 description 1
- 229960002690 fluphenazine Drugs 0.000 description 1
- SAADBVWGJQAEFS-UHFFFAOYSA-N flurazepam Chemical compound N=1CC(=O)N(CCN(CC)CC)C2=CC=C(Cl)C=C2C=1C1=CC=CC=C1F SAADBVWGJQAEFS-UHFFFAOYSA-N 0.000 description 1
- 229960003528 flurazepam Drugs 0.000 description 1
- MKXKFYHWDHIYRV-UHFFFAOYSA-N flutamide Chemical compound CC(C)C(=O)NC1=CC=C([N+]([O-])=O)C(C(F)(F)F)=C1 MKXKFYHWDHIYRV-UHFFFAOYSA-N 0.000 description 1
- 229960002074 flutamide Drugs 0.000 description 1
- 235000013305 food Nutrition 0.000 description 1
- 235000019253 formic acid Nutrition 0.000 description 1
- 238000013467 fragmentation Methods 0.000 description 1
- 238000006062 fragmentation reaction Methods 0.000 description 1
- 230000008014 freezing Effects 0.000 description 1
- 238000007710 freezing Methods 0.000 description 1
- 125000002446 fucosyl group Chemical group C1([C@@H](O)[C@H](O)[C@H](O)[C@@H](O1)C)* 0.000 description 1
- ZZUFCTLCJUWOSV-UHFFFAOYSA-N furosemide Chemical compound C1=C(Cl)C(S(=O)(=O)N)=CC(C(O)=O)=C1NCC1=CC=CO1 ZZUFCTLCJUWOSV-UHFFFAOYSA-N 0.000 description 1
- 108010082530 galactosyl-1-3-N-acetylgalactosaminyl-specific 2,6-sialyltransferase Proteins 0.000 description 1
- 150000002256 galaktoses Chemical class 0.000 description 1
- 102000006640 gamma-Glutamyltransferase Human genes 0.000 description 1
- 150000002270 gangliosides Chemical class 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- QTQAWLPCGQOSGP-GBTDJJJQSA-N geldanamycin Chemical compound N1C(=O)\C(C)=C/C=C\[C@@H](OC)[C@H](OC(N)=O)\C(C)=C/[C@@H](C)[C@@H](O)[C@H](OC)C[C@@H](C)CC2=C(OC)C(=O)C=C1C2=O QTQAWLPCGQOSGP-GBTDJJJQSA-N 0.000 description 1
- 238000002523 gelfiltration Methods 0.000 description 1
- 239000003193 general anesthetic agent Substances 0.000 description 1
- 239000011521 glass Substances 0.000 description 1
- 229960004580 glibenclamide Drugs 0.000 description 1
- 230000024924 glomerular filtration Effects 0.000 description 1
- 125000002791 glucosyl group Chemical group C1([C@H](O)[C@@H](O)[C@H](O)[C@H](O1)CO)* 0.000 description 1
- 229940097043 glucuronic acid Drugs 0.000 description 1
- 229930195712 glutamate Natural products 0.000 description 1
- 235000013922 glutamic acid Nutrition 0.000 description 1
- 239000004220 glutamic acid Substances 0.000 description 1
- 125000000404 glutamine group Chemical group N[C@@H](CCC(N)=O)C(=O)* 0.000 description 1
- ZNNLBTZKUZBEKO-UHFFFAOYSA-N glyburide Chemical compound COC1=CC=C(Cl)C=C1C(=O)NCCC1=CC=C(S(=O)(=O)NC(=O)NC2CCCCC2)C=C1 ZNNLBTZKUZBEKO-UHFFFAOYSA-N 0.000 description 1
- 108010026195 glycanase Proteins 0.000 description 1
- 150000002332 glycine derivatives Chemical class 0.000 description 1
- 150000002334 glycols Chemical class 0.000 description 1
- 102000035122 glycosylated proteins Human genes 0.000 description 1
- 108091005608 glycosylated proteins Proteins 0.000 description 1
- 229930004094 glycosylphosphatidylinositol Natural products 0.000 description 1
- 229940015043 glyoxal Drugs 0.000 description 1
- 239000010931 gold Substances 0.000 description 1
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 1
- 229960002913 goserelin Drugs 0.000 description 1
- 239000003102 growth factor Substances 0.000 description 1
- 239000001963 growth medium Substances 0.000 description 1
- 210000004349 growth plate Anatomy 0.000 description 1
- HPBNRIOWIXYZFK-UHFFFAOYSA-N guanadrel Chemical compound O1C(CNC(=N)N)COC11CCCCC1 HPBNRIOWIXYZFK-UHFFFAOYSA-N 0.000 description 1
- 229960003845 guanadrel Drugs 0.000 description 1
- ACGDKVXYNVEAGU-UHFFFAOYSA-N guanethidine Chemical compound NC(N)=NCCN1CCCCCCC1 ACGDKVXYNVEAGU-UHFFFAOYSA-N 0.000 description 1
- 229960003602 guanethidine Drugs 0.000 description 1
- 125000001188 haloalkyl group Chemical group 0.000 description 1
- 229910052736 halogen Inorganic materials 0.000 description 1
- 125000005843 halogen group Chemical group 0.000 description 1
- 150000002367 halogens Chemical class 0.000 description 1
- 229960003878 haloperidol Drugs 0.000 description 1
- 230000035876 healing Effects 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 238000010438 heat treatment Methods 0.000 description 1
- 150000002373 hemiacetals Chemical group 0.000 description 1
- 230000002440 hepatic effect Effects 0.000 description 1
- RRAMGCGOFNQTLD-UHFFFAOYSA-N hexamethylene diisocyanate Chemical compound O=C=NCCCCCCN=C=O RRAMGCGOFNQTLD-UHFFFAOYSA-N 0.000 description 1
- 235000010299 hexamethylene tetramine Nutrition 0.000 description 1
- VKYKSIONXSXAKP-UHFFFAOYSA-N hexamethylenetetramine Chemical compound C1N(C2)CN3CN1CN2C3 VKYKSIONXSXAKP-UHFFFAOYSA-N 0.000 description 1
- OQLKNTOKMBVBKV-UHFFFAOYSA-N hexamidine Chemical compound C1=CC(C(=N)N)=CC=C1OCCCCCCOC1=CC=C(C(N)=N)C=C1 OQLKNTOKMBVBKV-UHFFFAOYSA-N 0.000 description 1
- 229960001915 hexamidine Drugs 0.000 description 1
- 239000003485 histamine H2 receptor antagonist Substances 0.000 description 1
- 210000003630 histaminocyte Anatomy 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 229960000857 homatropine Drugs 0.000 description 1
- 230000005745 host immune response Effects 0.000 description 1
- 235000020256 human milk Nutrition 0.000 description 1
- 210000004251 human milk Anatomy 0.000 description 1
- 229960002474 hydralazine Drugs 0.000 description 1
- 150000007857 hydrazones Chemical class 0.000 description 1
- 229960002003 hydrochlorothiazide Drugs 0.000 description 1
- OROGSEYTTFOCAN-UHFFFAOYSA-N hydrocodone Natural products C1C(N(CCC234)C)C2C=CC(O)C3OC2=C4C1=CC=C2OC OROGSEYTTFOCAN-UHFFFAOYSA-N 0.000 description 1
- 229960000890 hydrocortisone Drugs 0.000 description 1
- 150000002431 hydrogen Chemical group 0.000 description 1
- 239000000852 hydrogen donor Substances 0.000 description 1
- 125000002349 hydroxyamino group Chemical group [H]ON([H])[*] 0.000 description 1
- 229960000930 hydroxyzine Drugs 0.000 description 1
- ZQDWXGKKHFNSQK-UHFFFAOYSA-N hydroxyzine Chemical compound C1CN(CCOCCO)CCN1C(C=1C=CC(Cl)=CC=1)C1=CC=CC=C1 ZQDWXGKKHFNSQK-UHFFFAOYSA-N 0.000 description 1
- 239000000960 hypophysis hormone Substances 0.000 description 1
- 229950000141 idaverine Drugs 0.000 description 1
- 150000002460 imidazoles Chemical class 0.000 description 1
- 150000003949 imides Chemical class 0.000 description 1
- 150000002466 imines Chemical class 0.000 description 1
- 229960004801 imipramine Drugs 0.000 description 1
- BCGWQEUPMDMJNV-UHFFFAOYSA-N imipramine Chemical compound C1CC2=CC=CC=C2N(CCCN(C)C)C2=CC=CC=C21 BCGWQEUPMDMJNV-UHFFFAOYSA-N 0.000 description 1
- 230000001900 immune effect Effects 0.000 description 1
- 230000028993 immune response Effects 0.000 description 1
- 229940124622 immune-modulator drug Drugs 0.000 description 1
- 230000003053 immunization Effects 0.000 description 1
- 238000002649 immunization Methods 0.000 description 1
- 238000003119 immunoblot Methods 0.000 description 1
- 230000000984 immunochemical effect Effects 0.000 description 1
- 230000002998 immunogenetic effect Effects 0.000 description 1
- 230000009851 immunogenic response Effects 0.000 description 1
- 230000016784 immunoglobulin production Effects 0.000 description 1
- 229960003444 immunosuppressant agent Drugs 0.000 description 1
- 239000003018 immunosuppressive agent Substances 0.000 description 1
- 238000002513 implantation Methods 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 239000012535 impurity Substances 0.000 description 1
- 238000011534 incubation Methods 0.000 description 1
- 229940055742 indium-111 Drugs 0.000 description 1
- APFVFJFRJDLVQX-AHCXROLUSA-N indium-111 Chemical compound [111In] APFVFJFRJDLVQX-AHCXROLUSA-N 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 230000005764 inhibitory process Effects 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 229940125396 insulin Drugs 0.000 description 1
- 230000002608 insulinlike Effects 0.000 description 1
- 229940047124 interferons Drugs 0.000 description 1
- 210000000936 intestine Anatomy 0.000 description 1
- 238000007917 intracranial administration Methods 0.000 description 1
- 238000007914 intraventricular administration Methods 0.000 description 1
- 238000011835 investigation Methods 0.000 description 1
- 238000005342 ion exchange Methods 0.000 description 1
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 1
- 229960000310 isoleucine Drugs 0.000 description 1
- 229960004819 isoxsuprine Drugs 0.000 description 1
- 238000005304 joining Methods 0.000 description 1
- 108010080576 juvenile hormone esterase Proteins 0.000 description 1
- 229960000318 kanamycin Drugs 0.000 description 1
- 229930027917 kanamycin Natural products 0.000 description 1
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 1
- 229930182823 kanamycin A Natural products 0.000 description 1
- 150000002576 ketones Chemical group 0.000 description 1
- DKYWVDODHFEZIM-UHFFFAOYSA-N ketoprofen Chemical compound OC(=O)C(C)C1=CC=CC(C(=O)C=2C=CC=CC=2)=C1 DKYWVDODHFEZIM-UHFFFAOYSA-N 0.000 description 1
- 229960000991 ketoprofen Drugs 0.000 description 1
- OZWKMVRBQXNZKK-UHFFFAOYSA-N ketorolac Chemical compound OC(=O)C1CCN2C1=CC=C2C(=O)C1=CC=CC=C1 OZWKMVRBQXNZKK-UHFFFAOYSA-N 0.000 description 1
- 229960004752 ketorolac Drugs 0.000 description 1
- 210000003127 knee Anatomy 0.000 description 1
- 229960001632 labetalol Drugs 0.000 description 1
- 230000006651 lactation Effects 0.000 description 1
- IEQCXFNWPAHHQR-UHFFFAOYSA-N lacto-N-neotetraose Natural products OCC1OC(OC2C(C(OC3C(OC(O)C(O)C3O)CO)OC(CO)C2O)O)C(NC(=O)C)C(O)C1OC1OC(CO)C(O)C(O)C1O IEQCXFNWPAHHQR-UHFFFAOYSA-N 0.000 description 1
- USIPEGYTBGEPJN-UHFFFAOYSA-N lacto-N-tetraose Natural products O1C(CO)C(O)C(OC2C(C(O)C(O)C(CO)O2)O)C(NC(=O)C)C1OC1C(O)C(CO)OC(OC(C(O)CO)C(O)C(O)C=O)C1O USIPEGYTBGEPJN-UHFFFAOYSA-N 0.000 description 1
- 229940062780 lacto-n-neotetraose Drugs 0.000 description 1
- 238000011031 large-scale manufacturing process Methods 0.000 description 1
- 239000004816 latex Substances 0.000 description 1
- 229920000126 latex Polymers 0.000 description 1
- 229960004502 levodopa Drugs 0.000 description 1
- 229960004400 levonorgestrel Drugs 0.000 description 1
- 229950008325 levothyroxine Drugs 0.000 description 1
- 208000006132 lipodystrophy Diseases 0.000 description 1
- 238000004895 liquid chromatography mass spectrometry Methods 0.000 description 1
- RVGLGHVJXCETIO-UHFFFAOYSA-N lodoxamide Chemical compound OC(=O)C(=O)NC1=CC(C#N)=CC(NC(=O)C(O)=O)=C1Cl RVGLGHVJXCETIO-UHFFFAOYSA-N 0.000 description 1
- 229960004305 lodoxamide Drugs 0.000 description 1
- 229960000423 loxapine Drugs 0.000 description 1
- YQZBAXDVDZTKEQ-UHFFFAOYSA-N loxapine succinate Chemical compound [H+].[H+].[O-]C(=O)CCC([O-])=O.C1CN(C)CCN1C1=NC2=CC=CC=C2OC2=CC=C(Cl)C=C12 YQZBAXDVDZTKEQ-UHFFFAOYSA-N 0.000 description 1
- 208000017830 lymphoblastoma Diseases 0.000 description 1
- 230000002934 lysing effect Effects 0.000 description 1
- 235000010335 lysozyme Nutrition 0.000 description 1
- 239000004325 lysozyme Substances 0.000 description 1
- 229960000274 lysozyme Drugs 0.000 description 1
- 229910052749 magnesium Inorganic materials 0.000 description 1
- HQKMJHAJHXVSDF-UHFFFAOYSA-L magnesium stearate Substances [Mg+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O HQKMJHAJHXVSDF-UHFFFAOYSA-L 0.000 description 1
- 235000019359 magnesium stearate Nutrition 0.000 description 1
- 229910052943 magnesium sulfate Inorganic materials 0.000 description 1
- 230000014759 maintenance of location Effects 0.000 description 1
- 229940118019 malondialdehyde Drugs 0.000 description 1
- 230000000873 masking effect Effects 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 229960003577 mebeverine Drugs 0.000 description 1
- 230000010534 mechanism of action Effects 0.000 description 1
- 229960001474 meclozine Drugs 0.000 description 1
- 229960001786 megestrol Drugs 0.000 description 1
- RQZAXGRLVPAYTJ-GQFGMJRRSA-N megestrol acetate Chemical compound C1=C(C)C2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@@](C(C)=O)(OC(=O)C)[C@@]1(C)CC2 RQZAXGRLVPAYTJ-GQFGMJRRSA-N 0.000 description 1
- GLVAUDGFNGKCSF-UHFFFAOYSA-N mercaptopurine Chemical compound S=C1NC=NC2=C1NC=N2 GLVAUDGFNGKCSF-UHFFFAOYSA-N 0.000 description 1
- 229960001428 mercaptopurine Drugs 0.000 description 1
- IMSSROKUHAOUJS-MJCUULBUSA-N mestranol Chemical compound C1C[C@]2(C)[C@@](C#C)(O)CC[C@H]2[C@@H]2CCC3=CC(OC)=CC=C3[C@H]21 IMSSROKUHAOUJS-MJCUULBUSA-N 0.000 description 1
- 229960001390 mestranol Drugs 0.000 description 1
- 230000002503 metabolic effect Effects 0.000 description 1
- 230000037353 metabolic pathway Effects 0.000 description 1
- 230000004060 metabolic process Effects 0.000 description 1
- 229910021645 metal ion Inorganic materials 0.000 description 1
- 229940042016 methacycline Drugs 0.000 description 1
- 229960001252 methamphetamine Drugs 0.000 description 1
- HZVOZRGWRWCICA-UHFFFAOYSA-N methanediyl Chemical compound [CH2] HZVOZRGWRWCICA-UHFFFAOYSA-N 0.000 description 1
- QARBMVPHQWIHKH-UHFFFAOYSA-N methanesulfonyl chloride Chemical compound CS(Cl)(=O)=O QARBMVPHQWIHKH-UHFFFAOYSA-N 0.000 description 1
- KNWQLFOXPQZGPX-UHFFFAOYSA-N methanesulfonyl fluoride Chemical compound CS(F)(=O)=O KNWQLFOXPQZGPX-UHFFFAOYSA-N 0.000 description 1
- HTMIBDQKFHUPSX-UHFFFAOYSA-N methdilazine Chemical compound C1N(C)CCC1CN1C2=CC=CC=C2SC2=CC=CC=C21 HTMIBDQKFHUPSX-UHFFFAOYSA-N 0.000 description 1
- 229960004056 methdilazine Drugs 0.000 description 1
- 229960004011 methenamine Drugs 0.000 description 1
- PMRYVIKBURPHAH-UHFFFAOYSA-N methimazole Chemical compound CN1C=CNC1=S PMRYVIKBURPHAH-UHFFFAOYSA-N 0.000 description 1
- 229960000485 methotrexate Drugs 0.000 description 1
- DRJCXBUNHZPLSI-UHFFFAOYSA-N methyl 3-(3-imino-3-methoxypropoxy)propanimidate Chemical compound COC(=N)CCOCCC(=N)OC DRJCXBUNHZPLSI-UHFFFAOYSA-N 0.000 description 1
- MBAXWTVHCRPVFW-UHFFFAOYSA-N methyl 3-[(3-imino-3-methoxypropyl)disulfanyl]propanimidate Chemical compound COC(=N)CCSSCCC(=N)OC MBAXWTVHCRPVFW-UHFFFAOYSA-N 0.000 description 1
- BMFSIUXDCWBTHJ-UHFFFAOYSA-N methyl 3-[4-(3-imino-3-methoxypropoxy)butoxy]propanimidate Chemical compound COC(CCOCCCCOCCC(OC)=N)=N BMFSIUXDCWBTHJ-UHFFFAOYSA-N 0.000 description 1
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 1
- 229960000328 methylergometrine Drugs 0.000 description 1
- 229960001344 methylphenidate Drugs 0.000 description 1
- 229960004584 methylprednisolone Drugs 0.000 description 1
- LSDPWZHWYPCBBB-UHFFFAOYSA-O methylsulfide anion Chemical compound [SH2+]C LSDPWZHWYPCBBB-UHFFFAOYSA-O 0.000 description 1
- 229960001566 methyltestosterone Drugs 0.000 description 1
- 229960002237 metoprolol Drugs 0.000 description 1
- IUBSYMUCCVWXPE-UHFFFAOYSA-N metoprolol Chemical compound COCCC1=CC=C(OCC(O)CNC(C)C)C=C1 IUBSYMUCCVWXPE-UHFFFAOYSA-N 0.000 description 1
- 229960000282 metronidazole Drugs 0.000 description 1
- VAOCPAMSLUNLGC-UHFFFAOYSA-N metronidazole Chemical compound CC1=NC=C([N+]([O-])=O)N1CCO VAOCPAMSLUNLGC-UHFFFAOYSA-N 0.000 description 1
- 229960002509 miconazole Drugs 0.000 description 1
- 238000000520 microinjection Methods 0.000 description 1
- 229960003574 milrinone Drugs 0.000 description 1
- PZRHRDRVRGEVNW-UHFFFAOYSA-N milrinone Chemical compound N1C(=O)C(C#N)=CC(C=2C=CN=CC=2)=C1C PZRHRDRVRGEVNW-UHFFFAOYSA-N 0.000 description 1
- 230000003278 mimic effect Effects 0.000 description 1
- 229960004023 minocycline Drugs 0.000 description 1
- 229960003632 minoxidil Drugs 0.000 description 1
- 230000033607 mismatch repair Effects 0.000 description 1
- CFCUWKMKBJTWLW-BKHRDMLASA-N mithramycin Chemical compound O([C@@H]1C[C@@H](O[C@H](C)[C@H]1O)OC=1C=C2C=C3C[C@H]([C@@H](C(=O)C3=C(O)C2=C(O)C=1C)O[C@@H]1O[C@H](C)[C@@H](O)[C@H](O[C@@H]2O[C@H](C)[C@H](O)[C@H](O[C@@H]3O[C@H](C)[C@@H](O)[C@@](C)(O)C3)C2)C1)[C@H](OC)C(=O)[C@@H](O)[C@@H](C)O)[C@H]1C[C@@H](O)[C@H](O)[C@@H](C)O1 CFCUWKMKBJTWLW-BKHRDMLASA-N 0.000 description 1
- 229960004857 mitomycin Drugs 0.000 description 1
- KKZJGLLVHKMTCM-UHFFFAOYSA-N mitoxantrone Chemical compound O=C1C2=C(O)C=CC(O)=C2C(=O)C2=C1C(NCCNCCO)=CC=C2NCCNCCO KKZJGLLVHKMTCM-UHFFFAOYSA-N 0.000 description 1
- 229960001156 mitoxantrone Drugs 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 239000002808 molecular sieve Substances 0.000 description 1
- 229960004938 molindone Drugs 0.000 description 1
- HPEUEJRPDGMIMY-IFQPEPLCSA-N molybdopterin Chemical compound O([C@H]1N2)[C@H](COP(O)(O)=O)C(S)=C(S)[C@@H]1NC1=C2N=C(N)NC1=O HPEUEJRPDGMIMY-IFQPEPLCSA-N 0.000 description 1
- 150000002763 monocarboxylic acids Chemical class 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 150000004712 monophosphates Chemical class 0.000 description 1
- 201000000050 myeloid neoplasm Diseases 0.000 description 1
- 239000003158 myorelaxant agent Substances 0.000 description 1
- 239000006225 natural substrate Substances 0.000 description 1
- 229960004927 neomycin Drugs 0.000 description 1
- ZBGPYVZLYBDXKO-HILBYHGXSA-N netilmycin Chemical compound O([C@@H]1[C@@H](N)C[C@H]([C@@H]([C@H]1O)O[C@@H]1[C@]([C@H](NC)[C@@H](O)CO1)(C)O)NCC)[C@H]1OC(CN)=CC[C@H]1N ZBGPYVZLYBDXKO-HILBYHGXSA-N 0.000 description 1
- 230000007514 neuronal growth Effects 0.000 description 1
- 230000004112 neuroprotection Effects 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 125000000449 nitro group Chemical group [O-][N+](*)=O 0.000 description 1
- 125000006502 nitrobenzyl group Chemical group 0.000 description 1
- 229920001220 nitrocellulos Polymers 0.000 description 1
- 125000006501 nitrophenyl group Chemical group 0.000 description 1
- 229960001180 norfloxacin Drugs 0.000 description 1
- OGJPXUAPXNRGGI-UHFFFAOYSA-N norfloxacin Chemical compound C1=C2N(CC)C=C(C(O)=O)C(=O)C2=CC(F)=C1N1CCNCC1 OGJPXUAPXNRGGI-UHFFFAOYSA-N 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 238000007899 nucleic acid hybridization Methods 0.000 description 1
- 239000012038 nucleophile Substances 0.000 description 1
- 239000002777 nucleoside Substances 0.000 description 1
- 125000003835 nucleoside group Chemical group 0.000 description 1
- 235000016709 nutrition Nutrition 0.000 description 1
- QIQXTHQIDYTFRH-UHFFFAOYSA-N octadecanoic acid Chemical compound CCCCCCCCCCCCCCCCCC(O)=O QIQXTHQIDYTFRH-UHFFFAOYSA-N 0.000 description 1
- OQCDKBAXFALNLD-UHFFFAOYSA-N octadecanoic acid Natural products CCCCCCCC(C)CCCCCCCCC(O)=O OQCDKBAXFALNLD-UHFFFAOYSA-N 0.000 description 1
- 229920002113 octoxynol Polymers 0.000 description 1
- 229960002700 octreotide Drugs 0.000 description 1
- 235000019198 oils Nutrition 0.000 description 1
- 239000002751 oligonucleotide probe Substances 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 239000003960 organic solvent Substances 0.000 description 1
- QVYRGXJJSLMXQH-UHFFFAOYSA-N orphenadrine Chemical compound C=1C=CC=C(C)C=1C(OCCN(C)C)C1=CC=CC=C1 QVYRGXJJSLMXQH-UHFFFAOYSA-N 0.000 description 1
- 229960003941 orphenadrine Drugs 0.000 description 1
- 201000008482 osteoarthritis Diseases 0.000 description 1
- 238000012261 overproduction Methods 0.000 description 1
- 238000010525 oxidative degradation reaction Methods 0.000 description 1
- 150000002923 oximes Chemical class 0.000 description 1
- 239000001301 oxygen Substances 0.000 description 1
- 229960000625 oxytetracycline Drugs 0.000 description 1
- IWVCMVBTMGNXQD-PXOLEDIWSA-N oxytetracycline Chemical compound C1=CC=C2[C@](O)(C)[C@H]3[C@H](O)[C@H]4[C@H](N(C)C)C(O)=C(C(N)=O)C(=O)[C@@]4(O)C(O)=C3C(=O)C2=C1O IWVCMVBTMGNXQD-PXOLEDIWSA-N 0.000 description 1
- 235000019366 oxytetracycline Nutrition 0.000 description 1
- 239000002863 oxytocic agent Substances 0.000 description 1
- 229940094443 oxytocics prostaglandins Drugs 0.000 description 1
- XNOPRXBHLZRZKH-DSZYJQQASA-N oxytocin Chemical compound C([C@H]1C(=O)N[C@H](C(N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CSSC[C@H](N)C(=O)N1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(N)=O)=O)[C@@H](C)CC)C1=CC=C(O)C=C1 XNOPRXBHLZRZKH-DSZYJQQASA-N 0.000 description 1
- 229960001723 oxytocin Drugs 0.000 description 1
- 239000003002 pH adjusting agent Substances 0.000 description 1
- 229960001789 papaverine Drugs 0.000 description 1
- UOZODPSAJZTQNH-LSWIJEOBSA-N paromomycin Chemical compound N[C@@H]1[C@@H](O)[C@H](O)[C@H](CN)O[C@@H]1O[C@H]1[C@@H](O)[C@H](O[C@H]2[C@@H]([C@@H](N)C[C@@H](N)[C@@H]2O)O[C@@H]2[C@@H]([C@@H](O)[C@H](O)[C@@H](CO)O2)N)O[C@@H]1CO UOZODPSAJZTQNH-LSWIJEOBSA-N 0.000 description 1
- 229960001914 paromomycin Drugs 0.000 description 1
- 244000052769 pathogen Species 0.000 description 1
- 229960004448 pentamidine Drugs 0.000 description 1
- XDRYMKDFEDOLFX-UHFFFAOYSA-N pentamidine Chemical compound C1=CC(C(=N)N)=CC=C1OCCCCCOC1=CC=C(C(N)=N)C=C1 XDRYMKDFEDOLFX-UHFFFAOYSA-N 0.000 description 1
- 229960003436 pentoxyverine Drugs 0.000 description 1
- 239000000813 peptide hormone Substances 0.000 description 1
- 239000000137 peptide hydrolase inhibitor Substances 0.000 description 1
- KHIWWQKSHDUIBK-UHFFFAOYSA-M periodate Chemical compound [O-]I(=O)(=O)=O KHIWWQKSHDUIBK-UHFFFAOYSA-M 0.000 description 1
- 210000003200 peritoneal cavity Anatomy 0.000 description 1
- 229960003562 phentermine Drugs 0.000 description 1
- 125000001997 phenyl group Chemical group [H]C1=C([H])C([H])=C(*)C([H])=C1[H] 0.000 description 1
- NMHMNPHRMNGLLB-UHFFFAOYSA-N phloretic acid Chemical compound OC(=O)CCC1=CC=C(O)C=C1 NMHMNPHRMNGLLB-UHFFFAOYSA-N 0.000 description 1
- RGCLLPNLLBQHPF-HJWRWDBZSA-N phosphamidon Chemical compound CCN(CC)C(=O)C(\Cl)=C(/C)OP(=O)(OC)OC RGCLLPNLLBQHPF-HJWRWDBZSA-N 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- 235000021317 phosphate Nutrition 0.000 description 1
- 150000003013 phosphoric acid derivatives Chemical class 0.000 description 1
- BZQFBWGGLXLEPQ-REOHCLBHSA-N phosphoserine Chemical compound OC(=O)[C@@H](N)COP(O)(O)=O BZQFBWGGLXLEPQ-REOHCLBHSA-N 0.000 description 1
- DCWXELXMIBXGTH-UHFFFAOYSA-N phosphotyrosine Chemical compound OC(=O)C(N)CC1=CC=C(OP(O)(O)=O)C=C1 DCWXELXMIBXGTH-UHFFFAOYSA-N 0.000 description 1
- 230000001766 physiological effect Effects 0.000 description 1
- 230000006461 physiological response Effects 0.000 description 1
- 210000002826 placenta Anatomy 0.000 description 1
- 230000036470 plasma concentration Effects 0.000 description 1
- 229920003023 plastic Polymers 0.000 description 1
- 239000004033 plastic Substances 0.000 description 1
- 229960003171 plicamycin Drugs 0.000 description 1
- 229920000765 poly(2-oxazolines) Polymers 0.000 description 1
- 229920001583 poly(oxyethylated polyols) Polymers 0.000 description 1
- 229920002627 poly(phosphazenes) Polymers 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 229920001515 polyalkylene glycol Polymers 0.000 description 1
- 229920002647 polyamide Polymers 0.000 description 1
- 229920000768 polyamine Polymers 0.000 description 1
- 229920000728 polyester Polymers 0.000 description 1
- 229920005862 polyol Polymers 0.000 description 1
- 150000003077 polyols Chemical class 0.000 description 1
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 1
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 1
- 235000010482 polyoxyethylene sorbitan monooleate Nutrition 0.000 description 1
- 229920001155 polypropylene Polymers 0.000 description 1
- 229920000053 polysorbate 80 Polymers 0.000 description 1
- 229920002223 polystyrene Polymers 0.000 description 1
- 229920002451 polyvinyl alcohol Polymers 0.000 description 1
- 239000013641 positive control Substances 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 229960005205 prednisolone Drugs 0.000 description 1
- OIGNJSKKLXVSLS-VWUMJDOOSA-N prednisolone Chemical compound O=C1C=C[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 OIGNJSKKLXVSLS-VWUMJDOOSA-N 0.000 description 1
- 238000002953 preparative HPLC Methods 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- REQCZEXYDRLIBE-UHFFFAOYSA-N procainamide Chemical compound CCN(CC)CCNC(=O)C1=CC=C(N)C=C1 REQCZEXYDRLIBE-UHFFFAOYSA-N 0.000 description 1
- 229960000244 procainamide Drugs 0.000 description 1
- 229960004919 procaine Drugs 0.000 description 1
- MFDFERRIHVXMIY-UHFFFAOYSA-N procaine Chemical compound CCN(CC)CCOC(=O)C1=CC=C(N)C=C1 MFDFERRIHVXMIY-UHFFFAOYSA-N 0.000 description 1
- 229960000624 procarbazine Drugs 0.000 description 1
- CPTBDICYNRMXFX-UHFFFAOYSA-N procarbazine Chemical compound CNNCC1=CC=C(C(=O)NC(C)C)C=C1 CPTBDICYNRMXFX-UHFFFAOYSA-N 0.000 description 1
- 229940002612 prodrug Drugs 0.000 description 1
- 239000000651 prodrug Substances 0.000 description 1
- 239000000583 progesterone congener Substances 0.000 description 1
- 229940095055 progestogen systemic hormonal contraceptives Drugs 0.000 description 1
- 230000002035 prolonged effect Effects 0.000 description 1
- 229960003598 promazine Drugs 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 150000005599 propionic acid derivatives Chemical class 0.000 description 1
- 229960003712 propranolol Drugs 0.000 description 1
- 229960004063 propylene glycol Drugs 0.000 description 1
- 235000013772 propylene glycol Nutrition 0.000 description 1
- GMVPRGQOIOIIMI-DWKJAMRDSA-N prostaglandin E1 Chemical compound CCCCC[C@H](O)\C=C\[C@H]1[C@H](O)CC(=O)[C@@H]1CCCCCCC(O)=O GMVPRGQOIOIIMI-DWKJAMRDSA-N 0.000 description 1
- XEYBRNLFEZDVAW-UHFFFAOYSA-N prostaglandin E2 Natural products CCCCCC(O)C=CC1C(O)CC(=O)C1CC=CCCCC(O)=O XEYBRNLFEZDVAW-UHFFFAOYSA-N 0.000 description 1
- 150000003180 prostaglandins Chemical class 0.000 description 1
- 230000001681 protective effect Effects 0.000 description 1
- 102000008467 protein O-GlcNAc transferase activity proteins Human genes 0.000 description 1
- 108040002385 protein O-GlcNAc transferase activity proteins Proteins 0.000 description 1
- 238000000159 protein binding assay Methods 0.000 description 1
- 239000012460 protein solution Substances 0.000 description 1
- XNSAINXGIQZQOO-SRVKXCTJSA-N protirelin Chemical compound NC(=O)[C@@H]1CCCN1C(=O)[C@@H](NC(=O)[C@H]1NC(=O)CC1)CC1=CN=CN1 XNSAINXGIQZQOO-SRVKXCTJSA-N 0.000 description 1
- 210000001938 protoplast Anatomy 0.000 description 1
- 229950010131 puromycin Drugs 0.000 description 1
- UMJSCPRVCHMLSP-UHFFFAOYSA-N pyridine Natural products COC1=CC=CN=C1 UMJSCPRVCHMLSP-UHFFFAOYSA-N 0.000 description 1
- 229960001404 quinidine Drugs 0.000 description 1
- LISFMEBWQUVKPJ-UHFFFAOYSA-N quinolin-2-ol Chemical compound C1=CC=C2NC(=O)C=CC2=C1 LISFMEBWQUVKPJ-UHFFFAOYSA-N 0.000 description 1
- 229910052705 radium Inorganic materials 0.000 description 1
- HCWPIIXVSYCSAN-UHFFFAOYSA-N radium atom Chemical compound [Ra] HCWPIIXVSYCSAN-UHFFFAOYSA-N 0.000 description 1
- 239000012429 reaction media Substances 0.000 description 1
- 239000012070 reactive reagent Substances 0.000 description 1
- 238000003259 recombinant expression Methods 0.000 description 1
- 239000002684 recombinant hormone Substances 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 238000005215 recombination Methods 0.000 description 1
- 238000004153 renaturation Methods 0.000 description 1
- 230000008439 repair process Effects 0.000 description 1
- 125000006853 reporter group Chemical group 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 239000012465 retentate Substances 0.000 description 1
- 230000001177 retroviral effect Effects 0.000 description 1
- 238000010839 reverse transcription Methods 0.000 description 1
- 238000003757 reverse transcription PCR Methods 0.000 description 1
- 101150030372 rfaB gene Proteins 0.000 description 1
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical compound [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 1
- 210000003705 ribosome Anatomy 0.000 description 1
- IOVGROKTTNBUGK-SJCJKPOMSA-N ritodrine Chemical compound N([C@@H](C)[C@H](O)C=1C=CC(O)=CC=1)CCC1=CC=C(O)C=C1 IOVGROKTTNBUGK-SJCJKPOMSA-N 0.000 description 1
- 229960001634 ritodrine Drugs 0.000 description 1
- 238000005185 salting out Methods 0.000 description 1
- STECJAGHUSJQJN-FWXGHANASA-N scopolamine Chemical compound C1([C@@H](CO)C(=O)O[C@H]2C[C@@H]3N([C@H](C2)[C@@H]2[C@H]3O2)C)=CC=CC=C1 STECJAGHUSJQJN-FWXGHANASA-N 0.000 description 1
- 229960002646 scopolamine Drugs 0.000 description 1
- 239000000932 sedative agent Substances 0.000 description 1
- 230000001624 sedative effect Effects 0.000 description 1
- 238000012764 semi-quantitative analysis Methods 0.000 description 1
- 150000007659 semicarbazones Chemical class 0.000 description 1
- 150000003354 serine derivatives Chemical class 0.000 description 1
- 125000003607 serino group Chemical group [H]N([H])[C@]([H])(C(=O)[*])C(O[H])([H])[H] 0.000 description 1
- 210000002966 serum Anatomy 0.000 description 1
- 230000035939 shock Effects 0.000 description 1
- 125000005630 sialyl group Chemical group 0.000 description 1
- 239000000377 silicon dioxide Substances 0.000 description 1
- 229910052709 silver Inorganic materials 0.000 description 1
- 239000004332 silver Substances 0.000 description 1
- 229940096017 silver fluoride Drugs 0.000 description 1
- REYHXKZHIMGNSE-UHFFFAOYSA-M silver monofluoride Chemical compound [F-].[Ag+] REYHXKZHIMGNSE-UHFFFAOYSA-M 0.000 description 1
- 150000003384 small molecules Chemical class 0.000 description 1
- 239000003998 snake venom Substances 0.000 description 1
- URGAHOPLAPQHLN-UHFFFAOYSA-N sodium aluminosilicate Chemical compound [Na+].[Al+3].[O-][Si]([O-])=O.[O-][Si]([O-])=O URGAHOPLAPQHLN-UHFFFAOYSA-N 0.000 description 1
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 1
- 239000001488 sodium phosphate Substances 0.000 description 1
- 229910000162 sodium phosphate Inorganic materials 0.000 description 1
- ULARYIUTHAWJMU-UHFFFAOYSA-M sodium;1-[4-(2,5-dioxopyrrol-1-yl)butanoyloxy]-2,5-dioxopyrrolidine-3-sulfonate Chemical compound [Na+].O=C1C(S(=O)(=O)[O-])CC(=O)N1OC(=O)CCCN1C(=O)C=CC1=O ULARYIUTHAWJMU-UHFFFAOYSA-M 0.000 description 1
- HHSGWIABCIVPJT-UHFFFAOYSA-M sodium;1-[4-[(2-iodoacetyl)amino]benzoyl]oxy-2,5-dioxopyrrolidine-3-sulfonate Chemical compound [Na+].O=C1C(S(=O)(=O)[O-])CC(=O)N1OC(=O)C1=CC=C(NC(=O)CI)C=C1 HHSGWIABCIVPJT-UHFFFAOYSA-M 0.000 description 1
- 239000007790 solid phase Substances 0.000 description 1
- 230000003381 solubilizing effect Effects 0.000 description 1
- 239000000243 solution Substances 0.000 description 1
- NHXLMOGPVYXJNR-ATOGVRKGSA-N somatostatin Chemical compound C([C@H]1C(=O)N[C@H](C(N[C@@H](CO)C(=O)N[C@@H](CSSC[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@@H](CC=2C3=CC=CC=C3NC=2)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(=O)N1)[C@@H](C)O)NC(=O)CNC(=O)[C@H](C)N)C(O)=O)=O)[C@H](O)C)C1=CC=CC=C1 NHXLMOGPVYXJNR-ATOGVRKGSA-N 0.000 description 1
- 229960000553 somatostatin Drugs 0.000 description 1
- 238000000527 sonication Methods 0.000 description 1
- 239000000600 sorbitol Substances 0.000 description 1
- 238000001179 sorption measurement Methods 0.000 description 1
- 125000006850 spacer group Chemical group 0.000 description 1
- 230000009870 specific binding Effects 0.000 description 1
- 238000004611 spectroscopical analysis Methods 0.000 description 1
- 210000004989 spleen cell Anatomy 0.000 description 1
- 239000003381 stabilizer Substances 0.000 description 1
- 229960000912 stanozolol Drugs 0.000 description 1
- 235000019698 starch Nutrition 0.000 description 1
- 239000008107 starch Substances 0.000 description 1
- 239000008117 stearic acid Substances 0.000 description 1
- 239000008174 sterile solution Substances 0.000 description 1
- 230000001954 sterilising effect Effects 0.000 description 1
- 238000004659 sterilization and disinfection Methods 0.000 description 1
- 230000003637 steroidlike Effects 0.000 description 1
- 150000003431 steroids Chemical class 0.000 description 1
- PJANXHGTPQOBST-UHFFFAOYSA-N stilbene Chemical compound C=1C=CC=CC=1C=CC1=CC=CC=C1 PJANXHGTPQOBST-UHFFFAOYSA-N 0.000 description 1
- 235000021286 stilbenes Nutrition 0.000 description 1
- 230000000638 stimulation Effects 0.000 description 1
- 210000002784 stomach Anatomy 0.000 description 1
- 229960005322 streptomycin Drugs 0.000 description 1
- 229960002317 succinimide Drugs 0.000 description 1
- 125000002128 sulfonyl halide group Chemical group 0.000 description 1
- 150000003461 sulfonyl halides Chemical class 0.000 description 1
- 229910052717 sulfur Inorganic materials 0.000 description 1
- YBBRCQOCSYXUOC-UHFFFAOYSA-N sulfuryl dichloride Chemical class ClS(Cl)(=O)=O YBBRCQOCSYXUOC-UHFFFAOYSA-N 0.000 description 1
- MLKXDPUZXIRXEP-MFOYZWKCSA-N sulindac Chemical compound CC1=C(CC(O)=O)C2=CC(F)=CC=C2\C1=C/C1=CC=C(S(C)=O)C=C1 MLKXDPUZXIRXEP-MFOYZWKCSA-N 0.000 description 1
- 229960000894 sulindac Drugs 0.000 description 1
- 239000000829 suppository Substances 0.000 description 1
- 238000010189 synthetic method Methods 0.000 description 1
- 230000001839 systemic circulation Effects 0.000 description 1
- 239000000454 talc Substances 0.000 description 1
- 235000012222 talc Nutrition 0.000 description 1
- 229910052623 talc Inorganic materials 0.000 description 1
- 229960001603 tamoxifen Drugs 0.000 description 1
- NRUKOCRGYNPUPR-QBPJDGROSA-N teniposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@@H](OC[C@H]4O3)C=3SC=CC=3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 NRUKOCRGYNPUPR-QBPJDGROSA-N 0.000 description 1
- 229960001278 teniposide Drugs 0.000 description 1
- 229920001897 terpolymer Polymers 0.000 description 1
- IWVCMVBTMGNXQD-UHFFFAOYSA-N terramycin dehydrate Natural products C1=CC=C2C(O)(C)C3C(O)C4C(N(C)C)C(O)=C(C(N)=O)C(=O)C4(O)C(O)=C3C(=O)C2=C1O IWVCMVBTMGNXQD-UHFFFAOYSA-N 0.000 description 1
- 229960005353 testolactone Drugs 0.000 description 1
- BPEWUONYVDABNZ-DZBHQSCQSA-N testolactone Chemical compound O=C1C=C[C@]2(C)[C@H]3CC[C@](C)(OC(=O)CC4)[C@@H]4[C@@H]3CCC2=C1 BPEWUONYVDABNZ-DZBHQSCQSA-N 0.000 description 1
- 229960003604 testosterone Drugs 0.000 description 1
- 229960002372 tetracaine Drugs 0.000 description 1
- GKCBAIGFKIBETG-UHFFFAOYSA-N tetracaine Chemical compound CCCCNC1=CC=C(C(=O)OCCN(C)C)C=C1 GKCBAIGFKIBETG-UHFFFAOYSA-N 0.000 description 1
- 229960002180 tetracycline Drugs 0.000 description 1
- 229930101283 tetracycline Natural products 0.000 description 1
- 235000019364 tetracycline Nutrition 0.000 description 1
- 150000003522 tetracyclines Chemical class 0.000 description 1
- 150000004044 tetrasaccharides Chemical class 0.000 description 1
- MPLHNVLQVRSVEE-UHFFFAOYSA-N texas red Chemical compound [O-]S(=O)(=O)C1=CC(S(Cl)(=O)=O)=CC=C1C(C1=CC=2CCCN3CCCC(C=23)=C1O1)=C2C1=C(CCC1)C3=[N+]1CCCC3=C2 MPLHNVLQVRSVEE-UHFFFAOYSA-N 0.000 description 1
- 229940126585 therapeutic drug Drugs 0.000 description 1
- 229960002178 thiamazole Drugs 0.000 description 1
- 150000007970 thio esters Chemical class 0.000 description 1
- 150000003568 thioethers Chemical class 0.000 description 1
- 229960002784 thioridazine Drugs 0.000 description 1
- 210000001685 thyroid gland Anatomy 0.000 description 1
- XUIIKFGFIJCVMT-UHFFFAOYSA-N thyroxine-binding globulin Natural products IC1=CC(CC([NH3+])C([O-])=O)=CC(I)=C1OC1=CC(I)=C(O)C(I)=C1 XUIIKFGFIJCVMT-UHFFFAOYSA-N 0.000 description 1
- 210000002303 tibia Anatomy 0.000 description 1
- 229960004605 timolol Drugs 0.000 description 1
- 229960003087 tioguanine Drugs 0.000 description 1
- 229960000187 tissue plasminogen activator Drugs 0.000 description 1
- 230000017423 tissue regeneration Effects 0.000 description 1
- 229960000707 tobramycin Drugs 0.000 description 1
- NLVFBUXFDBBNBW-PBSUHMDJSA-N tobramycin Chemical compound N[C@@H]1C[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N NLVFBUXFDBBNBW-PBSUHMDJSA-N 0.000 description 1
- JIVZKJJQOZQXQB-UHFFFAOYSA-N tolazoline Chemical compound C=1C=CC=CC=1CC1=NCCN1 JIVZKJJQOZQXQB-UHFFFAOYSA-N 0.000 description 1
- 229960002312 tolazoline Drugs 0.000 description 1
- DVKJHBMWWAPEIU-UHFFFAOYSA-N toluene 2,4-diisocyanate Chemical compound CC1=CC=C(N=C=O)C=C1N=C=O DVKJHBMWWAPEIU-UHFFFAOYSA-N 0.000 description 1
- 101150093706 tor gene Proteins 0.000 description 1
- 229940125725 tranquilizer Drugs 0.000 description 1
- 239000003204 tranquilizing agent Substances 0.000 description 1
- 230000002936 tranquilizing effect Effects 0.000 description 1
- 108010004486 trans-sialidase Proteins 0.000 description 1
- 230000005030 transcription termination Effects 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 238000001890 transfection Methods 0.000 description 1
- 238000006276 transfer reaction Methods 0.000 description 1
- 238000011426 transformation method Methods 0.000 description 1
- 102000003601 transglutaminase Human genes 0.000 description 1
- 230000014621 translational initiation Effects 0.000 description 1
- 230000032258 transport Effects 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- 229960003500 triclosan Drugs 0.000 description 1
- ITMCEJHCFYSIIV-UHFFFAOYSA-N triflic acid Chemical compound OS(=O)(=O)C(F)(F)F ITMCEJHCFYSIIV-UHFFFAOYSA-N 0.000 description 1
- ZEWQUBUPAILYHI-UHFFFAOYSA-N trifluoperazine Chemical compound C1CN(C)CCN1CCCN1C2=CC(C(F)(F)F)=CC=C2SC2=CC=CC=C21 ZEWQUBUPAILYHI-UHFFFAOYSA-N 0.000 description 1
- 229960002324 trifluoperazine Drugs 0.000 description 1
- 229940035722 triiodothyronine Drugs 0.000 description 1
- CBEQULMOCCWAQT-WOJGMQOQSA-N triprolidine Chemical compound C1=CC(C)=CC=C1C(\C=1N=CC=CC=1)=C/CN1CCCC1 CBEQULMOCCWAQT-WOJGMQOQSA-N 0.000 description 1
- 229960001128 triprolidine Drugs 0.000 description 1
- RYFMWSXOAZQYPI-UHFFFAOYSA-K trisodium phosphate Chemical compound [Na+].[Na+].[Na+].[O-]P([O-])([O-])=O RYFMWSXOAZQYPI-UHFFFAOYSA-K 0.000 description 1
- 208000001072 type 2 diabetes mellitus Diseases 0.000 description 1
- 108010087967 type I signal peptidase Proteins 0.000 description 1
- 125000002233 tyrosyl group Chemical group 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 210000001364 upper extremity Anatomy 0.000 description 1
- 229940035893 uracil Drugs 0.000 description 1
- DNYWZCXLKNTFFI-UHFFFAOYSA-N uranium Chemical compound [U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U] DNYWZCXLKNTFFI-UHFFFAOYSA-N 0.000 description 1
- 229960005486 vaccine Drugs 0.000 description 1
- 210000003934 vacuole Anatomy 0.000 description 1
- 239000004474 valine Substances 0.000 description 1
- 239000005526 vasoconstrictor agent Substances 0.000 description 1
- 239000003071 vasodilator agent Substances 0.000 description 1
- 235000015112 vegetable and seed oil Nutrition 0.000 description 1
- 235000019871 vegetable fat Nutrition 0.000 description 1
- 229960001722 verapamil Drugs 0.000 description 1
- 238000012795 verification Methods 0.000 description 1
- 229960003048 vinblastine Drugs 0.000 description 1
- JXLYSJRDGCGARV-XQKSVPLYSA-N vincaleukoblastine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 JXLYSJRDGCGARV-XQKSVPLYSA-N 0.000 description 1
- OGWKCGZFUXNPDA-XQKSVPLYSA-N vincristine Chemical compound C([N@]1C[C@@H](C[C@]2(C(=O)OC)C=3C(=CC4=C([C@]56[C@H]([C@@]([C@H](OC(C)=O)[C@]7(CC)C=CCN([C@H]67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)C[C@@](C1)(O)CC)CC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-XQKSVPLYSA-N 0.000 description 1
- 229960004528 vincristine Drugs 0.000 description 1
- OGWKCGZFUXNPDA-UHFFFAOYSA-N vincristine Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(OC(C)=O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-UHFFFAOYSA-N 0.000 description 1
- 239000013603 viral vector Substances 0.000 description 1
- 238000001262 western blot Methods 0.000 description 1
- 238000010626 work up procedure Methods 0.000 description 1
- 230000029663 wound healing Effects 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
- 229940098232 yersinia enterocolitica Drugs 0.000 description 1
- 150000003952 β-lactams Chemical class 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/575—Hormones
- C07K14/61—Growth hormones [GH] (Somatotropin)
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P5/00—Drugs for disorders of the endocrine system
- A61P5/06—Drugs for disorders of the endocrine system of the anterior pituitary hormones, e.g. TSH, ACTH, FSH, LH, PRL, GH
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
Definitions
- Human growth Hormone (hGH) and agonist variants thereof are members of a family of recombinant proteins, described in U.S. Pat. No. 4,658,021 and U.S. Pat. No. 5,633,352. Their recombinant production and methods of use are detailed in U.S. Pat. Nos. 4,342,832, 4,601,980; U.S. Pat. No. 4,898,830; U.S. Pat. No. 5,424,199; and U.S. Pat. No. 5,795,745.
- Human growth hormone participates in various aspects of the regulation of normal human growth and development. Through interaction with its receptors, this 22 kDa pituitary hormone modulates a multitude of biological effects, such as linear growth
- hGH Both purified and recombinant hGH have been used for treating conditions and diseases due to hGH deficiency, e.g., dwarfism in children.
- an immunogenic response to an administered peptide can neutralize the peptide and/or lead to the development of an allergic response in the patient.
- Other deficiencies of therapeutic glycopeptides include suboptimal potency and rapid clearance rates.
- the problems inherent in peptide therapeutics are recognized in the art, and various methods of eliminating the problems have been investigated. For example, to provide soluble peptide therapeutics, synthetic polymers have been attached to the peptide backbone.
- PEG Poly(ethyleneglycol)
- PEG poly(ethyleneglycol)
- the use of to PEG to derivatize peptide therapeutics has been demonstrated to reduce the immunogenicity of the peptides.
- U.S. Pat. No. 4,179,337 (Davis et al.) concerns non-immunogenic polypeptides, such as enzymes and peptide hormones coupled to polyethylene glycol (PEG) or polypropylene glycol.
- poly(ethyleneglycol) is added in an essentially random, non-specific manner to reactive residues on a peptide backbone.
- a derivitization strategy that results in the formation of a specifically labeled, readily characterizable, essentially homogeneous product.
- a promising route to preparing specifically labeled peptides is through the use of enzymes, such as glycosyltransferases to append a modified sugar moiety onto a peptide.
- Enzyme-based syntheses have the advantages of regioselectivity and stereoselectivity. Moreover, enzymatic syntheses are performed using unprotected substrates. Three principal classes of enzymes are used in the synthesis of carbohydrates, glycosyltransferases (e.g. , sialyltransferases, oligosaccharyltransferases, N- acetylglucosaminyltransferases), and glycosidases.
- glycosyltransferases e.g. , sialyltransferases, oligosaccharyltransferases, N- acetylglucosaminyltransferases
- glycosidases are further classified as exoglycosidases (e.g., ⁇ -mannosidase, ⁇ -glucosidase), and endoglycosidases (e.g., Endo-A, Endo-M).
- exoglycosidases e.g., ⁇ -mannosidase, ⁇ -glucosidase
- endoglycosidases e.g., Endo-A, Endo-M
- Glycosyltransferases modify the oligosaccharide structures on glycopeptides, producing specific products with good stereochemical and regiochemical control. Glycosyltransferases are used to prepare oligosaccharides and to modify terminal N- and O- on glycopeptides produced in mammalian cells.
- the terminal oligosaccharides of glycopeptides have been completely sialylated and/or fucosylated to provide more consistent sugar structures, which improves glycopeptide pharmacodynamics and a variety of other biological properties.
- ⁇ -1,4- galactosyltransferase was used to synthesize lactosamine, an illustration of the utility of glycosyltransferases in the synthesis of carbohydrates (see, e.g., Wong et al, J. Org. Chem. 47: 5416-5418 (1982)).
- ⁇ - sialyltransferases to transfer sialic acid from cytidine-5'-monophospho-N-acetylneuraminic acid to the 3-OH or 6-OH of galactose (see, e.g., Kevin et al, Chem. Eur. J. 2: 1359-1362 (1996)).
- Fucosyltransferases are used in synthetic pathways to transfer a fucose unit from guanosine-5'-diphosphofucose to a specific hydroxyl of a saccharide acceptor.
- Ichikawa prepared sialyl Lewis-X by a method that involves the fucosylation of sialylated lactosamine with a cloned fucosyltransferase (Ichikawa et al, J. Am. Chem. Soc. 114: 9283- 9298 (1992)).
- a cloned fucosyltransferase for a discussion of recent advances in glycoconjugate synthesis for therapeutic use see, Koeller et al, Nature Biotechnology 18: 835-841 (2000). See also, U.S. Patent No. 5,876,980; 6,030,815; 5,728,554; 5,922,577; and WO/9831826.
- Glycosidases can also be used to prepare saccharides. Glycosidases normally catalyze the hydrolysis of a glycosidic bond. Under appropriate conditions, however, they can be used to form this linkage. Most glycosidases used for carbohydrate synthesis are exoglycosidases; the glycosyl transfer occurs at the non-reducing terminus of the substrate. The glycosidase takes up a glycosyl donor in a glycosyl-enzyme intermediate that is either intercepted by water to give the hydrolysis product, or by an acceptor, to give a new glycoside or oligosaccharide.
- An exemplary pathway using an exoglycosidase is the synthesis of the core trisaccharide of all N-linked glycopeptides, including the difficult ⁇ - mannoside linkage, which was formed by the action of ⁇ -mannosidase (Singh et al, Chem. Commun. 993-994 (1996)).
- a mutant glycosidase has been prepared in which the normal nucleophilic amino acid within the active site is changed to a non-nucleophilic amino acid.
- the mutant enzymes do not hydrolyze glycosidic linkages, but can still form them.
- the mutant glycosidases are used to prepare oligosaccharides using an ⁇ -glycosyl fluoride donor and a glycoside acceptor molecule (Withers et al, U.S. Patent No. 5,716,812).
- mutant glycosidases are ilstful tor tytlM ⁇ -
- endoglycosidases are also utilized to prepare carbohydrates. Methods based on the use of endoglycosidases have the advantage that an oligosaccharide, rather than a monosaccharide, is transferred. Oligosaccharide fragments have been added to substrates using en o- ⁇ -N- acetylglucosamines such as endo- ⁇ , endo-M (Wang et al, Tetrahedron Lett. 37: 1975-1978); and Haneda et al, Carbohydr. Res. 292: 61-70 (1996)).
- the tetrasaccharide sialyl Lewis X was then enzymatically rebuilt on the remaining GlcNAc anchor site on the now homogenous protein by the sequential use of ⁇ -1,4- galactosyltransferase, ⁇ -2,3-sialyltransferase and ⁇ -l,3-fucosyltransferase V. Each enzymatically catalyzed step proceeded in excellent yield.
- Brossmer et al. (U.S. Patent No. 5,405,753) discloses the formation of a fluorescent-labeled cytidine monophosphate ("CMP") derivative of sialic acid and the use of the fluorescent glycoside in an assay for sialyl transferase activity and for the fluorescent-labeling of cell surfaces, glycoproteins and gangliosides.
- CMP cytidine monophosphate
- Gross et al. (Analyt. ⁇ Vkh ⁇ h W6 m ⁇ 9: ⁇ bb a similar assay.
- Bean et al. (U.S. Patent No.
- 5,432,059 discloses an assay for glycosylation deficiency disorders utilizing reglycosylation of a deficiently glycosylated protein.
- the deficient protein is reglycosylated with a fluorescent- labeled CMP glycoside.
- Each of the fluorescent sialic acid derivatives is substituted with the fluorescent moiety at either the 9-position or at the amine that is normally acetylated in sialic acid.
- the methods using the fluorescent sialic acid derivatives are assays for the presence of glycosyltransferases or for non-glycosylated or improperly glycosylated glycoproteins.
- the assays are conducted on small amounts of enzyme or glycoprotein in a sample of biological origin.
- the enzymatic derivatization of a glycosylated or non-glycosylated peptide on a preparative or industrial scale using a modified sialic acid has not been disclosed or suggested.
- Enzymatic methods have also been used to activate glycosyl residues on a glycopeptide towards subsequent chemical elaboration.
- the glycosyl residues are typically activated using galactose oxidase, which converts a terminal galactose residue to the corresponding aldehyde.
- the aldehyde is subsequently coupled to an amine-containing modifying group.
- Casares et al. (Nature Biotech. 19: 142 (2001)) have attached doxorubicin to the oxidized galactose residues of a recombinant MHCII-peptide chimera. ;
- Glycosyl residues have also been modified to bear ketone groups.
- Mahal and co-workers (Science 276: 1125 (1997)) have prepared N-levulinoyl mannosamine (“ManLev”), which has a ketone functionality at the position normally occupied by the acetyl group in the natural substrate. Cells were treated with the ManLev, thereby incorporating a ketone group onto the cell surface. See, also Saxon et al, Science 287: 2007 (2000); Hang et al, J. Am. Chem. Soc. 123: 1242 (2001); Yarema et /., J Biol. Chem.
- Carbohydrates are attached to glycopeptides in several ways of which N-linked to asparagine and mucin-type O-linked to serine and threonine are the most relevant for recombinant glycoprotein therapeuctics.
- a determining factor for initiation of glycosylation of a protein is the primary sequence context, although clearly other factors including protein region and conformation play roles.
- N-linked glycosylation occurs at the consensus sequence NXS/T, where X can be any amino acid but proline.
- the present invention answers these needs by providing hGH mutants that contain newly introduced N-linked or O-linked glycosylation sites, providing flexibility in glycosylation and/or glycopegylation of these recombinant hGH mutants.
- the invention provides an industrially practical method for the modification of N- or O-linked mutant hGH peptides with modifying groups such as water-soluble polymers, therapeutic moieties, biomolecules, and the like.
- modifying groups such as water-soluble polymers, therapeutic moieties, biomolecules, and the like.
- the modified mutant hGH has improved properties, which enhance its use as a therapeutic or diagnostic agent.
- the present invention provides an isolated nucleic acid comprising a polynucleotide sequence encoding a mutant human growth hormone.
- the mutant human growth hormone comprises an N-linked or O-linked glycosylation site that is not present in wild-type human growth hormone.
- the wild-type human growth hormone has the amino acid sequence of SEQ ID NO:l or SEQ ID NO:2.
- the mutant human growth hormone includes the amino acid sequence of SEQ ID NO:3, 4, 5, 6, 7, 8, or 9.
- the present invention provides an expression cassette or a cell that comprises a nucleic acid, e.g., an isolated nucleic acid, including a polynucleotide sequence encoding a mutant human growth hormone.
- the mutant human growth hormone includes an N-linked or O-linked glycosylation site that is not present in the wild-type human growth hormone.
- the present invention provides a mutant human growth hormone, that includes an N-linked or O-linked glycosylation site that is not present in the wild-type human growth hormone.
- the wild-type human growth hormone has the amino acid sequence of SEQ ID NO:l or SEQ ID NO:2.
- the mutant human growth hormone comprises the amino acid sequence of SEQ ID NO:3, 4, 5, 6, 7, 8, or 9. a method for making a mutant human growth hormone that includes an N-linked or O-linked glycosylation site that is not present in the wild-type human growth hormone. This method includes the steps of recombinantly producing the mutant human growth hormone, and glycosylating the mutant human growth hormone at the new glycosylation site.
- the wild-type human growth hormone has the amino acid sequence of SEQ ID NO: 1 or SEQ ID NO:2.
- the mutant human growth hormone comprises the amino acid sequence of SEQ ID NO:3, 4, 5, 6, 7, 8, or 9.
- the present invention provides a pharmaceutical composition having a therapeutically effective amount of a mutant human growth hormone that includes an N-linked or O-linked glycosylation site not present in the wild-type human growth hormone.
- the wild-type human growth hormone has the amino acid sequence of SEQ ID NO: 1 or SEQ ID NO:2.
- the mutant human growth hormone comprises the amino acid sequence of SEQ ID NO:3, 4, 5, 6, 7, 8, or 9.
- the present invention provides a method for treating human growth hormone deficiency in a subject.
- the method includes administering to the subject an amount of a mutant human growth hormone effective to treat or ameliorate the growth hormone deficiency.
- the mutant human growth hormone used in this method comprises an N-linked or O-linked glycosylation site that does not exist in the corresponding wild-type human growth hormone.
- the corresponding wild-type human growth hormone has the amino acid sequence of SEQ ID NO:l or SEQ ID NO:2.
- the mutant human growth hormone comprises the amino acid sequence of SEQ ID NO:3, 4, 5, 6, 7, 8, or 9.
- the mutant human growth hormone is optionally conjugates to one or more modifying group, preferably via glycoconjugation giving rise to a glycosyl linking group between the glycosylation site and the modifying group.
- An exemplary modifying group is poly(ethylene glycol).
- FIG. 1 is the amino acid sequences of GH-N (pituitary derived hGH) and GH-N (placental derived hGH). The arrows indicate the amino acid position for a mutational introduction of (GH- ⁇ ) or a naturally existing (GH-N) ⁇ -linked glycosylation site.
- FIG. 2 is the crystal structure depiction of a glycosylated GH- ⁇ mutant hGH (Lysl40 to Asnl40) and its receptor polypeptide.
- FIG. 3 are glycoPEGylation schemes for insect cell and mammalian cell produced hGH ⁇ -linked glycan mutants.
- FIG. 4 shows the glycoPEGylation of an Escherichia coli produced hGH O-linked glycan mutant.
- FIG. 5 displays alternate mutants of GH- ⁇ to introduce glycosylation sites.
- the arrows indicate the protein loop regions of GH- ⁇ into which a glycosylation site may be introduced.
- FIG. 6 are the amino acid sequences of six (6) different O-linked glycosylation sites that may be introduced into pituitary derived hGH (GH- ⁇ ).
- GH- ⁇ pituitary derived hGH
- the wild-type amino acid sequence for GH- ⁇ is also shown for comparison.
- the arrows indicate the threonine residue of the GH- ⁇ glycan mutant on which O-linked glycosylation will occur.
- FIG. 7 are the amino acid sequences of hGH O-linked GH- ⁇ mutant 134(rtg) -> ttt and hGH O-linked 5' GH- ⁇ mutant in which amino acids -3 to -1 (ptt) are inserted at the amino terminus, resulting in a 194 amino acid hGH polypeptide.
- FIG. 8 are the amino acid sequences of hGH O-linked GH- ⁇ mutant 134(rtg) -» ttg and hGH O-linked 5' GH- ⁇ mutant in which amino acids -3 to -1 (mvt) are inserted at the amino terminus, resulting in a 194 amino acid hGH polypeptide.
- FIG. 9A depicts the amino acid sequence of mature human growth hormone (GH- ⁇ ) (SEQ ID NO: 1).
- FIG. 9B depicts the amino acid sequence of mature human growth hormone (GH-N) (SEQ ID ⁇ ,O:2).
- FIG. 9C depicts the amino acid sequence of human growth hormone mutant 1 (SEQ ID NO:3).
- FIG. 9D depicts the amino acid sequence of human growth hormone mutant 2 (SEQ ID NO:4).
- FIG. 9E depicts the amino acid sequence of human growth hormone mutant 3 (SEQ ID NO: 5).
- FIG. 9F depicts the amino acid sequence of human growth hormone mutant 4 (SEQ ID NO: 6).
- FIG. 9G depicts the amino acid sequence of human growth hormone mutant 5 (SEQ ID NO:7).
- FIG. 9H depicts the ammo aeid ⁇ feq ⁇ 'eft ' ce ⁇ ol li ⁇ ffia ' n ⁇ fr ⁇ 'wth hormone mutant 6 (SEQ ID NO:8).
- FIG. 91 depicts the amino acid sequence of human growth hormone mutant 7 (SEQ ID NO:9).
- nucleic acid or “polynucleotide” refers to deoxyribonucleic acids
- DNA DNA
- RNA ribonucleic acids
- DNA DNA
- RNA ribonucleic acids
- the term encompasses nucleic acids containing known analogues of natural nucleotides that have similar binding properties as the reference nucleic acid and are metabolized in a manner similar to naturally occurring nucleotides.
- a particular nucleic acid sequence also implicitly encompasses conservatively modified variants thereof (e.g., degenerate codon substitutions), alleles, orthologs, SNPs, and complementary sequences as well as the sequence explicitly indicated.
- degenerate codon substitutions may be achieved by generating sequences in which the third position of one or more selected (or all) codons is substituted with mixed- base and/or deoxyinosine residues (Batzer et al, Nucleic Acid Res. 19:5081 (1991); Ohtsuka et al, J. Biol. Chem. 260:2605-2608 (1985); and Rossolini et al, Mol Cell. Probes 8:91-98 (1994)).
- nucleic acid is used interchangeably with gene, cDNA, and mRNA encoded by a gene.
- gene means the segment of DNA involved in producing a polypeptide chain. It may include regions preceding and following the coding region (leader and trailer) as well as intervening sequences (introns) between individual coding segments (exons).
- nucleic acid or protein when applied to a nucleic acid or protein, denotes that the nucleic acid or protein is essentially free of other cellular components with which it is associated in the natural state. It is preferably in a homogeneous state although it can be in either a dry or aqueous solution. Purity and homogeneity are typically determined using analytical chemistry techniques such as polyacrylamide gel electrophoresis or high performance liquid chromatography. A protein that is the predominant species present in a preparation is substantially purified. In particular, an isolated gene is separated from open reading frames that flank the gene and encode a protein other than the gene of interest. The term "purified" denotes that a nucleic acid or protein gives rise to essentially one band in an electrophoretic gel.
- nucleic acid or protein is at least 85% pure, more preferably at least 95% pure, and most preferably at least 99% pure.
- Naturally occurring amino acids are those encoded by the genetic code, as well as those amino acids that are later modified, e.g., hydroxyproline, ⁇ - carboxyglutamate, and O-phosphoserine.
- Amino acid analogs refers to compounds that have the same basic chemical structure as a naturally occurring amino acid, i.e., an ⁇ carbon that is bound to a hydrogen, a carboxyl group, an amino group, and an R group, e.g., homoserine, norleucine, methionine sulfoxide, methionine methyl sulfonium. Such analogs have modified R groups (e.g., norleucine) or modified peptide backbones, but retain the same basic chemical structure as a naturally occurring amino acid.
- Amino acid mimetics refers to chemical compounds having a structure that is different from the general chemical structure of an amino acid, but that functions in a manner similar to a naturally occurring amino acid.
- Amino acids may be referred to herein by either the commonly known three letter symbols or by the one-letter symbols recommended by the IUPAC-IUB Biochemical Nomenclature Commission. Nucleotides, likewise, may be referred to by their commonly accepted single-letter codes.
- "Conservatively modified variants” applies to both amino acid and nucleic acid sequences. With respect to particular nucleic acid sequences, “conservatively modified variants” refers to those nucleic acids that encode identical or essentially identical amino acid sequences, or where the nucleic acid does not encode an amino acid sequence, to essentially identical sequences. Because of the degeneracy of the genetic code, a large number of functionally identical nucleic acids encode any given protein.
- the codons GCA, GCC, GCG and GCU all encode the amino acid alanine.
- the codon can be altered to any of the corresponding codons described without altering the encoded polypeptide.
- Such nucleic acid variations are "silent variations," which are one species of conservatively modified variations. Every nucleic acid sequence herein that encodes a polypeptide also describes every possible silent variation of the nucleic acid.
- each codon in a nucleic acid can be modified to yield a functionally identical molecule.
- Accordingl 1 ; afeh' l ⁇ nt Jl variIlior ⁇ ''6 , f a" ' nucleic -acid that encodes a polypeptide is implicit in each described sequence.
- amino acid sequences one of skill will recognize that individual substitutions, deletions or additions to a nucleic acid, peptide, polypeptide, or protein sequence which alters, adds or deletes a single amino acid or a small percentage of amino acids in the encoded sequence is a "conservatively modified variant" where the alteration results in the substitution of an amino acid with a chemically similar amino acid. Conservative substitution tables providing functionally similar amino acids are well known in the art. Such conservatively modified variants are in addition to and do not exclude polymorphic variants, interspecies homologs, and alleles of the invention.
- Amino acids may be referred to herein by either their commonly known three letter symbols or by the one-letter symbols recommended by the IUPAC-IUB Biochemical Nomenclature Commission. Nucleotides, likewise, may be referred to by their commonly accepted single-letter codes.
- amino acid residues are numbered according to their relative positions from the left most residue, which is numbered 1, in an unmodified wild- type polypeptide sequence.
- Proximate a proline residue refers to an amino acid that is less than about 10 amino acids removed from a proline residue, preferably, less than about 9, 8, 7, 6 or 5 amino acids removed from a proline residue, more preferably, less than about 4, 3, 2 or FT ⁇ si ⁇ ue's r ⁇ move ⁇ 'irom.a ⁇ iOiine'Tesidue.
- the amino acid "proximate a proline residue” may be on the C- or N-terminal side of the proline residue.
- Polypeptide “peptide,” and “protein” are used interchangeably herein to refer to a polymer of amino acid residues. All three terms apply to amino acid polymers in which one or more amino acid residue is an artificial chemical mimetic of a corresponding naturally occurring amino acid, as well as to naturally occurring amino acid polymers and non- naturally occurring amino acid polymers. As used herein, the terms encompass amino acid chains of any length, including full-length proteins, wherein the amino acid residues are linked by covalent peptide bonds.
- mutating refers to the deletion, insertion, or substitution of any nucleotide or amino acid residue, by chemical, enzymatic, or any other means, in a polynucleotide sequence encoding a wild-type human growth hormone or the amino acid sequence of a wild-type human growth hormone, respectively, such that the amino acid sequence of the resulting human growth hormone comprises at least one N- or O-linked glycosylation site that does not exist in the corresponding wild-type human growth hormone.
- both conservative and non-conservative substitutions may be used to create a hGH mutant that contains a new N- or O-linked glycosylation site.
- the site for a mutation introducing a new N- or O-linked glycosylation site may be located anywhere in the polypeptide.
- Exemplary amino acid sequences for human growth hormone mutants are depicted in SEQ ID NOs:3-9.
- a "mutant human growth hormone" of this invention thus comprises at least one mutated amino acid residue.
- the wild-type human growth hormone whose coding sequence is modified to generate a mutant human growth hormone is referred to in this application as "the corresponding wild-type human growth hormone.”
- SEQ ID NO:l is the amino acid sequence of the corresponding wild-type human growth hormone for mutant human growth hormones having the amino acid sequences of SEQ ID NOs:3-9.
- the term "effective amount,” as used herein, refers to an amount that produces therapeutic effects for which a substance is administered.
- the effects include the prevention, correction, or inhibition of progression of the symptoms of a disease/condition and related complications to any detectable extent.
- the exact amount will depend on the purpose of the ttea ⁇ m ⁇ nt, a ⁇ d «- iii"i'e' asfe a a'b "by one skilled in the art using known techniques (see, e.g., Lieberman, Pharmaceutical Dosage Forms (vols. 1-3, 1992); Lloyd, The Art, Science and Technology of Pharmaceutical Compounding (1999); and Pickar, Dosage Calculations (1999)).
- modified sugar refers to a naturally- or non-naturally- occurring carbohydrate that is enzymatically added onto an amino acid or a glycosyl residue of a peptide in a process of the invention.
- the modified sugar is selected from a number of enzyme substrates including, but not limited to sugar nucleotides (mono-, di-, and tri- phosphates), activated sugars (e.g., glycosyl halides, glycosyl mesylates) and sugars that are neither activated nor nucleotides.
- the "modified sugar” is covalently fiinctionalized with a "modifying group.”
- modifying groups include, but are not limited to, water-soluble polymers, therapeutic moieties, diagnostic moieties, biomolecules and the like.
- the modifying group is preferably not a naturally occurring, or an unmodified carbohydrate.
- the locus of functionalization with the modifying group is selected such that it does not prevent the "modified sugar” from being added enzymatically to a peptide.
- water-soluble refers to moieties that have some detectable degree of solubility in water. Methods to detect and/or quantify water solubility are well known in the art.
- Exemplary water-soluble polymers include peptides, saccharides, poly(ethers), poly(amines), poly(carboxylic acids) and the like. Peptides can have mixed sequences of be composed of a single amino acid, e.g., poly(lysine).
- An exemplary polysaccharide is poly(sialic acid).
- An exemplary poly(ether) is poly(ethylene glycol), e.g., m-PEG.
- Poly(ethylene imine) is an exemplary polyamine
- poly(acrylic) acid is a representative poly(carboxylic acid).
- the polymer backbone of the water-soluble polymer can be poly(ethylene glycol) (i.e. PEG).
- PEG poly(ethylene glycol)
- other related polymers are also suitable for use in the practice of this invention and that the use of the term PEG or poly(ethylene glycol) is intended to be inclusive and not exclusive in this respect.
- PEG includes poly(ethylene glycol) in any of its forms, including alkoxy PEG, difunctional PEG, multiarmed PEG, forked PEG, branched PEG, pendent PEG (i.e. PEG or related polymers having one or more functional groups pendent to the polymer backbone), or PEG with degradable linkages therein.
- ⁇ ynlef bacr ⁇ hiPc n be linear or branched.
- Branched polymer backbones are generally known in the art.
- a branched polymer has a central branch core moiety and a plurality of linear polymer chains linked to the central branch core.
- PEG is commonly used in branched forms that can be prepared by addition of ethylene oxide to various polyols, such as glycerol, pentaerythritol and sorbitol.
- the central branch moiety can also be derived from several amino acids, such as lysine.
- the branched poly(ethylene glycol) can be represented in general form as R(-PEG-OH).sub.m in which R represents the core moiety, such as glycerol or pentaerythritol, and m represents the number of arms.
- R represents the core moiety, such as glycerol or pentaerythritol
- m represents the number of arms.
- Multi-armed PEG molecules such as those described in U.S. Pat. No. 5,932,462, which is incorporated by reference herein in its entirety, can also be used as the polymer backbone.
- polymers are also suitable for the invention.
- suitable polymers include, but are not limited to, other poly(alkylene glycols), such as poly(propylene glycol) ("PPG"), copolymers of ethylene glycol and propylene glycol and the like, poly(oxyethylated polyol), poly(olefmic alcohol), poly(vinylpyrrolidone), poly(hydroxypropylmethacrylamide), poly( ⁇ -hydroxy acid), poly(vinyl alcohol), polyphosphazene, polyoxazoline, poly(N-acryloylmorpholine), such as described in U.S.
- PPG poly(propylene glycol)
- copolymers of ethylene glycol and propylene glycol and the like poly(oxyethylated polyol), poly(olefmic alcohol), poly(vinylpyrrolidone), poly(hydroxy
- the "area under the curve” or "AUC”, as used herein in the context of administering a peptide drug to a patient, is defined as total area under the curve that describes the concentration of drug in systemic circulation in the patient as a function of time from zero to infinity.
- half-life or "Wi" in the context of administering a peptide drug to a patient, is defined as the time required for plasma concentration of a drug in a patient to be reduced by one half. There may be more than one half-life associated with the peptide drug depending on multiple clearance mechanisms, redistribution, and other mechanisms well known in the art. Usually, alpha and beta half-lives are defined such that the alpha phase is associated with redistribution, and the beta phase is associated with clearance. However, with protein drugs that are, for the most part, confined to the bloodstream! th*e "dan be- at'l ⁇ aS ⁇ two clearance half-lives.
- rapid beta phase clearance may be mediated via receptors on macrophages, or endothelial cells that recognize terminal galactose, N-acetylgalactosamine, N-acetylglucosamine, mannose, or fucose.
- Slower beta phase clearance may occur via renal glomerular filtration for molecules with an effective radius ⁇ 2 nm (approximately 68 kD) and/or specific or nonspecific uptake and metabolism in tissues.
- GlycoPEGylation may cap terminal sugars (e.g., galactose or N-acetylgalactosamine) and thereby block rapid alpha phase clearance via receptors that recognize these sugars.
- glycoconjugation refers to the enzymatically mediated conjugation of a modified sugar species to an amino acid or glycosyl residue of a polypeptide, e.g., a mutant human growth hormone of the present invention.
- a subgenus of "glycoconjugation” is "glycol-PEGylation,” in which the modifying group of the modified sugar is poly(ethylene glycol), and alkyl derivative (e.g., m-PEG) or reactive derivative (e.g., H2N-PEG, HOOC-PEG) thereof.
- glycosyl linking group refers to a glycosyl residue to which a modifying group (e.g., PEG moiety, therapeutic moiety, biomolecule) is covalently attached; the glycosyl linking group joins the modifying group to the remainder of the conjugate.
- the "glycosyl linking group” becomes covalently attached to a glycosylated or unglycosylated peptide, thereby linking the agent to an amino acid and/or glycosyl residue on the peptide.
- a “glycosyl linking group” is generally derived from a "modified sugar” by the enzymatic attachment of the "modified sugar” to an amino acid and/or glycosyl residue of the peptide.
- the glycosyl linking group can be a saccharide- derived structure that is degraded during formation of modifying group-modified sugar d ⁇ assette or the glycosyl linking group may be intact.
- an “intact glycosyl linking group” refers to a linking group that is derived from a glycosyl moiety in which the saccharide monomer that links the modifying group and to the remainder of the conjugate is not degraded, e.g., oxidized, e.g., by sodium metaperiodate.
- “Intact glycosyl linking groups” of the invention may be derived from a naturally occurring oligosaccharide by addition of glycosyl unit(s) or removal of one or more glycosyl unit from a parent saccharide structure.
- targeting moiety refers to species that will selectively localize in a particular tissue or region of the body. The localization is mediated by specific recognition of molecular determinants, molecular size of the targeting agent or conjugate, ionic interactions, hydrophobic interactions and the like. Other mechanisms of targeting an agent to a particular tissue or region are known to those of skill in the art.
- exemplary targeting moieties include antibodies, antibody fragments, transferrin, HS-glycoprotein, coagulation factors, serum proteins, ⁇ -glycoprotein, G-CSF, GM-CSF, M-CSF, EPO and the like.
- therapeutic moiety means any agent useful for therapy including, but not limited to, antibiotics, anti-inflammatory agents, anti-tumor drugs, cytotoxins, and radioactive agents.
- therapeutic moiety includes prodrugs of bioactive agents, constructs in which more than one therapeutic moiety is bound to a carrier, e.g, multivalent agents.
- Therapeutic moiety also includes proteins and constructs that include proteins.
- Exemplary proteins include, but are not limited to, Erythropoietin (EPO), Granulocyte Colony Stimulating Factor (GCSF), Granulocyte Macrophage Colony Stimulating Factor (GMCSF), Interferon (e.g., Interferon- ⁇ , - ⁇ , - ⁇ ), Interleukin (e.g., Interleukin II), serum proteins (e.g., Factors Nil, Vila, VIII, IX, and X), Human Chorionic Gonadotropin (HCG), Follicle Stimulating Hormone (FSH) and Lutenizing Hormone (LH) and antibody fusion proteins (e.g. Tumor Necrosis Factor Receptor ((TNFR)/Fc domain fusion protein)).
- EPO Erythropoietin
- GCSF Granulocyte Colony Stimulating Factor
- GMCSF Granulocyte Macrophage Colony Stimulating Factor
- Interferon
- anti-tumor drug means any agent useful to combat cancer including, but not limited to, cytotoxins and agents such as antimetabolites, alkylating agents, anthracyclines, antibiotics, antimitotic agents, procarbazine, hydroxyurea, asparaginase, corticosteroids, interferons and radioactive agents. Also encompassed within the scope of the term “anti-tumor drug,” are conjugates of peptides with anti-rumor activity, e.g. TNF- ⁇ .
- Conjugates include, but are not limited to those formed between a therapeutic protein and a gtyeoproteitf of h l e ' hveffl , ⁇ 3iri ! ; ' "-A' l rdpresentative conjugate is that formed between PSGL-1 and TNF- ⁇ .
- a cytotoxin or cytotoxic agent means any agent that is detrimental to cells. Examples include taxol, cytochalasin B, gramicidin D, ethidium bromide, emetine, mitomycin, etoposide, tenoposide, vincristine, vinblastine, colchicin, doxorubicin, daunorubicin, dihydroxy anthracinedione, mitoxantrone, mithramycin, actinomycin D, 1- dehydrotestosterone, glucocorticoids, procaine, tetracaine, lidocaine, propranolol, and puromycin and analogs or homologs thereof.
- Other toxins include, for example, ricin, CC- 1065 and analogues, the duocarmycins. Still other toxins include diptheria toxin, and snake venom (e.g. , cobra venom).
- a radioactive agent includes any radioisotope that is effective in diagnosing or destroying a tumor. Examples include, but are not limited to, indium- 111, cobalt-60. Additionally, naturally occurring radioactive elements such as uranium, radium, and thorium, which typically represent mixtures of radioisotopes, are suitable examples of a radioactive agent. The metal ions are typically chelated with an organic chelating moiety.
- ⁇ utically acceptable carrier includes any material, which when combined with the conjugate retains the conjugates' activity and is non-reactive with the subject's immune systems.
- Examples include, but are not limited to, any of the standard pharmaceutical carriers such as a phosphate buffered saline solution, water, emulsions such as oil/water emulsion, and various types of wetting agents.
- Other carriers may also include sterile solutions, tablets including coated tablets and capsules.
- Such carriers contain excipients such as starch, milk, sugar, certain types of clay, gelatin, stearic acid or salts thereof, magnesium or calcium stearate, talc, vegetable fats or oils, gums, glycols, or other known excipients.
- Such carriers may also include flavor and color additives or other ingredients. Compositions comprising such carriers are formulated by well known conventional methods.
- administering means oral administration, inhalation, administration as a suppository, topical contact, intravenous, intraperitoneal, intramuscular, intralesional, intranasal or subcutaneous administration, or the implantation of a slow-release device e.g. , a mini-osmotic pump, to the subject.
- Adminsitration is by any route including parenteral, and transmucosal (e.g., oral, nasal, vaginal, rectal, or transdermal).
- Parenteral administration includes, e.g., intravenous, intramuscular, intra-arteriole, intradermal, subcutaneous, intraperitoneal, intraventricular, and intracranial.
- injection is to treat a tumor, e.g., induce apoptosis
- administration may be directly to the tumor and/or into tissues surrounding the tumor.
- Other modes of delivery include, but are not limited to, the use of liposomal formulations, intravenous infusion, transdermal patches, etc.
- isolated refers to a material that is substantially or essentially free from components, which are used to produce the material.
- isolated refers to material that is substantially or essentially free from components, which normally accompany the material in the mixture used to prepare the peptide conjugate.
- isolated and pure are used interchangeably.
- isolated peptide conjugates of the invention have a level of purity preferably expressed as a range. The lower end of the range of purity for the peptide conjugates is about 60%, about 70%> or about 80% and the upper end of the range of purity is about 70%, about 80%, about 90%> or more than about 90%.
- the peptide conjugates are more than about 90% pure, their purities are also preferably expressed as a range.
- the lower end of the range of purity is about 90%, about 92%), about 94%, about 96% or about 98%.
- the upper end of the range of purity is about 92%, about 94%, about 96%, about 98% or about 100% purity.
- [WW2] pMfl Waet ⁇ rmir ⁇ e'd-b i'My art-recognized method of analysis (e.g., band intensity on a silver stained gel, polyacrylamide gel electrophoresis, HPLC, or a similar means).
- each member of the population describes a characteristic of a population of peptide conjugates of the invention in which a selected percentage of the modified sugars added to a peptide are added to multiple, identical acceptor sites on the peptide.
- "Essentially each member of the population” speaks to the "homogeneity" of the sites on the peptide conjugated to a modified sugar and refers to conjugates of the invention, which are at least about 80%, preferably at least about 90% and more preferably at least about 95% homogenous.
- homogeneity refers to the structural consistency across a population of acceptor moieties to which the modified sugars are conjugated.
- the peptide conjugate in which each modified sugar moiety is conjugated to an acceptor site having the same structure as the acceptor site to which every other modified sugar is conjugated, the peptide conjugate is said to be about 100% homogeneous.
- Homogeneity is typically expressed as a range. The lower end of the range of homogeneity for the peptide conjugates is about 60%, about 70%> or about 80% and the upper end of the range of purity is about 70%, about 80%), about 90% or more than about 90%.
- the peptide conjugates are more than or equal to about 90% homogeneous, their homogeneity is also preferably expressed as a range.
- the lower end of the range of homogeneity is about 90%>, about 92%, about 94%, about 96%> or about 98%>.
- the upper end of the range of purity is about 92%, about 94%, about 96%, about 98% or about 100% homogeneity.
- the purity of the peptide conjugates is typically determined by one or more methods known to those of skill in the art, e.g., liquid chromatography-mass spectrometry (LC-MS), matrix assisted laser desorption mass time of flight spectrometry (MALDITOF), capillary electrophoresis, and the like.
- substantially uniform glycoform or a “substantially uniform glycosylation pattern,” when referring to a glycopeptide species, refers to the percentage of acceptor moieties that are glycosylated by the glycosyltransferase of interest (e.g., fucosyltransferase). For example, in the case of a ⁇ 1,2 fucosyltransferase, a substantially uniform fucosylation pattern exists if substantially all (as defined below) of the Gal ⁇ l,4-GlcNAc-R and sialylated analogues thereof are fucosylated in a peptide conjugate of the invention.
- the starting material may contain glycosylated a'ccfeptbf moietie ' (e.g. ,”f ucosylated ' Gal ⁇ 1 ,4-GlcNAc-R moieties).
- the calculated percent glycosylation will include acceptor moieties that are glycosylated by the methods of the invention, as well as those acceptor moieties already glycosylated in the starting material.
- substantially in the above definitions of "substantially uniform” generally means at least about 40%), at least about 70%), at least about 80%), or more preferably at least about 90%>, and still more preferably at least about 95% of the acceptor moieties for a particular glycosyltransferase are glycosylated.
- PEG poly(ethyleneglycol); m-PEG, methoxy- ⁇ oly(ethylene glycol); PPG, poly(propyleneglycol); m-PPG, methoxy-poly(propylene glycol); Fuc, fucosyl; Gal, galactosyl; GalNAc, N-acetylgalactosaminyl; Glc, glucosyl; GlcNAc, N-acetylglucosaminyl; Man, mannosyl; ManAc, mannosaminyl acetate; Sia, sialic acid; and NeuAc, N- acetylneuraminy 1.
- the present invention provides genetically engineered mutants of human growth hormone that contain N-linked or O-linked glycosylation sites not present in naturally occurring human growth hormone. While these hGH mutants substantially retain the biological activity of the wild-type hormone, the newly introduced glycosylation sites allow the recombinantly produced hGH mutants to be glycosylated in a large variety of patterns. Moreover, the non-natural glycosylation sites provide loci for conjugating modifying groups to the peptide, e.g., by glycoconjugation.
- An exemplary modifying group is a water-soluble polymer, such as poly(ethylene glycol), e.g., methoxy-poly(ethylene glycol). Modification of the hGH mutants can improve the stability and retention time of the recombinant hGH in a patient's circulation, reduce their antigenicity, and enhance their ability to target a specific tissue in need of treatment.
- poly(ethylene glycol) e.g., methoxy-poly(ethylene glycol).
- the present invention provides mutants of hGH that include one or more O- or N- linked glycosylation sites that are not found in the wild type peptide.
- the mutants are su ' b'strates l r , 'etizy ' at ⁇ e' li g , l , elosy ! lMon at one or more sites that would not normally be glycosylated, or would be poorly glycosylated, in the wild type peptide.
- the mutants allow the position of a glycosyl residue or a glycosyl linking group to be engineered to obtain a peptide having selected desirable properties.
- the present invention provides an isolated nucleic acid comprising a polynucleotide sequence encoding a mutant human growth hormone.
- the mutant human growth hormone comprises an N-linked or O-linked glycosylation site that does not exist in the corresponding wild-type human growth hormone.
- the corresponding wild-type human growth hormone has the amino acid sequence of SEQ ID NO:l or SEQ ID NO:2.
- the mutant human growth hormone comprises the amino acid sequence of SEQ ID NO:3, 4, 5, 6, 7, 8, or 9.
- the present invention provides an expression cassette or a cell that comprises a nucleic acid, e.g., an isolated nucleic acid, including a polynucleotide sequence encoding a mutant human growth hormone.
- the mutant human growth hormone includes an N-linked or O-linked glycosylation site that does not exist in the corresponding wild-type human growth hormone.
- the present invention provides a mutant human growth hormone, that includes an N-linked or O-linked glycosylation site that does not exist in the corresponding wild-type human growth hormone.
- the corresponding wild-type human growth hormone has the amino acid sequence of SEQ ID NO: 1 or SEQ ID NO:2.
- the mutant human growth hormone comprises the amino acid sequence of SEQ ID NO:3, 4, 5, 6, 7, 8, or 9.
- the present invention provides a method for making a mutant human growth hormone that includes an N-linked or O-linked glycosylation site that does not exist in the corresponding wild-type human growth hormone.
- This method comprises the steps of recombinantly producing the mutant human growth hormone, and glycosylating the mutant human growth hormone at the new glycosylation site.
- the cUrfesp ' ta ⁇ dMg''W ⁇ 'i type l! h ⁇ a ⁇ :: gf ⁇ ' wth hormone has the amino acid sequence of SEQ ID NO: 1 or SEQ ID NO:2.
- the mutant human growth hormone comprises the amino acid sequence of SEQ ID NO:3, 4, 5, 6, 7, 8, or 9.
- This invention relies on routine techniques in the field of recombinant genetics. Basic texts disclosing the general methods of use in this invention include Sambrook and Russell, Molecular Cloning, A Laboratory Manual (3rd ed. 2001); Kriegler, Crene Transfer and Expression: A Laboratory Manual (1990); and Ausubel et al, eds., Current Protocols in Molecular Biology ( 1994).
- nucleic acids sizes are given in either kilobases (kb) or base pairs (bp). These are estimates derived from agarose or acrylamide gel electrophoresis, from sequenced nucleic acids, or from published DNA sequences.
- kb kilobases
- bp base pairs
- proteins sizes are given in kilodaltons (kDa) or amino acid residue numbers. Proteins sizes are estimated from gel electrophoresis, from sequenced proteins, from derived amino acid sequences, or from published protein sequences.
- Oligonucleotides that are not commercially available can be chemically synthesized, e.g., according to the solid phase phosphoramidite triester method first described by Beaucage & Caruthers, Tetrahedron Lett. 22: 1859-1862 (1981), using an automated synthesizer, as described in Van Devanter et. al, Nucleic Acids Res. 12: 6159-6168 (1984). Purification of oligonucleotides is performed using any art-recognized strategy, e.g. , native acrylamide gel electrophoresis or anion-exchange HPLC as described in Pearson & Reanier, J. Chrom. 255: 137-149 (1983).
- a number of polynucleotide sequences encoding a wild-type human growth hormone e.g., GenBank Accession Nos. NM 000515, NM 002059, NM 022556, NM 022557, NM 022558, NM 022559, NM 022560, NM 022561, and NM 022562, have been determined and can be obtained from a commercial supplier.
- a human DNA sequence database can be searched for any gene segment that has a certain percentage of sequence homology to a known nucleotide sequence, such as one encoding a previously identified human growth hormone. Any DNA sequence so identified can be subsequently obtained by chemical synthesis and/or a polymerase chain reaction (PCR) technique such as overlap extension method. For a short sequence, completely de novo synthesis may be sufficient; whereas further isolation of full length coding sequence from a human cDNA or genomic library using a synthetic probe may be necessary to obtain a larger gene.
- PCR polymerase chain reaction
- a nucleic acid sequence encoding a human growth hormone can be isolated from a human cDNA or genomic DNA library using standard cloning techniques such as polymerase chain reaction (PCR), where homology-based primers can often be derived from a known nucleic acid sequence encoding a human growth hormone.
- PCR polymerase chain reaction
- cDNA libraries suitable for obtaining a coding sequence for a wild-type human growth hormone may be commercially available or can be constructed.
- the general methods of isolating mRNA, making cDNA by reverse transcription, ligating cDNA into a recombinant vector, transfecting into a recombinant host for propagation, screening, and cloning are well known (see, e.g., Gubler and Hoffman, Gene, 25: 263-269 (1983); Ausubel et al, supra).
- the segment Upon obtaining an amplified segment of nucleotide sequence by PCR, the segment can be further used as a probe to isolate the full length polynucleotide sequence encoding the wild-type human growth hormone from the cDNA library.
- a general description of appropriate procedures can be found in Sambrook and Russell, supra.
- a similar procedure can be followed to obtain a full length sequence encoding a wild-type human growth hormone, e.g., any one of the GenBank Accession Nos. mentioned above, from a human genomic library.
- Human genomic libraries are commercially available or can be constructed according to various art-recognized methods. In general, to construct a genomic library, the DNA is first extracted from an tissue where a human growth hormone is likely found.
- the DNA is then either mechanically sheared or enzymatically digested to yield fragments of about 12-20 kb in length.
- the fragments are subsequently separated by gradient centrifugation from polynucleotide fragments of undesired sizes and are inserted in bacteriophage ⁇ vectors.
- These vectors and phages are packaged in vitro. Recombinant phages are atialyzed' l by"plaqUe hybridization as described in Benton and Davis, Science, 196: 180-182 (1977). Colony hybridization is carried out as described by Grunstein et al, Proc. Natl. Acad. Sci. USA, 72: 3961-3965 (1975).
- degenerate oligonucleotides can be designed as primer sets and PCR can be performed under suitable conditions (see, e.g., White et al, PCR Protocols: Current Methods and Applications, 1993; Griffin and Griffin, PCR Technology, CRC Press Inc. 1994) to amplify a segment of nucleotide sequence from a cDNA or genomic library. Using the amplified segment as a probe, the full length nucleic acid encoding a wild- type human growth hormone is obtained.
- the coding sequence can be subcloned into a vector, for instance, an expression vector, so that a recombinant wild-type human growth hormone can be produced from the resulting construct. Further modifications to the wild-type human growth hormone coding sequence, e.g., nucleotide substitutions, may be subsequently made to alter the characteristics of the molecule.
- amino acid sequence of a wild-type human growth hormone e.g., SEQ ID NO:l or SEQ ID NO:2
- this amino acid sequence may be modified to alter the protein's glycosylation pattern, by introducing additional glycosylation site(s) at various locations in the amino acid sequence.
- N-linked glycosylation occurs on the asparagine of the consensus sequence Asn-X aa -Ser/Thr, in which X aa is any amino acid except proline (Kornfeld et al., Ann Rev Biochem 54:631-664 (1985); Kukuruzinska et al, Proc. Natl. Acad. Sci. USA 84:2145-2149 (1987); Herscovics et al, FASEB J 7:540-550 (1993); and Orlean, Saccharomyces Vol. 3 (1996)).
- O-linked glycosylation takes place at serine or threonine residues (Tanner et al, Biochim. Biophys. Ada. 906:81-91 (1987); and Hounsell et al, Glycoconj. J. 13:19-26 (1996)).
- Other glycosylation patterns are formed by linking glycosylphosphatidylinositol to the carboxyl-terminal carboxyl group of the protein (Takeda et al, Trends Biochem. Sci.
- kits for mutagenesis, library construction, and other diversity-generating methods are commercially available.
- Mutational methods of generating diversity include, for example, site-directed mutagenesis (Botstein and Shortle, Science, 229: 1193-1201 (1985)), mutagenesis using uracil-containing templates (Kunkel, Proc. Natl. Acad. Sci. USA, 82: 488-492 (1985)), oligonucleotide-directed mutagenesis (Zoller and Smith, Nucl. Acids Res., 10: 6487-6500 (1982)), phosphorothioate-modified DNA mutagenesis (Taylor et al, Nucl.
- the polynucleotide sequence encoding a mutant human growth hormone can be further altered to coincide with the preferred codon usage of a particular host.
- the preferred codon usage of one strain of bacterial cells can be used to derive a polynucleotide that encodes a mutant human growth hormone of the invention and includes the codons favored by this strain.
- the frequency of preferred codon usage exhibited by a host cell can be calculated by averaging frequency of preferred codon usage in a large number of genes expressed by the host cell (e.g., calculation service is available from web site of the Kazusa DNA Research Institute, Japan). This analysis is preferably limited to genes that are highly expressed by the host cell.
- U.S. Patent No. 5,824,864 for example, provides the frequency of codon usage by highly expressed genes exhibited by dicotyledonous plants and monocotyledonous plants.
- mutant human growth hormone coding sequences are verified by sequencing and are then subcloned into an appropriate expression vector for recombinant production in the same manner as the wild-type human growth hormones.
- mutant human growth hormone of the present invention can be produced using routine techniques in the field of recombinant genetics, relying on the polynucleotide sequences encoding the polypeptide disclosed herein.
- a nucleic acid encoding a mutant human growth hormone of the present invention one typically subclones a polynucleotide encoding the mutant human growth hormone into an expression vector that contains a strong promoter to direct transcription, a transcription translation terminator and a ribosome binding site for translational initiation.
- Suitable bacterial promoters are well known in the art and described, e.g., in Sambrook and Russell, supra, and Ausubel et al, supra.
- Bacterial expression systems for expressing the wild-type or mutant human growth hormone are available in, e.g., E. coli, Bacillus sp., Salmonella, and Caulobader. Kits for such expression systems are commercially available.
- Eukaryotic expression systems for mammalian cells, yeast, and insect cells are well known in the art and are also commercially available.
- one eukaryotic i 'ex fe'ssion vector is an adenoviral vector, an adeno-associated vector, or a retroviral vector.
- the promoter used to direct expression of a heterologous nucleic acid depends on the particular application.
- the promoter is optionally positioned about the same distance from the heterologous transcription start site as it is from the transcription start site in its natural setting. As is known in the art, however, some variation in this distance can be accommodated without loss of promoter function.
- the expression vector typically includes a transcription unit or expression cassette that contains all the additional elements required for the expression of the mutant human growth hormone in host cells.
- a typical expression cassette thus contains a promoter operably linked to the nucleic acid sequence encoding the mutant human growth hormone and signals required for efficient polyadenylation of the transcript, ribosome binding sites, and translation termination.
- the nucleic acid sequence encoding the human growth hormone is typically linked to a cleavable signal peptide sequence to promote secretion of the human growth hormone by the transformed cell.
- signal peptides include, among others, the signal peptides from tissue plasminogen activator, insulin, and neuron growth factor, and juvenile hormone esterase of Heliothis virescens.
- Additional elements of the cassette may include enhancers and, if genomic DNA is used as the structural gene, introns with functional splice donor and acceptor sites.
- the expression cassette should also contain a transcription termination region downstream of the structural gene to provide for efficient termination. The termination region may be obtained from the same gene as the promoter sequence or may be obtained from different genes.
- the particular expression vector used to transport the genetic information into the cell is not particularly critical. Any of the conventional vectors used for expression in eukaryotic or prokaryotic cells may be used. Standard bacterial expression vectors include plasmids such as pBR322 based plasmids, pSKF, pET23D, and fusion expression systems such as GST and LacZ. Epitope tags can also be added to recombinant proteins to provide convenient methods of isolation, e.g., c-myc.
- Expression vectors containing regulatory elements from eukaryotic viruses are typically used in eukaryotic expression vectors, e.g., SV40 vectors, papilloma virus vectors, and vectors derived from Epstein-Barr virus.
- exemplary eukaryotic vectors include jpMSO, ⁇ AVtKWA" ,- ' pMTO 0/A7 ' pMAMneo-5, baculovirus pDSVE, and any other vector allowing expression of proteins under the direction of the SV40 early promoter, SV40 later promoter, • metallothionein promoter, murine mammary tumor virus promoter, Rous sarcoma virus promoter, polyhedrin promoter, or other promoters shown effective for expression in eukaryotic cells.
- Some expression systems have markers that provide gene amplification such as thymidine kinase, hygromycin B phosphotransferase, and dihydrofolate reductase.
- markers that provide gene amplification such as thymidine kinase, hygromycin B phosphotransferase, and dihydrofolate reductase.
- high yield expression systems not involving gene amplification are also suitable, such as a baculovirus vector in insect cells, with a polynucleotide sequence encoding the mutant human growth hormone under the direction of the polyhedrin promoter or other strong baculovirus promoters.
- the elements that are typically included in expression vectors also include a replicon that functions in E. coli, a gene encoding antibiotic resistance to permit selection of bacteria that harbor recombinant plasmids, and unique restriction sites in nonessential regions of the plasmid to allow insertion of eukaryotic sequences.
- the particular antibiotic resistance gene chosen is not critical, any of the many resistance genes known in the art are suitable.
- the prokaryotic sequences are optionally chosen such that they do not interfere with the replication of the DNA in eukaryotic cells, if necessary. Similar to antibiotic resistance selection markers, metabolic selection markers based on known metabolic pathways may also be used as a means for selecting transformed host cells.
- the expression vector further comprises a sequence encoding a secretion signal, such as the E. coli OppA (Periplasmic Oligopeptide Binding Protein) secretion signal or a modified version thereof, which is directly connected to 5' of the coding sequence of the protein to be expressed.
- a secretion signal such as the E. coli OppA (Periplasmic Oligopeptide Binding Protein) secretion signal or a modified version thereof, which is directly connected to 5' of the coding sequence of the protein to be expressed.
- This signal sequence directs the recombinant protein produced in cytoplasm through the cell membrane into the periplasmic space.
- the expression vector may further comprise a coding sequence for signal peptidase 1, which is capable of enzymatically cleaving the signal sequence when the recombinant protein is entering the periplasmic space. More detailed description for periplasmic production of a recombinant protein can be found in, e.g. , Gray et al. , Gene 39: 247-254 (1985), U.S. Patent Nos. 6,160,089 and 6,436,674.
- Standard transfection methods are used to produce bacterial, mammalian, yeast, insect, or plant cell lines that express large quantities of the mutant human growth hormone, which are then purified using standard techniques (see, e.g., Colley et al, J. Biol. Chem. 264: 17619-17622 (1989); Guide to Protein Purification, in Methods in Enzymology, vol. 182 (Deutscher, ed., 1990)). Transformation of eukaiyotic and prokaryotic cells are performed according to standard techniques (see, e.g., Morrison, J, Bad.
- Any of the well known procedures for introducing foreign nucleotide sequences into host cells may be used. These include the use of calcium phosphate transfection, polybrene, protoplast fusion, electroporation, liposomes, microinjection, plasma vectors, viral vectors and any of the other well known methods for introducing cloned genomic DNA, cDNA, synthetic DNA, or other foreign genetic material into a host cell (see, e.g., Sambrook and Russell, supra). It is only necessary that the particular genetic engineering procedure used be capable of successfully introducing at least one gene into the host cell capable of expressing the mutant human growth hormone.
- the transfected cells are cultured under conditions favoring expression of the mutant human growth hormone.
- the cells are then screened for the expression of the recombinant polypeptide, which is subsequently recovered from the culture using standard techniques (see, e.g., Scopes, Protein Purification: Principles and Practice (1982); U.S. Patent No. 4,673,641; Ausubel et al, supra; and Sambrook and Russell, supra).
- standard techniques see, e.g., Scopes, Protein Purification: Principles and Practice (1982); U.S. Patent No. 4,673,641; Ausubel et al, supra; and Sambrook and Russell, supra.
- gene expression can be detected at the polypeptide level.
- Various immunological assays are routinely used by those skilled in the art to measure the level of a gene product, particularly using polyclonal or monoclonal antibodies that react specifically with a mutant human growth hormone of the present invention, such as a polypeptide having the amino acid sequence of SEQ ID NO:3, 4, or 5, (e.g., Harlow and Lane, Antibodies, A Laboratory Manual, Chapter 14, Cold Spring Harbor, 1988; Kohler and Milstein, Nature, 256: 495-497 (1975)).
- Such techniques require antibody preparation by selecting antibodies with high specificity against the mutant human growth hormone or an antigenic portion thereof.
- the mutant human growth hormones of the present invention are produced recombinantly by transformed bacteria in large amounts, typically after promoter induction, although expression can be constitutive, the proteins may form insoluble aggregates.
- purification of protein inclusion bodies typically involves the extraction, separation and/or purification of inclusion bodies by disruption of bacterial cells, e.g., by incubation in a buffer of about 100-150 ⁇ g/ml lysozyme and"0.'l% N ⁇ ide't 40,'"a' ribh-i ⁇ hie detergent.
- the cell suspension can be ground using a Polytron grinder (Brinkman Instruments, Westbury, NY). Alternatively, the cells can be sonicated on ice. Alternate methods of lysing bacteria are described in Ausubel et al. and Sambrook and Russell, both supra, and will be apparent to those of skill in the art. [0123]
- the cell suspension is generally centrifuged and the pellet containing the inclusion bodies resuspended in buffer which does not dissolve but washes the inclusion bodies, e.g., 20 mM Tris-HCl (pH 7.2), 1 mM EDTA, 150 mM NaCl and 2% Triton-X 100, a non-ionic detergent.
- pellet of inclusion bodies may be resuspended in an appropriate buffer (e.g., 20 mM sodium phosphate, pH 6.8, 150 mM NaCl).
- an appropriate buffer e.g., 20 mM sodium phosphate, pH 6.8, 150 mM NaCl.
- Other appropriate buffers will be apparent to those of skill in the art.
- the inclusion bodies are solubilized by the addition of a solvent that is both a strong hydrogen acceptor and a strong hydrogen donor (or a combination of solvents each having one of these properties).
- a solvent that is both a strong hydrogen acceptor and a strong hydrogen donor or a combination of solvents each having one of these properties.
- the proteins that formed the inclusion bodies may then be renatured by dilution or dialysis with a compatible buffer.
- Suitable solvents include, but are not limited to, urea (from about 4 M to about 8 M), formamide (at least about 80%>, volume/volume basis), and guanidine hydrochloride (from about 4 M to about 8 M).
- Some solvents that are capable of solubilizing aggregate-forming proteins may be inappropriate for use in this procedure due to the possibility of irreversible denaturation of the proteins, accompanied by a lack of immunogenicity and/or activity.
- SDS sodium dodecyl sulfate
- 70% formic acid may be inappropriate for use in this procedure due to the possibility of irreversible denaturation of the proteins, accompanied by a lack of immunogenicity and/or activity.
- guanidine hydrochloride and similar agents are denaturants, this denaturation is not irreversible and renaturation may occur upon removal (by dialysis, for example) or dilution of the denaturant, allowing re-formation of the immunologically and/or biologically active protein of interest.
- the protein can be separated from other bacterial proteins by standard separation techniques.
- purifying recombinant human growth hormone from bacterial inclusion body see, e.g., Patra et al, Protein Expression and Purification 18: 182-190 (2000).
- recombinant polypeptides e.g., a mutant human growth hormone
- the periplasmic fraction of the bacteria can be isolated by cold osmotic shock in addition to other methods known to those of skill in the art (see e.g., Ausubel et al, supra).
- the eW ⁇ al ' ceils-'are' c'eritrif ⁇ f e :, tb li f ⁇ rm a pellet. The pellet is resuspended in a buffer containing 20%) sucrose.
- the bacteria are centrifuged and the pellet is resuspended in ice-cold 5 mM MgSO 4 and kept in an ice bath for approximately 10 minutes.
- the cell suspension is centrifuged and the supernatant decanted and saved.
- the recombinant proteins present in the supernatant can be separated from the host proteins by standard separation techniques well known to those of skill in the art.
- a recombinant polypeptide e.g., the mutant human growth hormone ofthe present invention
- its purification can follow the standard protein purification procedure described below.
- an initial salt fractionation can separate many ofthe unwanted host cell proteins (or proteins derived from the cell culture media) from the recombinant protein of interest, e.g., a mutant human growth hormone ofthe present invention.
- the preferred salt is ammonium sulfate. Ammonium sulfate precipitates proteins by effectively reducing the amount of water in the protein mixture. Proteins then precipitate on the basis of their solubility. The more hydrophobic a protein is, the more likely it is to precipitate at lower ammonium sulfate concentrations.
- a typical protocol is to add saturated ammonium sulfate to a protein solution so that the resultant ammonium sulfate concentration is between 20-30%). This will precipitate the most hydrophobic proteins. The precipitate is discarded (unless the protein of interest is hydrophobic) and ammonium sulfate is added to the supernatant to a concentration known to precipitate the protein of interest. The precipitate is then solubilized in buffer and the excess salt removed if necessary, through either dialysis or diafiltration. Other methods that rely on solubility of proteins, such as cold ethanol precipitation, are well known to those of skill in the art and can be used to fractionate complex protein mixtures.
- a protein of greater and lesser size can be isolated using ultrafiltration through membranes of different pore sizes (for example, Amicon or Millipore membranes).
- the protein mixture is ultrafiltered through a membrane with a pore size that has a lower molecular weight cut-off than the molecular weight of a protein of interest, e.g., a mutant human growth hormone.
- the recombinant protein will pass through the membrane into the filtrate.
- the filtrate can then be chromatographed as described below.
- the proteins of interest can also be separated from other proteins on the basis of their size, net surface charge, hydrophobicity, or affinity for ligands.
- antibodies raised against human growth hormone can be conjugated to column matrices and the human growth hormone immunopurified. All of these methods are well known in the art.
- chromatographic techniques can be performed at any scale and using equipment from many different manufacturers (e.g., Pharmacia Biotech).
- immunological assays may be useful to detect in a sample the expression ofthe polypeptide. Immunological assays are also useful for quantifying the expression level ofthe recombinant hormone. Antibodies against a mutant human growth hormone are necessary for carrying out these immunological assays.
- Such techniques include antibody preparation by selection of antibodies from libraries of recombinant antibodies in phage or similar vectors (see, Huse et al., Science 246: 1275-1281, 1989; and Ward et al, Nature 341: 544-546, 1989).
- the polypeptide of interest e.g., a mutant human growth hormone ofthe present invention
- an aSitrgemc 1 ffagr n't thtrebf 6a'n b ⁇ sed to immunize suitable animals, e.g., mice, rabbits, or primates.
- a standard adjuvant such as Freund's adjuvant, can be used in accordance with a standard immunization protocol.
- a synthetic antigenic peptide derived from that particular polypeptide can be conjugated to a carrier protein and subsequently used as an immunogen.
- the animal's immune response to the immunogen preparation is monitored by taking test bleeds and determining the titer of reactivity to the antigen of interest.
- blood is collected from the animal and antisera are prepared. Further fractionation ofthe antisera to enrich antibodies specifically reactive to the antigen and purification ofthe antibodies can be performed subsequently, see, Harlow and Lane, supra, and the general descriptions of protein purification provided above.
- Monoclonal antibodies are obtained using various techniques familiar to those of skill in the art.
- spleen cells from an animal immunized with a desired antigen are immortalized, commonly by fusion with a myeloma cell (see, Kohler and Milstein, Eur. J. Immunol. 6:511-519, 1976).
- Alternative methods of immortalization include, e.g., transformation with Epstein Barr Virus, oncogenes, or retroviruses, or other methods well known in the art.
- Colonies arising from single immortalized cells are screened for production of antibodies ofthe desired specificity and affinity for the antigen, and the yield ofthe monoclonal antibodies produced by such cells may be enhanced by various techniques, including injection into the peritoneal cavity of a vertebrate host.
- monoclonal antibodies may also be recombinantly produced upon identification of nucleic acid sequences encoding an antibody with desired specificity or a binding fragment of such antibody by screening a human B cell cDNA library according to the general protocol outlined by Huse et al, supra.
- the general principles and methods of recombinant polypeptide production discussed above are applicable for antibody production by recombinant methods.
- antibodies capable of specifically recognizing a mutant human growth hormone ofthe present invention can be tested for their cross-reactivity against the wild- type human growth hormone and thus distinguished from the antibodies against the wild-type protein.
- antisera obtained from an animal immunized with a mutant human growth hormone can be run through a column on which a wild-type human growth ⁇ rmO ⁇ e'is'i' ⁇ tirh'bbilized " he-pbttion ofthe antisera that passes through the column recognizes only the mutant human growth hormone and not the wild-type human growth hormone.
- monoclonal antibodies against a mutant human growth hormone can also be screened for their exclusivity in recognizing only the mutant but not the wild-type human growth hormone.
- Polyclonal or monoclonal antibodies that specifically recognize only the mutant human growth hormone ofthe present invention but not the wild-type human growth hormone are useful for isolating the mutant protein from the wild-type protein, for example, by incubating a sample with a mutant human growth hormone-specific polyclonal or monoclonal antibody immobilized on a solid support.
- the amount ofthe polypeptide in a sample can be measured by a variety of immunoassay methods providing qualitative and quantitative results to a skilled artisan.
- immunoassay methods providing qualitative and quantitative results to a skilled artisan.
- Immunoassays often utilize a labeling agent to specifically bind to and label the binding complex formed by the antibody and the target protein.
- the labeling agent may itself be one ofthe moieties comprising the antibody/target protein complex, or may be a third moiety, such as another antibody, that specifically binds to the antibody/target protein complex.
- a label may be detectable by spectroscopic, photochemical, biochemical, immunochemical, electrical, optical or chemical means.
- Examples include, but are not limited to, magnetic beads (e.g., DynabeadsTM), fluorescent dyes (e.g., fluorescein isothiocyanate, Texas red, rhodamine, and the like), radiolabels (e.g., 3 H, I25 1, 35 S, 14 C, or
- enzymes e.g., horse radish peroxidase, alkaline phosphatase, and others commonly used in an ELISA
- colorimetric labels such as colloidal gold or colored glass or plastic (e.g., polystyrene, polypropylene, latex, etc.) beads.
- the labeling agent is a second antibody bearing a detectable label.
- the second antibody may lack a label, but it may, in turn, be bound by a labeled third antibody specific to antibodies ofthe species from which the second antibody is def ⁇ vfed.” ' I'he-S eb ⁇ 'i ritibO ' y ii ⁇ drii'rJi' modified with a detectable moiety, such as biotin, to which a third labeled molecule can specifically bind, such as enzyme-labeled streptavidin.
- proteins capable of specifically binding immunoglobulin constant regions can also be used as the label agents. These proteins are normal constituents ofthe cell walls of streptococcal bacteria. They exhibit a strong non- immunogenic reactivity with immunoglobulin constant regions from a variety of species (see, generally, Kronval, et al. J. Immunol, 111: 1401-1406 (1973); and Akerstrom, et al., J. Immunol, 135: 2589-2542 (1985)).
- Immunoassays for detecting a target protein of interest may be either competitive or noncompetitive.
- Noncompetitive immunoassays are assays in which the amount of captured target protein is directly measured.
- the antibody specific for the target protein can be bound directly to a solid substrate where the antibody is immobilized. It then captures the target protein in test samples.
- the antibody/target protein complex thus immobilized is then bound by a labeling agent, such as a second or third antibody bearing a label, as described above.
- the amount of target protein in a sample is measured indirectly by measuring the amount of an added (exogenous) target protein displaced (or competed away) from an antibody specific for the target protein by the target protein present in the sample.
- the antibody is immobilized and the exogenous target protein is labeled. Since the amount ofthe exogenous target protein bound to the antibody is inversely proportional to the concentration ofthe target protein present in the sample, the target protein level in the sample can thus be determined based on the amount of exogenous target protein bound to the antibody and thus immobilized.
- western blot analysis is used to detect and quantify the presence of a mutant human growth hormone in the samples.
- the technique generally comprises separating sample proteins by gel electrophoresis on the basis of molecular weight, transferring the separated proteins to a suitable solid support (such as a nitrocellulose filter, a nylon filter, or a derivatized nylon filter) and incubating the samples with the antibodies that specifically bind the target protein.
- antibodies may be directly labeled or alternatively niia »b is ⁇ t ⁇ e ⁇ !iMtl .detfe *I"USirif 'labeled antibodies (e.g., labeled sheep anti-mouse antibodies) that specifically bind to the antibodies against a mutant human growth hormone.
- LOA liposome immunoassays
- the invention provides methods for preparing conjugates of glycosylated and unglycosylated mutant human growth hormones, which have new glycosylation sites that do not exist in the corresponding wild-type hGH. Such conjugation may take place directly on the appropriate sugar units of a glycosylated mutant hGH, or following the removal (i.e., "trimming back") of any undesired sugar units.
- the conjugates are formed between peptides and diverse species such as water-soluble polymers, therapeutic moieties, diagnostic moieties, targeting moieties and the like.
- conjugates that include two or more peptides linked together through a linker arm i.e., multifunctional conjugates.
- the multi-functional conjugates ofthe invention can include two or more copies ofthe same peptide or a collection of diverse peptides with different structures, and/or properties.
- the conjugates of the invention are formed by the enzymatic attachment of a modified sugar to the glycosylated or unglycosylated peptide.
- the modified sugar when interposed between the peptide and the modifying group on the sugar becomes what is referred to herein as "an intact glycosyl linking group.”
- an intact glycosyl linking group Using the extraordinarivity of eruzyrneS Sufe ⁇ a's'f- iybbs iltfariSfeia ⁇ e-s, the present method provides peptides that bear a desired group at one or more specific locations.
- a modified sugar is attached directly to a selected locus on the peptide chain or, alternatively, the modified sugar is appended onto a carbohydrate moiety of a glycopeptide.
- Peptides in which modified sugars are bound to both a glycopeptide carbohydrate and directly to an amino acid residue ofthe peptide backbone are also within the scope ofthe present invention.
- the methods ofthe invention make it possible to assemble peptides and glycopeptides that have a substantially homogeneous derivatization pattern; the enzymes used in the invention are generally selective for a particular amino acid residue or combination of amino acid residues ofthe peptide.
- the methods are also practical for large-scale production of modified peptides and glycopeptides.
- the methods ofthe invention provide a practical means for large- scale preparation of glycopeptides having preselected uniform derivatization patterns.
- the methods are particularly well suited for modification of therapeutic peptides, including but not limited to, glycopeptides that are incompletely glycosylated during production in cell culture cells (e.g., mammalian cells, insect cells, plant cells, fungal cells, yeast cells, or prokaryotic cells) or transgenic plants or animals.
- cell culture cells e.g., mammalian cells, insect cells, plant cells, fungal cells, yeast cells, or prokaryotic cells
- transgenic plants or animals e.g., transgenic plants or animals.
- the methods ofthe invention also provide conjugates of glycosylated and unglycosylated peptides with increased therapeutic half-life due to, for example, reduced clearance rate, or reduced rate of uptake by the immune or reticuloendothelial system (RES). Moreover, the methods ofthe invention provide a means for masking antigenic determinants on peptides, thus reducing or eliminating a host immune response against the peptide. Selective attachment of targeting agents can also be used to target a peptide to a particular tissue or cell surface receptor that is specific for the particular targeting agent.
- RES reticuloendothelial system
- the present invention provides a conjugate between a selected modifying group and an hGH mutant peptide having a glycosylation site not present in the wild type peptide.
- the modifying group may be attached at the mutant glycosylation site or at a site that is present in the wild type peptide.
- the link between the peptide and the modifying includes a glycosyl linking group interposed between the peptide and the selected moiety.
- the selected moiety is essentially any species that can be attached to a saccharide unit, resulting in a ⁇ modified M r 8Jtt tti!at s%e b 6grii 'by an appropriate transferase enzyme, which appends the modified sugar onto the peptide.
- the saccharide component ofthe modified sugar when interposed between the peptide and a selected moiety, becomes a "glycosyl linking group," e.g., an "intact glycosyl linking group.”
- the glycosyl linking group is formed from any mono- or oligo-saccharide that, after modification with the modifying group, is a substrate for an enzyme that adds the modified sugar to an amino acid or glycosyl residue of a peptide.
- the glycosyl linking group can be, or can include, a saccharide moiety that is degradatively modified during the addition ofthe modifying group.
- the glycosyl linking group can be derived from a saccharide residue that is produced by oxidative degradation of an intact saccharide to the corresponding aldehyde, e.g., via the action of metaperiodate, and subsequently converted to a Schiff base with an appropriate amine, which is then reduced to the corresponding amine.
- the "agent” is a therapeutic agent, a bioactive agent, a detectable label, water-soluble moiety (e.g., PEG, m-PEG, PPG, and m-PPG) or the like.
- the "agent” can be a peptide, e.g., enzyme, antibody, antigen, etc.
- the linker can be any of a wide array of linking groups, infra.
- the linker may be a single bond or a "zero order linker.”
- the selected modifying group is a water-soluble polymer, e.g., m-PEG.
- the water-soluble polymer is covalently attached to the peptide via a glycosyl linking group.
- the glycosyl linking group is covalently attached to an amino acid residue or a glycosyl residue ofthe peptide.
- the invention also provides conjugates in which an amino acid residue and a glycosyl residue are modified with a glycosyl linking group.
- An exemplary water-soluble polymer is poly(ethylene glycol), e.g., methoxy- poly(ethylene glycol).
- the poly(ethylene glycol) used in the present invention is not restricted to any particular form or molecular weight range.
- the poly(ethylene glycol) molecular weight is preferably between 500 and 100,000.
- a molecular weight of 500-60,000 is preferably used and preferably of from 1,000-40,000. More preferably, the molecular weight is from about 5,000 to about 40,000.
- each poly(ethylene glycol) ofthe branched PEG is 5,000-20,000.
- the present invention provides conjugates that are highly homogenous in their substitution patterns. Using the methods ofthe invention, it is possible to form peptide conjugates in which essentially all ofthe modified sugar moieties across a population of conjugates ofthe invention are attached to multiple copies of a structurally identical amino acid or glycosyl residue.
- the invention provides a peptide conjugate having a population of water-soluble polymer moieties, which are covalently bound to the peptide through an intact glycosyl linking group.
- each member ofthe population is bound via the glycosyl linking group to a glycosyl residue ofthe peptide, and each glycosyl residue ofthe peptide to which the glycosyl linking group is attached has the same structure.
- a peptide conjugate having a population of water-soluble polymer moieties covalently bound thereto through a glycosyl linking group.
- a glycosyl linking group essentially every member ofthe population of water soluble polymer moieties is bound to an amino acid residue ofthe peptide via a glycosyl linking group, and each amino acid residue having a glycosyl linking group attached thereto has the same structure.
- the present invention also provides conjugates analogous to those described above in which the peptide is conjugated to a therapeutic moiety, diagnostic moiety, targeting moiety, toxin moiety or the like via an intact glycosyl linking group.
- the peptide is conjugated to a therapeutic moiety, diagnostic moiety, targeting moiety, toxin moiety or the like via an intact glycosyl linking group.
- Each ofthe above- recited moieties can be a small molecule, natural polymer (e.g., polypeptide) or synthetic polymer.
- mutant human growth hormone is conjugated to transferrin via a bifunctional linker that includes an intact glycosyl linking group at each terminus ofthe PEG moiety (Scheme 1).
- a bifunctional linker that includes an intact glycosyl linking group at each terminus ofthe PEG moiety (Scheme 1).
- one terminus ofthe PEG linker is fun'bti nalized' i wi l tl ll a ⁇ linker that is attached to transferrin and the other is fiinctionalized with an intact GalNAc linker that is attached to the mutant hGH.
- the conjugates ofthe invention can include intact glycosyl linking groups that are mono- or multi-valent (e.g., antennary structures).
- conjugates ofthe invention include both species in which a selected moiety is attached to a peptide via a monovalent glycosyl linking group.
- conjugates in which more than one selected moiety is attached to a peptide via a multivalent linking group are also included within the invention.
- the invention provides conjugates that localize selectively in a particular tissue due to the presence of a targeting agent as a component ofthe conjugate.
- the targeting agent is a protein.
- Exemplary proteins include transferrin (brain, blood pool), HS-glycoprotein (bone, brain, blood pool), antibodies (brain, tissue with antibody-specific antigen, blood pool), coagulation factors V- XII (damaged tissue, clots, cancer, blood pool), serum proteins, e.g., ⁇ -acid glycoprotein, fetuin, ⁇ -fetal protein (brain, blood pool), ⁇ 2-glycoprotein (liver, atherosclerosis plaques, brain, blood pool), G-CSF, GM-CSF, M-CSF, and EPO (immune stimulation, cancers, blood pool, red blood cell overproduction, neuroprotection), albumin (increase in half-life), and lipoprotein E.
- the present invention provides methods for preparing these and other conjugates.
- the invention provides a method of forming a covalent conjugate between a selected moiety and a peptide.
- the invention provides methods for targeting conjugates ofthe invention to a particular tissue or region ofthe body.
- the present invention provides a method for preventing, curing, or ameliorating a disease state by administering a conjugate ofthe invention to a subject at risk of developing the disease or a subject that has the disease.
- the conjugate is formed between a water-soluble polymer, a therapeutic moiety, targeting moiety or a biomolecule, and a glycosylated or non- glycosylated peptide.
- the polymer, therapeutic moiety or biomolecule is conjugated to the peptide via an intact glycosyl linking group, which is interposed between, and covalently linked to both the peptide and the modifying group (e.g., water-soluble polymer).
- the method includes contacting the peptide with a mixture containing a modified sugar and a glycosyltransferase for which the modified sugar is a substrate.
- the reaction is conducted u'hc ⁇ er covalent bond between the modified sugar and the peptide.
- the sugar moiety ofthe modified sugar is preferably selected from nucleotide sugars, activated sugars, and sugars that are neither nucleotides nor activated.
- the acceptor peptide (glycosylated or non-glycosylated) is typically synthesized de novo, or recombinantly expressed in a prokaryotic cell (e.g., bacterial cell, such as E. coli) or in a eukaryotic cell such as a mammalian, yeast, insect, fungal or plant cell.
- a prokaryotic cell e.g., bacterial cell, such as E. coli
- a eukaryotic cell such as a mammalian, yeast, insect, fungal or plant cell.
- the peptide can be either a full-length protein or a fragment.
- the peptide can be a wild type or mutated peptide.
- the peptide includes a mutation that adds one or more consensus glycosylation sites to the peptide sequence.
- the method of the invention also provides for modification of incompletely glycosylated peptides that are produced recombinantly. Many recombinantly produced glycoproteins are incompletely glycosylated, exposing carbohydrate residues that may have undesirable properties, e.g., immunogenicity, recognition by the RES.
- the peptide can be simultaneously further glycosylated and derivatized with, e.g., a water-soluble polymer, therapeutic agent, or the like.
- the sugar moiety ofthe modified sugar can be the residue that would properly be conjugated to the acceptor in a fully glycosylated peptide, or another sugar moiety with desirable properties.
- Peptides modified by the methods ofthe invention can be synthetic or wild-type peptides or they can be mutated peptides, produced by methods known in the art, such as site- directed mutagenesis. Glycosylation of peptides is typically either N-linked or O-linked. An exemplary N-linkage is the attachment ofthe modified sugar to the side chain of an asparagine residue.
- the tripeptide sequences asparagine-X-serine and asparagine-X- threonine, where X is any amino acid except proline, are the recognition sequences for enzymatic attachment of a carbohydrate moiety to the asparagine side chain.
- O-linked glycosylation refers to the attachment of one sugar (e.g., N- aceylgalactosamine, galactose, mannose, GlcNAc, glucose, fucose or xylose) to a the hydroxy side chain of a hydroxyamino acid, preferably serine or threonine, although 5- hydroxyproline or 5-hydroxylysine may also be used.
- one sugar e.g., N- aceylgalactosamine, galactose, mannose, GlcNAc, glucose, fucose or xylose
- Addition of glycosylation sites to a peptide or other structure is conveniently accomplished by altering the amino acid sequence such that it contains one or more glycosylation sites.
- the addition may also be made by the incorporation of one or more s 6 ⁇ es ll pfes ' dht ⁇ h l g 'i ari' ::L OH '''
- the addition may be made by mutation or by full chemical synthesis ofthe peptide.
- the peptide amino acid sequence is preferably altered through changes at the DNA level, particularly by mutating the DNA encoding the peptide at preselected bases such that codons are generated that will translate into the desired amino acids.
- the DNA mutation(s) are preferably made using methods known in the art.
- the glycosylation site is added by shuffling polynucleotides.
- Polynucleotides encoding a candidate peptide can be modulated with DNA shuffling protocols.
- DNA shuffling is a process of recursive recombination and mutation, performed by random fragmentation of a pool of related genes, followed by reassembly of the fragments by a polymerase chain reaction-like process. See, e.g., Stemmer, Proc. Natl. Acad. Sci. USA 91:10747-10751 (1994); Stemmer, Nature 370:389-391 (1994); and U.S. Patent ⁇ os. 5,605,793, 5,837,458, 5,830,721 and 5,811,238.
- the present invention also provides means of adding (or removing) one or more selected glycosyl residues to a peptide, after which a modified sugar is conjugated to at least one ofthe selected glycosyl residues ofthe peptide.
- the present embodiment is useful, for example, when it is desired to conjugate the modified sugar to a selected glycosyl residue that is either not present on a peptide or is not present in a desired amount.
- the selected glycosyl residue prior to coupling a modified sugar to a peptide, the selected glycosyl residue is conjugated to the peptide by enzymatic or chemical coupling.
- the glycosylation pattern of a glycopeptide is altered prior to the conjugation ofthe modified sugar by the removal of a carbohydrate residue from the glycopeptide. See, for example WO 98/31826.
- Enzymatic cleavage of carbohydrate moieties on polypeptide variants can be achieved by the use of a variety of endo- and exo-glycosidases as described by Thotakura et al, Meth. Enzymol 138: 350 (1987). [0l ⁇ 4] !1 • ' , Ch niiMr ' fd ' ditlol l'' b ' f ; g 'c'osyl moieties is carried out by any art-recognized method.
- Enzymatic addition of sugar moieties is preferably achieved using a modification ofthe methods set forth herein, substituting native glycosyl units for the modified sugars used in the invention. Other methods of adding sugar moieties are disclosed in U.S. Patent Nos. 5,876,980, 6,030,815, 5,728,554, and 5,922,577.
- Exemplary attachment points for selected glycosyl residue include, but are not limited to: (a) consensus sites for N-linked glycosylation and O-linked glycosylation; (b) terminal glycosyl moieties that are acceptors for a glycosyltransferase; (c) arginine, asparagine and histidine; (d) free carboxyl groups; (e) free sulfhydryl groups such as those of cysteine; (f) free hydroxyl groups such as those of serine, threonine, or hydroxyproline; (g) aromatic residues such as those of phenylalanine, tyrosine, or tryptophan; or (h) the amide group of glutamine.
- the invention provides a method for linking hGH and one or more peptide through a linking group.
- the linking group is of any useful structure and may be selected from straight-chain and branched chain structures.
- each terminus of the linker, which is attached to a peptide includes a modified sugar (i.e., a nascent intact glycosyl linking group).
- two peptides are linked together via a linker moiety that includes a PEG linker.
- a PEG moiety is functionalized at a first terminus with a first glycosyl unit and at a second terminus with a second glycosyl unit.
- the first and second glycosyl units are preferably substrates for different transferases, allowing orthogonal attachment ofthe first and second peptides to the first and second glycosylunits, respectively.
- the (glycosyl) '-PEG-(glycosyl) 2 linker is contacted with the first peptide and a first transferase for which the first glycosyl unit is a substrate, thereby forming (peptide)'-(glycosyl) 1 -PEG-(glycosyl) 2 .
- Glycosyltransferase and/or unreacted peptide is then optionally rernoWd frbnAhe react ⁇ B mixture.
- the second peptide and a second transferase for which the second glycosyl unit is a substrate are added to the (peptide)'-(glycosyl) I -PEG-(glycosyl) 2 conjugate, forming
- human growth hormone is conjugated to transferrin via a bifunctional linker that includes an intact glycosyl linking group at each terminus ofthe PEG moiety (Scheme 1).
- the hGH conjugate has an in vivo half-life that is increased over that of hGH alone by virtue ofthe greater molecular sized ofthe conjugate.
- the conjugation of hGH to transferrin serves to selectively target the conjugate to the brain.
- one terminus ofthe PEG linker is functionalized with a CMP sialic acid and the other is functionalized with an UDP GalNAc.
- the linker is combined with hGH in the presence of a GalNAc transferase, resulting in the attachment ofthe GalNAc ofthe linker arm to a serine and/or threonine residue on the hGH.
- the reactions functionalizing the intact glycosyl linking groups at the termini ofthe PEG (or other) linker with the peptide can occur simultaneously in the same reaction vessel, or they can be carried out in a step-wise fashion.
- the conjugate produced at each step is optionally purified from one or more reaction components (e.g., enzymes, peptides).
- reaction components e.g., enzymes, peptides.
- G is a glycosyl residue on an activated sugar moiety (e.g., sugar nucleotide), which is converted to an intact glycosyl linker group in the conjugate.
- L is a saccharyl linking group such as GalNAc, or GalNAc-Gal.
- the invention provides a method for extending the blood-circulation half-life of a selected peptide, in essence targeting the peptide to the blood pool, by conjugating the peptide to a synthetic or natural polymer of a size sufficient to retard the filtration ofthe protein by the glomerulus (e.g., albumin).
- a synthetic or natural polymer of a size sufficient to retard the filtration ofthe protein by the glomerulus e.g., albumin.
- This embodiment ofthe invention is illustrated in Scheme 3 in which hGH is conjugated to albumin via a PEG linker using a combination of chemical and enzymatic modification.
- a residue (e.g., amino acid side chain) of albumin is modified with a reactive PEG derivative, such as X-PEG-(CMP-sialic acid), in which X is an activating group (e.g., active ester, isothiocyanate, etc).
- X is an activating group (e.g., active ester, isothiocyanate, etc).
- the PEG derivative and hGH are combined and contacted with a transferase for which CMP-sialic acid is a substrate.
- an ⁇ -amine of lysine is reacted with the N- hydroxysuccinimide ester ofthe PEG-linker to form the albumin conjugate.
- the CMP-silaic acid ofthe linker is enzymatically conjugated to an appropriate residue on hGH, e.g., Gal or GalNAc, thereby forming the conjugate.
- hGH e.g., Gal or GalNAc
- the above- described method is not limited to the reaction partners set forth.
- the method can be practiced to form conjugates that include more than two protein moieties by, for example, utilizing a branched linker having more than two termini. Toirfi ' S ars-
- Modified glycosyl donor species are preferably selected from modified sugar nucleotides, activated modified sugars and modified sugars that are simple saccharides that are neither nucleotides nor activated. Any desired carbohydrate structure can be added to a peptide using the methods ofthe invention. Typically, the structure will be a monosaccharide, but the present invention is not limited to the use of modified monosaccharide sugars; oligosaccharides and polysaccharides are useful as well.
- the modifying group is attached to a sugar moiety by enzymatic means, chemical means or a combination thereof, thereby producing a modified sugar.
- the sugars are substituted at any position that allows for the attachment ofthe modifying moiety, yet which still allows the sugar to function as a substrate for the enzyme used to ligate the modified sugar to the peptide.
- sialic acid when sialic acid is the sugar, the sialic acid is substituted with the modifying group at either the 9-position on the pyruvyl side chain or at the 5-position on the- amine moiety that is normally acetylated in sialic acid.
- a modified sugar nucleotide is utilized to add the modified sugar to the peptide.
- exemplary sugar nucleotides that are used in the present invention in their modified form include nucleotide mono-, di- or triphosphates or analogs thereof.
- the modified sugar nucleotide is selected from a UDP-glycoside, CMP-glycoside, or a GDP-glycoside.
- the modified sugar nucleotide is selected from an UDP-galactose, UDP-galactosamine, UDP- glucose, UDP-glucosamine, GDP-mannose, GDP-fucose, CMP-sialic acid, or CMP-NeuAc.
- N-acetylamine derivatives ofthe sugar nucletides are also of use in the method ofthe invention.
- the invention also provides methods for synthesizing a modified peptide using a modified sugar, e.g., modified-galactose, -fucose, -GalNAc, and -sialic acid.
- a modified sugar e.g., modified-galactose, -fucose, -GalNAc, and -sialic acid.
- a modified sialic acid either a sialyltransferase or a trans-sialidase (for ⁇ 2,3 -linked sialic acid only) can be used in these methods.
- the modified sugar is an activated sugar.
- Activated modified sugars which are useful in the present invention are typically glycosides which have been synthetically altered to include an activated leaving group.
- activated leaving group refers to those moieties, which are easily displaced in enzyme- regulated nucleophilic substitution reactions. Many activated sugars are known in the art. Sfeer ⁇ br BIOLOGY, Vol. 2, Ernst et al. Ed., Wiley- VCH Verlag: Weinheim, Germany, 2000; Kodama et al, Tetrahedron Lett. 34: 6419 (1993); Lougheed, et al, J. Biol. Chem. 274: 37717 (1999)).
- activating groups include fluoro, chloro, bromo, tosylate ester, mesylate ester, triflate ester and the like.
- Preferred activated leaving groups, for use in the present invention are those that do not significantly sterically encumber the enzymatic transfer ofthe glycoside to the acceptor. Accordingly, preferred embodiments of activated glycoside derivatives include glycosyl fluorides and glycosyl mesylates, with glycosyl fluorides being particularly preferred.
- glycosyl fluorides ⁇ -galactosyl fluoride, ⁇ -mannosyl fluoride, ⁇ -glucosyl fluoride, ⁇ -fucosyl fluoride, ⁇ -xylosyl fluoride, ⁇ - sialyl fluoride, ⁇ -N-acetylglucosaminyl fluoride, ⁇ -N-acetylgalactosaminyl fluoride, ⁇ - galactosyl fluoride, ⁇ -mannosyl fluoride, ⁇ -glucosyl fluoride, ⁇ -fucosyl fluoride, ⁇ -xylosyl fluoride, ⁇ -sialyl fluoride, ⁇ -N-acetylglucosaminyl fluoride and ⁇ -N-acetylgalactosaminyl fluoride are most preferred.
- glycosyl fluorides can be prepared from the free sugar by first acetylating the sugar and then treating it with HF/pyridine. This generates the thermodynamically most stable anomer ofthe protected (acetylated) glycosyl fluoride (z'.e., the ⁇ -glycosyl fluoride). If the less stable anomer (i.e., the ⁇ -glycosyl fluoride) is desired, it can be prepared by converting the peracetylated sugar with HBr/HOAc or with HCl to generate the anomeric bromide or chloride. This intermediate is reacted with a fluoride salt such as silver fluoride to generate the glycosyl fluoride.
- Acetylated glycosyl fluorides may be deprotected by reaction with mild (catalytic) base in methanol (e.g. NaOMe/MeOH). In addition, many glycosyl fluorides are commercially available.
- glycosyl mesylates can be prepared by treatment ofthe fully benzylated hemiacetal form ofthe sugar with mesyl chloride, followed by catalytic hydrogenation to remove the benzyl groups.
- the modified sugar is an oligosaccharide having an antennary structure.
- one or more ofthe termini ofthe antennae bear the modifying moiety.
- the oligosaccharide is useful to "amplify" the modifying moiety; each oligosaccharide unit conjugated to the peptide attaches multiple copies
- the general structure of a typical chelate ofthe invention as set forth in the drawing above encompasses multivalent species resulting from preparing a conjugate ofthe invention utilizing an antennary structure. Many antennary saccharide structures are known in the art, and the present method can be practiced with them without limitation.
- modifying groups are discussed below.
- the modifying groups can be selected for their ability to impart to a polypeptide one or more desirable properties.
- Exemplary properties include, but are not limited to, enhaced pharmacokinetics, enhanced pharmacodynamics, improved biodistribution, providing a polyvalent species, improved water solubility, enhanced or diminished lipophilicity, and tissue targeting.
- hydrophilicity of a selected peptide is enhanced by conjugation with polar molecules such as amine-, ester-, hydroxyl- and polyhydroxyl-containing molecules.
- polar molecules such as amine-, ester-, hydroxyl- and polyhydroxyl-containing molecules.
- Representative examples include, but are not limited to, polylysine, polyethyleneimine, and polyethers, e.g., poly(ethylene glycol), m-poly(ethylene glycol), poly(propyleneglycol), m- poly(propylene glycol), and other O-alkyl poly(alkylene glycol) moieties.
- Preferred water- soluble polymers are essentially non- fluorescent, or emit such a minimal amount of fluorescence that they are inappropriate for use as a fluorescent marker in an assay.
- polymers that are not naturally occurring sugars are not naturally occurring sugars.
- An exception to this preference is the use of an otherwise naturally occurring sugar that is modified by covalent attachment of another entity (e.g., poly(ethylene glycol), poly(propylene glycol), biomolecule, therapeutic moiety, diagnostic moiety, etc.).
- a therapeutic sugar moiety is conjugated to a linker arm and the sugar-linker arm cassette is subsequently conjugated to a peptide via a method ofthe invention.
- water-soluble polymer encompasses species such as saccharides (e.g., dextran, amylose, hyalouronic acid, poly(sialic acid), heparans, heparins, etc.); poly (amino acids); nucleic acids; synthetic polymers (e.g., poly(acrylic acid), poly(ethers), e.g., ⁇ oly(ethylene glycol); peptides, proteins, and the like.
- saccharides e.g., dextran, amylose, hyalouronic acid, poly(sialic acid), heparans, heparins, etc.
- poly (amino acids) nucleic acids
- synthetic polymers e.g., poly(acrylic acid), poly(ethers), e.g., ⁇ oly(ethylene glycol); peptides, proteins, and the like.
- the present invention may be practiced with any water-soluble polymer with the sole limitation that the polymer must include a point
- Preferred water-soluble polymers are those in which a substantial proportion ofthe polymer molecules in a sample ofthe polymer are of approximately the same molecular weight; such polymers are said to be “homodisperse” or “monodisperse.”
- the present invention is further illustrated by reference to a poly(ethylene glycol) or monomethoxy-poly(ethylene glycol) (m-PEG) conjugate.
- m-PEG monomethoxy-poly(ethylene glycol)
- the poly(ethylene glycol) useful in forming the conjugate ofthe invention is either linear or branched.
- the in vivo half- life or area under the curve (AUC) of therapeutic glycopeptides can also be enhanced with water-soluble polymers such as PEG, m-PEG, PPG, and m-PPG.
- water-soluble polymers such as PEG, m-PEG, PPG, and m-PPG.
- PEG PEG-ylation
- m-PEG m-PEG- ylation
- the in vivo half-life of a peptide derivatized with a water-soluble polymer by a method ofthe invention is increased relevant to the in vivo half-life or AUC ofthe non- derivatized peptide.
- the increase in peptide in vivo half-life or AUC is best expressed as a range of percent increase in this quantity.
- the lower end ofthe range of percent increase is about
- PEG moieties of any molecular weight e.g., 5 kD, 10 kD, 20 kD, and 30 kD, are of use in the present invention.
- the modified sugar bears a biomolecule.
- the biomolecule is a functional protein, enzyme, antigen, antibody, peptide, nucleic acid (e.g., single nucleotides or nucleosides, oligonucleotides, polynucleotides and single- and higher-stranded nucleic acids), lectin, receptor or a combination thereof.
- biomolecules are essentially non-fluorescent, or emit such a minimal amount of fluorescence that they are inappropriate for use as a fluorescent marker in an assay.
- biomolecules that are not sugars.
- An exception to this preference is the use of an otherwise naturally occurring sugar that is modified by covalent attachment of another entity (e.g., PEG, biomolecule, therapeutic moiety, diagnostic moiety, etc.).
- a sugar moiety, which is a biomolecule is arm cassette is subsequently conjugated to a peptide via a method ofthe invention.
- Biomolecules useful in practicing the present invention can be derived from any source.
- the biomolecules can be isolated from natural sources or they can be produced by synthetic methods.
- Peptides can be natural peptides or mutated peptides. Mutations can be effected by chemical mutagenesis, site-directed mutagenesis or other means of inducing mutations known to those of skill in the art.
- Peptides useful in practicing the instant invention include, for example, enzymes, antigens, antibodies and receptors.
- Antibodies can be either polyclonal or monoclonal; either intact or fragments.
- the peptides are optionally the products of a program of directed evolution.
- Both naturally derived and synthetic peptides and nucleic acids are of use in conjunction with the present invention; these molecules can be attached to a sugar residue component or a crosslinking agent by any available reactive group.
- peptides can be attached through a reactive amine, carboxyl, sulfhydryl, or hydroxyl group.
- the reactive group can reside at a peptide terminus or at a site internal to the peptide chain.
- Nucleic acids can be attached through a reactive group on a base (e.g., exocyclic amine) or an available hydroxyl group on a sugar moiety (e.g., 3'- or 5 '-hydroxyl).
- the peptide and nucleic acid chains can be further derivatized at one or more sites to allow for the attachment of appropriate reactive groups onto the chain. See, Chrisey et al. Nucleic Acids Res. 24: 3031-3039 (1996).
- the biomolecule is selected to direct the peptide modified by the methods ofthe invention to a specific tissue, thereby enhancing the delivery ofthe peptide to that tissue relative to the amount of underivatized peptide that is delivered to the tissue.
- the amount of derivatized peptide delivered to a specific tissue within a selected time period is enhanced by derivatization by at least about 20%, more preferably, at least about 40%, and more preferably still, at least about 100%.
- preferred biomolecules for targeting applications include antibodies, hormones and ligands for cell-surface receptors.
- conjugate with biotin there is provided as conjugate with biotin.
- a selectively biotinylated peptide is elaborated by the attachment of an avidin or streptavidin moiety bearing one or more modifying groups. ' e a ettt ⁇ 6'-M ⁇ et ⁇ &s"'
- the modified sugar includes a therapeutic moiety.
- a therapeutic moiety Those of skill in the art will appreciate that there is overlap between the category of therapeutic moieties and biomolecules; many biomolecules have therapeutic properties or potential.
- the therapeutic moieties can be agents already accepted for clinical use or they can be drugs whose use is experimental, or whose activity or mechanism of action is under investigation.
- the therapeutic moieties can have a proven action in a given disease state or can be only hypothesized to show desirable action in a given disease state.
- the therapeutic moieties are compounds, which are being screened for their ability to interact with a tissue of choice.
- Therapeutic moieties, which are useful in practicing the instant invention include drugs from a broad range of drug classes having a variety of pharmacological activities.
- Preferred therapeutic moieties are essentially non-fluorescent, or emit such a minimal amount of fluorescence that they are inappropriate for use as a fluorescent marker in an assay.
- therapeutic moieties that are not sugars.
- An exception to this preference is the use of a sugar that is modified by covalent attachment of another entity, such as a PEG, biomolecule, therapeutic moiety, diagnostic moiety and the like.
- a therapeutic sugar moiety is conjugated to a linker arm and the sugar-linker arm cassette is subsequently conjugated to a peptide via a method ofthe invention.
- the therapeutic moiety is attached to the modified sugar via a linkage that is cleaved under selected conditions.
- exemplary conditions include, but are not limited to, a selected pH (e.g., stomach, intestine, endocytotic vacuole), the presence of an active enzyme (e.g., esterase, reductase, oxidase), light, heat and the like.
- an active enzyme e.g., esterase, reductase, oxidase
- light heat and the like.
- heat and the like cleaveable groups are known in the art. See, for example, Jung et al, Biochem.
- Classes of useful therapeutic moieties include, for example, non-steroidal anti- inflammatory drugs (NSAIDS).
- NSAIDS non-steroidal anti- inflammatory drugs
- the NSAIDS can, for example, be selected from the following categories: (e.g., propionic acid derivatives, acetic acid derivatives, fenamic acid derivatives, biphenylcarboxylic acid derivatives and oxicams); steroidal anti-inflammatory drugs including hydrocortisone and the like; antihistaminic drugs (e.g., chlorpheniramine, triprolidine); antitussive drugs (e.g., dextromethorphan, codeine, caramiphen and carbetapentane); antipruritic drugs (e.g., methdilazine and trimeprazine); anticholinergic drugs (e.g., scopolamine, atropine, homatropine, levodopa); anti-emetic and antinauseant drugs (e.g., cycli
- vasodilator drugs e.g., diltiazem, amiodarone, isoxsuprine, nylidrin, tolazoline and verapamil
- vasoconstrictor drugs e.g., dihydroergotamine, ergotamine and methylsergide
- antiulcer drugs e.g., ranitidine and cimetidine
- anesthetic drugs e.g., lidocaine, bupivacaine, chloroprocaine, dibucaine
- antidepressant drugs e.g., imipramine, desipramine, amitryptiline, nortryptiline
- tranquilizer and sedative drugs e.g., chlordiazepoxide, benacytyzine, benzquinamide, flurazepam, hydroxyzine, loxapine and promazine
- antipsychotic drugs e.g., chlorprothixen
- Antimicrobial drugs which are preferred for incorporation into the present composition include, for example, pharmaceutically acceptable salts of ⁇ -lactam drugs, quinolone drugs, ciprofloxacin, norfloxacin, tetracycline, erythromycin, amikacin, triclosan, doxycycline, capreomycin, chlorhexidine, chlortetracycline, oxytetracycline, clindamycin, ethambutol, hexamidine isothionate, metronidazole, pentamidine, gentamycin, kanamycin, lineomycin, methacycline, methenamine, minocycline, neomycin, netilmycin, paromomycin, streptomycin, tobramycin, miconazole and amantadine.
- antineoplastic drugs e.g., antiandrogens (e.g., leuprolide or flutamide), cytocidal agents (e.g., adriamycin, doxorubicin, taxol, cyclophosphamide, busulfan, cisplatin, ⁇ -2-interferon) anti-estrogens (e.g., tamoxifen), antimetabolites (e.g., fluorouracil, methotrexate, mercaptopurine, thioguanine).
- antiandrogens e.g., leuprolide or flutamide
- cytocidal agents e.g., adriamycin, doxorubicin, taxol, cyclophosphamide, busulfan, cisplatin, ⁇ -2-interferon
- anti-estrogens e.g., tamoxifen
- antimetabolites e.g., fluor
- radioisotope-based agents for both diagnosis and therapy, and conjugated toxins, such as ricin, geldanamycin, mytansin, CC- 1065, the duocarmycins, Chlicheamycin and related structures and analogues thereof.
- the therapeutic moiety can also be a hormone (e.g., medroxyprogesterone, estradiol, leuprolide, megestrol, octreotide or somatostatin); muscle relaxant drugs (e.g., cinnamedrine, cyclobenzaprine, flavoxate, orphenadrine, papaverine, mebeverine, idaverine, ritodrine, diphenoxylate, dantrolene and azumolen); antispasmodic drugs; bone-active drugs (e.g., diphosphonate and phosphonoalkylphosphinate drug compounds); endocrine modulating drugs (e.g., contraceptives (e.g., ethinodiol, ethinyl estradiol, norethindrone, mestranol, desogestrel, medroxyprogesterone), modulators of diabetes (e.g., glycerin,
- estrogens e.g., diethylstilbesterol
- glucocorticoids e.g., triamcinolone, betamethasone, etc.
- progestogens such as norethindrone, ethynodiol, norethindrone, levonorgestrel
- thyroid agents e.g., liothyronine or levothyroxine
- anti-thyroid agents e.g., methimazole
- antihyperprolactinemic drugs e.g., cabergoline
- hormone suppressors e.g., danazol or goserelin
- oxytocics e.g., methylergonovine or oxytocin
- prostaglandins such as mioprostol, alprostadil or dinoprostone
- Other useful modifying groups include immunomodulating drugs (e.g., antihistamines, mast cell stabilizers, such as lodoxamide and/or cromolyn, steroids (e.g., triamcinolone, beclomethazone, cortisone, dexamethasone, prednisolone, methylprednisolone, beclomethasone, or clobetasol), histamine H2 antagonists (e.g., famotidine, cimetidine, ranitidine), immunosuppressants (e.g., azathioprine, cyclosporin), etc.
- immunomodulating drugs e.g., antihistamines, mast cell stabilizers, such as lodoxamide and/or cromolyn
- steroids e.g., triamcinolone, beclomethazone, cortisone, dexamethasone, prednisolone, methylprednisolone, beclomethasone, or clobe
- the sugar moiety and the modifying group are linked together through the use of reactive groups, which are typically transformed by the linking process into a new organic functional group or species that is unreactive under physiologically relevant conditions.
- the sugar reactive functional group(s) is located at any position on the sugar moiety.
- Reactive groups and classes of reactions useful in practicing the present invention are generally those that are well known in the art of bioconjugate chemistry. Currently favored classes of reactions available with reactive sugar moieties are those, which proceed under relatively mild conditions.
- nucleophilic substitutions e.g., reactions of amines and alcohols with acyl halides, active esters
- electrophilic substitutions e.g., enamine reactions
- additions to carbon-carbon and carbon-heteroatom multiple bonds e.g., Michael reaction, Diels- Alder addition.
- Useful reactive functional groups pendent from a sugar nucleus or modifying group include, but are not limited to: (a) carboxyl groups and various derivatives thereof including, but not limited to,
- N-hydroxysuccinimide esters N-hydroxybenztriazole esters, acid halides, acyl imidazoles, thioesters, p-nitrophenyl esters, alkyl, alkenyl, alkynyl and aromatic esters;
- hydroxyl groups which can be converted to, e.g., esters, ethers, aldehydes, etc.
- haloalkyl groups wherein the halide can be later displaced with a nucleophilic group such as, for example, an amine, a carboxylate anion, thiol anion, carbanion, or an alkoxide ion, thereby resulting in the covalent attachment of a new group at the functional group ofthe halogen atom;
- dienophile groups which are capable of participating in Diels- Alder reactions such as, for example, maleimido groups;
- amine or sulfhydryl groups which can be, for example, acylated, alkylated or oxidized;
- alkenes which can undergo, for example, cycloadditions, acylation, Michael addition, etc.
- the reactive functional groups can be chosen such that they do not participate in, or interfere with, the reactions necessary to assemble the reactive sugar nucleus or modifying group.
- a reactive functional group can be protected from participating in the reaction by the presence of a protecting group.
- protecting groups see, for example, Greene et al, PROTECTIVE GROUPS IN ORGANIC SYNTHESIS, John Wiley & Sons, New York, 1991.
- sialic acid derivative is utilized as the sugar nucleus to which the modifying group is attached.
- the focus ofthe discussion on sialic acid derivatives is for clarity of illustration only and should not be construed to limit the scope ofthe invention.
- Those of skill in the art will appreciate that a variety of other sugar moieties can be activated and derivatized in a manner analogous to that set forth using sialic acid as an example.
- the peptide that is modified by a method ofthe invention is a glycopeptide that is produced in prokaryotic cells (e.g., E.coli), eukaryotic cells lricludmg'yeast-an ⁇ t rhamfna'lilan-eeH's (e.g., CHO cells), or in a transgenic animal and thus, contains N- and/or O-linked oligosaccharide chains, which are incompletely sialylated.
- the oligosaccharide chains ofthe glycopeptide lacking a sialic acid and containing a terminal galactose residue can be PEG-ylated, PPG-ylated or otherwise modified with a modified sialic acid.
- Exemplary PEG-sialic acid derivative include:
- L is a substituted or unsubstituted alkyl or substituted or unsubstituted heteroalkyl linker moiety joining the sialic acid moiety and the PEG moiety, and "n" is 1 or greater;
- index "s" represents an integer from 0 to 20, and "n" is 1 or greater.
- the amino glycoside 1 is treated with the active ester of a protected amino acid (e.g., glycine) derivative, converting the sugar amine residue into the corresponding protected amino acid amide adduct.
- the adduct is treated with an aldolase to form ⁇ -hydroxy carboxylate 2.
- Compound 2 is converted to the corresponding CMP derivative by the action of CMP-SA synthetase, followed by catalytic hydrogenation ofthe CMP derivative to produce compound 3.
- the amine introduced via formation ofthe glycine adduct is utilized as a locus of PEG attachment by reacting compound 3 with an activated PEG or PPG derivative (e.g., PEG-C(O)NHS, PEG-OC(O)O-p-nitrophenyl), producing species such as 4 or 5, respectively.
- an activated PEG or PPG derivative e.g., PEG-C(O)NHS, PEG-OC(O)O-p-nitrophenyl
- Table 1 sets forth representative examples of sugar monophosphates that are derivatized with a PEG or PPG moiety.
- Human growth hormone mutants can be modified by the method of Scheme 1.
- Other derivatives are prepared by art-recognized methods. See, for example, Keppler et al, Glycobiology 11: 11R (2001); and Charter et al., Glycobiology 10: 1049 (2000)).
- Other amine reactive PEG and PPG analogues are commercially available, or they can be prepared by methods readily accessible to those of skill in the art.
- modified sugar phosphates of use in practicing the present invention can be substituted in other positions as well as those set forth above.
- Presently preferred substitutions of sialic acid are set forth in Formula I:
- X is a linking group, which is preferably selected from -O-, -N(H)-, -S, CH 2 -, and - N(R) 2 , in which each R is a member independently selected from R'-R 5 .
- the symbols Y, Z, A and B each represent a group that is selected from the group set forth above for the identity of X.
- X, Y, Z, A and B are each independently selected and, therefore, they can be the same or di ' fferdhf. K » , s ;
- R 4 and R 5 represent H, a water-soluble polymer, therapeutic moiety, biomolecule or other moiety.
- moieties attached to the conjugates disclosed herein include, but are not limited to, PEG derivatives (e.g., alkyl-PEG, acyl-PEG, acyl-alkyl-PEG, alkyl-acyl-PEG carbamoyl-PEG, aryl-PEG), PPG derivatives (e.g., alkyl-PPG, acyl-PPG, acyl-alkyl-PPG, alkyl-acyl-PPG carbamoyl-PPG, aryl-PPG), therapeutic moieties, diagnostic moieties, mannose-6-phosphate, heparin, heparan, SLe x , mannose, mannose-6-phosphate, Sialyl Lewis X, FGF, NFGF, proteins, chondroitin, keratan, dermatan, albumin
- Preparation ofthe modified sugar for use in the methods ofthe present invention includes attachment of a modifying group to a sugar residue and forming a stable adduct, which is a substrate for a glycosyltransferase.
- the sugar and modifying group can be coupled by a zero- or higher-order cross-linking agent.
- Exemplary bifunctional compounds which can be used for attaching modifying groups to carbohydrate moieties include, but are not limited to, bifunctional poly(ethyleneglycols), polyamides, polyethers, polyesters and the like. General approaches for linking carbohydrates to other molecules are known in the literature. See, for example, Lee et al, Biochemistry 28: 1856 (1989); Bhatia et al, Anal. Biochem.
- SPDP detrimentally affects the ability ofthe modified sugar to act as a glycosyltransferase substrate
- one of an array of other crosslinkers such as 2-iminothiolane or N-succinimidyl S-acetylthioacetate (SAT A) is used to form a disulfide bond.
- 2- iminothiolane reacts with primary amines, instantly incorporating an unprotected sulfhydryl onto the amine-containing molecule.
- SATA also reacts with primary amines, but incorporates a protected sulfhydryl, which is later deacetaylated using hydroxylamine to produce a free sulfhydryl. In each case, the incorporated sulfhydryl is free to react with other sulfhydryls or protected sulfhydryl, like SPDP, forming the required disulfide bond.
- TPCH(S-(2-thiopyridyl)-L- cysteine hydrazide and TPMPH (S-(2-thiopyridyl) mercapto-propionohydrazide) react with carbohydrate moieties that have been previously oxidized by mild periodate treatment, thus forming a hydrazone bond between the hydrazide portion ofthe crosslinker and the periodate generated aldehydes.
- TPCH and TPMPH introduce a 2-pyridylthione protected sulfhydryl group onto the sugar, which can be deprotected with DTT and then subsequently used for conjugation, such as forming disulfide bonds between components.
- crosslinkers may be used that incorporate more stable bonds between components.
- the heterobifunctional crosslinkers GMBS (N-gama-malimidobutyryloxy)succinim ' ide) and SMCC (succinimidyl 4-(N-maleimido-methyl)cyclohexane) react with primary amines, thus introducing a maleimide group onto the component.
- the maleimide group can subsequently react with sulfhydryls on the other component, which can be introduced by previously mentioned crosslinkers, thus forming a stable thioether bond between the components.
- crosslinkers can be used which introduce long spacer arms between components and include derivatives of some ofthe previously mentioned crosslinkers (i.e., SPDP).
- SPDP some ofthe previously mentioned crosslinkers
- a variety of reagents are used to modify the components ofthe modified sugar with intramolecular chemical crosslinks (for reviews of crosslinking reagents and crosslinking procedures see: Wold, F., Meth. Enzymol. 25: 623-651, 1972; Weetall, H. H., and Cooney, D. A., In: ENZYMES AS DRUGS. (Holcenberg, and Roberts, eds.) pp. 395-442, Wiley, New York, 1981; Ji, T. H., Meth. Enzymol. 91: 580-609, 1983; Mattson et al, Mol Biol. Rep. 17: 167- 183, 1993, all of which are incorporated herein by reference).
- Preferred crosslinking reagents are derived from various zero-length, homo-bifunctional, and hetero-bifunctional crosslinking reagents.
- Zero-length crosslinking reagents include direct conjugation of two intrinsic chemical groups with no introduction of extrinsic material. Agents that catalyze formation of a disulfide bond belong to this category.
- Another example is reagents that induce condensation of a carboxyl and a primary amino group to form an amide bond such as carbodiimides, ethylchloroformate, Woodward's reagent K (2-ethyl-5-phenylisoxazolium-3'- sulfonate), and carbonyldiimidazole.
- transglutaminase (glutamyl-peptide ⁇ -glutamyltransferase; EC 2.3.2.13) may be used as zero- length crosslinking reagent.
- This enzyme catalyzes acyl transfer reactions at carboxamide groups of protein-bound glutaminyl residues, usually with a primary amino group as substrate.
- Preferred homo- and hetero-bifunctional reagents contain two identical or two dissimilar sites, respectively, which may be reactive for amino, sulfhydryl, guanidino, indole, or nonspecific groups.
- the sites on the cross-linker are amino-reactive groups.
- amino-reactive groups include carbonate esters, N- hydroxysuccinimide (NHS) esters, imidoesters, isocyanates, acylhalides, arylazides, p- nitrophenyl esters, aldehydes, and sulfonyl chlorides.
- NHS esters react preferentially with the primary (including aromatic) amino groups of a modified sugar component.
- the imidazole groups of histidines are known to compete with primary amines for reaction, but the reaction products are unstable and readily hydro lyzed.
- the reaction involves the nucleophilic attack of an amine on the acid carboxyl of an NHS ester to form an amide, releasing the N-hydroxysuccinimide. Thus, the positive charge ofthe original amino group is lost.
- [0239-]" •' "I ⁇ i ⁇ ab'eStbfs'ar ' e the ' m'o'st'specific acylating reagents for reaction with the amine groups ofthe modified sugar components.
- imidoesters react only with primary amines.
- Primary amines attack imidates nucleophilically to produce an intermediate that breaks down to amidine at high pH or to a new imidate at low pH.
- the new imidate can react with another primary amine, thus crosslinking two amino groups, a case of a putatively monofunctional imidate reacting bifunctionally.
- the principal product of reaction with primary amines is an amidine that is a stronger base than the original amine. The positive charge ofthe original amino group is therefore retained.
- Isocyanates (and isothiocyanates) react with the primary amines ofthe modified sugar components to form stable bonds. Their reactions with sulfhydryl, imidazole, and tyrosyl groups give relatively unstable products.
- Acylazides are also used as amino-specific reagents in which nucleophilic amines of the affinity component attack acidic carboxyl groups under slightly alkaline conditions, e.g. pH 8.5.
- Arylhalides such as l,5-difluoro-2,4-dinitrobenzene react preferentially with the amino groups and tyrosine phenolic groups of modified sugar components, but also with sulfhydryl and imidazole groups.
- p-Nitrophenyl esters of mono- and dicarboxylic acids are also useful amino-reactive groups. Although the reagent specificity is not very high, ⁇ - and ⁇ -amino groups appear to react most rapidly.
- Aldehydes such as glutaraldehyde react with primary amines of modified sugar.
- unstable Schiff bases are formed upon reaction ofthe amino groups with the aldehydes ofthe aldehydes, glutaraldehyde is capable of modifying the modified sugar with stable crosslinks.
- the cyclic polymers undergo a dehydration to form ⁇ - ⁇ unsaturated aldehyde polymers.
- Schiff bases are stable, when conjugated to another double bond. The resonant interaction of both double bonds prevents hydrolysis ofthe Schiff linkage.
- amines at high local concentrations can attack the ethylenic double bond to form a stable Michael addition product.
- Aromatic sulfonyl chlorides react with a variety of sites ofthe modified sugar components, but reaction with the amino groups is the most important, resulting in a stable sulfonamide linkage.
- the sites are sulfhydryl-reactive groups.
- Useful, non-limiting examples of sulfhydryl-reactive groups include maleimides, alkyl halides, pyridyl disulfides, and thiophthalimides.
- Maleimides react preferentially with the sulfhydryl group ofthe modified sugar components to form stable thioether bonds. They also react at a much slower rate with primary amino groups and the imidazole groups of histidines.
- the maleimide group can be considered a sulfhydryl-specific group, since at this pH the reaction rate of simple thiols is 1000-fold greater than that ofthe corresponding amine.
- Alkyl halides react with sulfhydryl groups, sulfides, imidazoles, and amino groups. At neutral to slightly alkaline pH, however, alkyl halides react primarily with sulfhydryl groups to form stable thioether bonds. At higher pH, reaction with amino groups is favored.
- Carboxyl-Reactive Residue [0251]
- carbodiimides soluble in both water and organic solvent are used as carboxyl-reactive reagents. These compounds react with free carboxyl groups forming a pseudourea that can then couple to available amines yielding an amide linkage teach how to modify a carboxyl group with carbodiimde (Yamada et al, Biochemistry 20: 4836-4842, 1981).
- the present invention contemplates the use of non-specific reactive groups to link the sugar to the modifying group.
- Exemplary non-specific cross-linkers include photoactivatable groups, completely inert in the dark, which are converted to reactive species upon absorption of a photon of appropriate energy.
- Electron-deficient arylnitrenes rapidly ring- expand to form dehydroazepines, which tend to react with nucleophiles, rather than form C-H miseittiom prdkJirots,!' "li'ae v&el ⁇ Wl ⁇ of 'arylazides can be increased by the presence of electron- withdrawing substituents such as nitro or hydroxyl groups in the ring. Such substituents push the abso ⁇ tion maximum of arylazides to longer wavelength.
- Unsubstituted arylazides have an absorption maximum in the range of 260-280 nm, while hydroxy and nitroarylazides absorb significant light beyond 305 nm. Therefore, hydroxy and nitroarylazides are most preferable since they allow to employ less harmful photolysis conditions for the affinity component than unsubstituted arylazides.
- photoactivatable groups are selected from fluorinated arylazides.
- the photolysis products of fluorinated arylazides are arylnitrenes, all of which undergo the characteristic reactions of this group, including C-H bond insertion, with high efficiency (Keana et al, J. Org. Chem. 55: 3640-3647, 1990).
- photoactivatable groups are selected from benzophenone residues. Benzophenone reagents generally give higher crosslinking yields than arylazide reagents.
- photoactivatable groups are selected from diazo compounds, which form an electron-deficient carbene upon photolysis. These carbenes undergo a variety of reactions including insertion into C-H bonds, addition to double bonds (including aromatic systems), hydrogen attraction and coordination to nucleophilic centers to give carbon ions.
- photoactivatable groups are selected from diazopyruvates.
- the p-nitrophenyl ester of p-nitrophenyl diazopyruvate reacts with aliphatic amines to give diazopyruvic acid amides that undergo ultraviolet photolysis to form aldehydes.
- the photolyzed diazopyruvate-modif ⁇ ed affinity component will react like formaldehyde or glutaraldehyde forming crosslinks.
- Preferred, non-limiting examples of homobifunctional NHS esters include disuccinimidyl glutarate (DSG), disuccinimidyl suberate (DSS), bis(sulfosuccinimidyl) suberate (BS), disuccinimidyl tartarate (DST), disulfosuccinimidyl tartarate (sulfo-DST), bis- carbonyloxy)ethylsulfone (sulfo-BSOCOES), ethylene glycolbis(succinimidylsuccinate) (EGS), ethylene glycolbis(sulfosuccinimidylsuccinate) (sulfo-EGS), dithiobis(succinimidyl- propionate (DSP), and dithiobis(sulfosuccinimidylpropionate (sulfo-DSP).
- DSG disuccinimidyl glutarate
- DST bis(sulfosuccin
- homobifunctional imidoesters include dimethyl malonimidate (DMM), dimethyl succinimidate (DMSC), dimethyl adipimidate (DMA), dimethyl pimelimidate (DMP), dimethyl suberimidate (DMS), dimethyl-3,3'-oxydipropionimidate (DODP), dimethyl-3 ,3 '-(methylenedioxy)dipropionimidate (DMDP), dimethyl-,3 '- (dimethyl enedioxy)dipropionimidate (DDDP), dimethyl-3 ,3 '-(tetramethylenedioxy)- dipropionimidate (DTDP), and dimethyl-3 ,3'-dithiobispropionimidate (DTBP).
- DM malonimidate
- DMSC dimethyl succinimidate
- DMA dimethyl adipimidate
- DMP dimethyl pimelimidate
- DMS dimethyl suberimidate
- DODP dimethyl-3,3'-oxydipropionimidate
- DMDP
- homobifunctional isothiocyanates include: p- phenylenediisothiocyanate (DITC), and 4,4'-diisothiocyano-2,2'-disulfonic acid stilbene (DIDS).
- DITC p- phenylenediisothiocyanate
- DIDS 4,4'-diisothiocyano-2,2'-disulfonic acid stilbene
- Preferred, non-limiting examples of homobifunctional isocyanates include xylene- diisocyanate, toluene-2,4-diisocyanate, toluene-2-isocyanate-4-isothiocyanate, 3- methoxydiphenylmethane-4,4'-diisocyanate, 2,2'-dicarboxy-4,4'-azophenyldiisocyanate, and hexamethylenediisocyanate.
- homobifunctional arylhalides include 1,5- difluoro-2,4-dinitrobenzene (DFDNB), and 4,4'-difluoro-3,3'-dinitrophenyl-sulfone.
- Preferred, non-limiting examples of homobifunctional aliphatic aldehyde reagents include glyoxal, malondialdehyde, and glutaraldehyde.
- Preferred, non-limiting examples of homobifunctional acylating reagents include nitrophenyl esters of dicarboxylic acids.
- Preferred, non-limiting examples of homobifunctional aromatic sulfonyl chlorides include phenol-2,4-disulfonyl chloride, and ⁇ -naphthol-2,4-disulfonyl chloride.
- Preferred, non-limiting examples of additional amino-reactive homobifunctional reagents include erythritolbiscarbonate which reacts with amines to give biscarbamates.
- homobifunctional maleimides include bismaleimidohexane (BMH), N,N'-(l,3-phenylene) bismaleimide, N,N'-(1,2- phenylene)bismaleimide, azophenyldimaleimide, and bis(N-maleimidomethyl)ether.
- Preferred, non-limiting examples of homobifunctional pyridyl disulfides include l,4-di-3'-(2'-pyridyldithio)propionamidobutane (DPDPB).
- Preferred, non- limiting examples of homobifunctional alkyl halides include 2,2'- dicarboxy-4,4'-diiodoacetamidoazobenzene, ⁇ , ⁇ '-diiodo-p-xylenesulfonic acid, ⁇ , ⁇ '-dibromo- p-xylenesulfonic acid, N,N'-bis(b-bromoethyl)benzylamine, N,N'- di(bromoacetyl)phenylthydrazine, and 1 ,2-di(bromoacetyl)amino-3 -phenylpropane.
- homobifunctional photoactivatable crosslinker examples include bis- ⁇ -(4-azidosalicylamido)ethyldisulfide (BASED), di-N-(2-nitro-4-azidophenyl)- cystamine-S,S-dioxide (DNCO), and 4,4'-dithiobisphenylazide.
- hetero-bifunctional reagents with a pyridyl disulfide moiety and an amino-reactive NHS ester include N-succinimidyl-3-(2- pyridyldithio)propionate (SPDP), succinimidyl 6-3-(2-pyridyldithio)propionamidohexanoate (LC-SPDP), sulfosuccinimidyl 6-3-(2-pyridyldithio)propionamidohexanoate (sulfo- LCSPDP), 4-succinimidyloxycarbonyl- ⁇ -methyl- ⁇ -(2-pyridyldithio)toluene (SMPT), and sulfosuccinimidyl 6- ⁇ -methyl- ⁇ -(2-pyridyldithio)toluamidohexanoate (sulfo-LC-SMPT).
- SPDP N-succinimid
- hetero-bifunctional reagents with a maleimide moiety and an amino-reactive NHS ester include succinimidyl maleimidylacetate (AMAS), succinimidyl 3-maleimidylpropionate (BMPS), N- ⁇ -maleimidobutyryloxysuccinimide ester (GMBS)N- ⁇ -maleimidobutyryloxysulfo succinimide ester (sulfo-GMBS) succinimidyl 6- maleimidylhexanoate (EMCS), succinimidyl 3-maleimidylbenzoate (SMB), m- maleimidobenzoyl-N-hydroxysuccinimide ester (MBS), m-maleimidobenzoyl-N-
- hetero-bifunctional reagents with an alkyl halide moiety and an amino-reactive NHS ester include N-succinimidyl-(4- iodoacetyl)aminobenzoate (SIAB), sulfosuccinimidyl-(4-iodoacetyl)aminobenzoate (sulfo- SIAB), succinimidyl-6-(iodoacetyl)aminohexanoate (SIAX), succinimidyl-6-(6-((iodoacetyl)- amino)hexanoylamino)hexanoate (SIAXX), succinimidyl-6-(((4-(iodoacetyl)-a
- a preferred example of a hetero-bifunctional reagent with an amino-reactive NHS ester and an alkyl dihalide moiety is N-hydroxysuccinimidyl 2,3-dibromopropionate (SDBP). SDBP introduces intramolecular crosslinks to the affinity component by conjugating its amino groups. The reactivity ofthe dibromopropionyl moiety towards primary amine groups is controlled by the reaction temperature (McKenzie et al, Protein Chem. 7: 581-592 (1988)).
- hetero-bifunctional reagents with an alkyl halide moiety and an amino-reactive p-nitrophenyl ester moiety include p-nitrophenyl iodoacetate (NPIA).
- NPIA p-nitrophenyl iodoacetate
- the linker group is provided with a group that can be cleaved to release the modifying group from the sugar residue.
- Many cleaveable groups are known in the art. See, for example, Jung et al, Biochem. Biophys. Ada 761: 152-162 (1983); Joshi et al, J. Biol. Chem. 265: 14518-14525 (1990); Zarling et al, J. Immunol 124: 913-920 (1980); Bouizar et al, Eur. J. Biochem. 155: 141-147 (1986); Park et al, J. Biol. Chem.
- Exemplary cleaveable moieties can be cleaved using light, heat or reagents such as thiols, hydroxylamine, bases, periodate and the like. Moreover, certain preferred groups are cleaved in vivo in response to being endocytized (e.g., cis-aconityl; see, Shen et al, Biochem. Biophys. Res. Commun. 102: 1048 (1991)). Preferred cleaveable groups comprise a cleaveable moiety which is a member selected from the group consisting of disulfide, ester, imide, carbonate, nitrobenzyl, phenacyl and benzoin groups.
- the modified sugars are conjugated to a glycosylated or non-glycosylated peptide using an appropriate enzyme to mediate the conjugation.
- concentrations of the modified donor sugar(s), enzyme(s) and acceptor peptide(s) are selected such that glycosylation proceeds until the acceptor is consumed.
- glycosyltransferases A number of methods of using glycosyltransferases to synthesize desired oligosaccharide structures are known and are generally applicable to the instant invention. Exemplary methods are described, for instance, WO 96/32491, Ito et al, Pure Appl. Chem. 65: 753 (1993), and U.S. Pat. Nos. 5,352,670, 5,374,541, and 5,545,553. [0283] The present invention is practiced using a single glycosyltransferase or a combination of glycosyltransferases.
- e enzymes ana substrates are preferably combined in an initial reaction mixture, or the enzymes and reagents for a second enzymatic reaction are added to the reaction medium once the first enzymatic reaction is complete or nearly complete.
- each ofthe first and second enzyme is a glycosyltransferase.
- one enzyme is an endoglycosidase.
- more than two enzymes are used to assemble the modified glycoprotein ofthe invention. The enzymes are used to alter a saccharide structure on the peptide at any point either before or after the addition ofthe modified sugar to the peptide.
- the method makes use of one or more exo- or endoglycosidase.
- the glycosidase is typically a mutant, which is engineered to form glycosyl bonds rather than cleave them.
- the mutant glycanase typically includes a substitution of an amino acid residue for an active site acidic amino acid residue.
- the substituted active site residues will typically be Asp at position 130, Glu at position 132 or a combination thereof.
- the amino acids are generally replaced with serine, alanine, asparagine, or glutamine.
- the mutant enzyme catalyzes the reaction, usually by a synthesis step that is analogous to the reverse reaction ofthe endoglycanase hydrolysis step.
- the glycosyl donor molecule e.g., a desired oligo- or mono-saccharide structure
- the leaving group can be a halogen, such as fluoride.
- the leaving group is a Asn, or a Asn- peptide moiety.
- the GlcNAc residue on the glycosyl donor molecule is modified.
- the GlcNAc residue may comprise a 1,2 oxazoline moiety.
- each ofthe enzymes utilized to produce a conjugate of the invention are present in a catalytic amount.
- the catalytic amount of a particular enzyme varies according to the concentration of that enzyme's substrate as well as to reaction conditions- ⁇ uc>l
- the temperature at which an above process is carried out can range from just above freezing to the temperature at which the most sensitive enzyme denatures. Preferred temperature ranges are about 0 °C to about 55 °C, and more preferably about 20 ° C to about 30 °C. In another exemplary embodiment, one or more components ofthe present method are conducted at an elevated temperature using a thermophilic enzyme. ⁇
- the reaction mixture is maintained for a period of time sufficient for the acceptor to , be glycosylated, thereby forming the desired conjugate. Some ofthe conjugate can often be detected after a few hours, with recoverable amounts usually being obtained within 24 hours or less.
- rate of reaction is dependent on a number of variable factors (e.g, enzyme concentration, donor concentration, acceptor concentration, temperature, solvent volume), which are optimized for a selected system.
- the present invention also provides for the industrial-scale production of modified peptides.
- an industrial scale generally produces at least about 250 mg, preferably at least about 500 mg, and more preferably at least about 1 gram of finished, purified conjugate, preferably after a single reaction cycle, i.e., the conjugate is not a combination the reaction products from identical, consecutively iterated synthesis cycles.
- the invention is exemplified by the conjugation of modified sialic acid moieties to a glycosylated peptide.
- the exemplary modified sialic acid is labeled with m-PEG.
- An enzymatic approach can be used for the selective introduction of m-PEG-ylated or m-PPG-ylated carbohydrates onto a peptide or glycopeptide.
- the method utilizes modified sugars containing PEG, PPG, or a masked reactive functional group, and is combined with the appropriate glycosyltransferase or glycosynthase.
- the PEG or PPG can be introduced directly onto the peptide backbone, onto existing sugar residues of a glycopeptide or onto sugar residues that have been added to a peptide.
- acceptor for the sialyltransferase is present on the peptide to be modified by the methods ofthe present invention either as a naturally occurring structure or one placed there recombinantly, enzymatically or chemically.
- Suitable acceptors include, for example, galactosyl acceptors such as Gal ⁇ l,4GlcNAc, Gal ⁇ l,4GalNAc, Gal ⁇ 1,3 GalNAc, lacto-N- tetraose, Gal ⁇ 1,3 GlcNAc, GalNAc, Gal ⁇ 1,3 GalNAc, Gal ⁇ l,6GlcNAc, Gal ⁇ l,4Glc (lactose), and other acceptors known to those of skill in the art (see, e.g., Paulson et al, J. Biol. Chem. 253: 5617-5624 (1978)).
- an acceptor for the sialyltransferase is present on the glycopeptide to be modified upon in vivo synthesis ofthe glycopeptide.
- Such glycopeptides can be sialylated using the claimed methods without prior modification ofthe glycosylation pattern ofthe glycopeptide.
- the methods ofthe invention can be used to sialylate a peptide that does not include a suitable acceptor; one first modifies the peptide to include an acceptor by methods known to those of skill in the art.
- a GalNAc residue is added by the action of a GalNAc transferase.
- the galactosyl acceptor is assembled by attaching a galactose residue to an appropriate acceptor linked to the peptide, e.g., a GalNAc.
- the method includes incubating the peptide to be modified with a reaction mixture that contains a suitable amount of a galactosyltransferase (e.g., Gal ⁇ 1,3 or Gal ⁇ 1,4), and a suitable galactosyl donor (e.g., UDP-galactose).
- a galactosyltransferase e.g., Gal ⁇ 1,3 or Gal ⁇ 1,4
- a suitable galactosyl donor e.g., UDP-galactose
- glycopeptide-linked oligosaccharides are first "trimmed," either in whole or in part, to expose either an acceptor for the sialyltransferase or a moiety to which one or more appropriate residues can be added to obtain a suitable , acceptor.
- Enzymes such as glycosyltransferases and endoglycosidases (see, for example U.S. Patent No. 5,716,812) are useful for the attaching and trimming reactions.
- an O-linked carbohydrate residue is "trimmed" prior to the addition ofthe modified sugar.
- a GalNAc-Gal residue is trimmed back to GalNAc.
- a modified sugar bearing a water-soluble polymer is conjugated to one or more of the sugar residues exposed by the "trimming.”
- a glycopeptide is "trimmed” and a water-soluble polymer is added to the resulting O-side chain amino acid or glycopeptide glycan via a saccharyl moiety, e.g., Sia, Gal, or GalNAc moiety conjugated to the water-soluble polymer.
- the modified saccharyl moiety is attached to an acceptor site on the "trimmed" glycopeptide.
- an unmodified saccharyl moiety e.g., Gal can be added the terminus ofthe O-linked glycan.
- a water-soluble polymer is added to a GalNAc residue via a modified sugar having a galactose residue.
- an unmodified Gal can be added to the terminal GalNAc residue.
- a water-soluble polymer is added onto a Gal residue using a modified sialic acid.
- an O-linked glycosyl residue is "trimmed back" to the GalNAc attached to the amino acid.
- a water-soluble polymer is added via a Gal modified with the polymer.
- an unmodified Gal is added to the GalNAc, followed by a Gal with an attached water-soluble polymer.
- one or more unmodified Gal residue is added to the GalNAc, followed by a sialic acid moiety modified with a water-soluble polymer.
- the modified sugar can be added to the termini ofthe carbohydrate moiety as set forth above, or it can be intermediate between the peptide core and the terminus ofthe carbohydrate.
- the water-soluble polymer is added to a terminal Gal residue using a polymer modified sialic acid.
- An appropriate sialyltransferase is used to add a modified sialic acid. The approach is summarized in Scheme 5.
- a masked reactive functionality is present on the sialic acid.
- the masked reactive group is preferably unaffected by the conditions used to attach the modified sialic acid to the peptide.
- the mask is removed and the peptide is conjugated with an agent such as PEG, PPG, a therapeutic moiety, biomolecule or other agent.
- the agent is conjugated to the peptide in a specific manner by its reaction with the unmasked reactive group on the modified sugar residue.
- Any modified sugar can be used with its appropriate glycosyltransferase, depending on the terminal sugars ofthe oligosaccharide side chains ofthe glycopeptide (Table 2).
- the terminal sugar ofthe glycopeptide required for introduction ofthe PEG- ylated or PPG-ylated structure can be introduced naturally during expression or it can be produced post expression using the appropriate glycosidase(s), glycosyltransferase(s) or mix of glycosidase(s) and glycosyltransferase(s).
- Ligand of interest acyl-PEG, acyl-PPG, alkyl-PEG, acyl-alkyl-PEG, acyl-alkyl-PEG, carbamoyl-PEG, carbamoyl-PPG, PEG, PPG,
- Q H 2 , O, S, NH, N-R. acyl-aryl-PEG, acyl-aryl-PPG, aryl-PEG, aryl-PPG, Mannose-g-phosphate, heparin, heparan, SLex, Mannose, FGF, VFGF,
- R, R H, Linker-M, M. protein, chondroitin, keratan, dermatan, albumin, integrins, peptides, etc.
- M Ligand of interest ⁇ ⁇ f .• • lft.'a' ' ⁇ rth' .'ex ⁇ lSry»i bodiment, UDP-galactose-PEG is reacted with bovine milk ⁇ l,4-galactosyltransferase, thereby transferring the modified galactose to the appropriate terminal N-acetylglucosamine structure.
- the terminal GlcNAc residues on the glycopeptide may be produced during expression, as may occur in such expression systems as mammalian, insect, plant or fungus, but also can be produced by treating the glycopeptide with a sialidase and/or glycosidase and/or glycosyltransferase, as required.
- a GlcNAc transferase such as GNT1-5, is utilized to transfer PEGylated-GlcN to a terminal mannose residue on a glycopeptide.
- an the N- and/or O-linked glycan structures are enzymatically removed from a glycopeptide to expose an amino acid or a terminal glycosyl residue that is subsequently conjugated with the modified sugar.
- an endoglycanase is used to remove the N-linked structures of a glycopeptide to expose a terminal GlcNAc as a GlcNAc-linked-Asn on the glycopeptide.
- UDP-Gal-PEG and the appropriate galactosyltransferase is used to introduce the PEG- or PPG-galactose functionality onto the exposed GlcNAc.
- the modified sugar is added directly to the peptide backbone using a glycosyltransferase known to transfer sugar residues to the peptide backbone.
- a glycosyltransferase known to transfer sugar residues to the peptide backbone.
- This exemplary embodiment is set forth in Scheme 7.
- Exemplary glycosyltransferases useful in practicing the present invention include, but are not limited to, GalNAc transferases (GalNAc Tl-20), GlcNAc transferases, fucosyltransferases, glucosyltransferases, xylosylrransferases, mannosyltransferases and the like. Use of this approach allows the direct addition of modified sugars onto peptides that lack any carbohydrates or, alternatively, onto existing glycopeptides.
- the addition ofthe modified sugar occurs at specific positions on the peptide backbone as defined by the substrate specificity ofthe glycosyltransferase and not in a random manner as occurs during modification of a protein's peptide backbone using chemical methods.
- An array of agents can be introduced into proteins or glycopeptides that lack the glycosyltransferase substrate peptide sequence by engineering the appropriate amino acid sequence into the polypeptide chain.
- one or more additional chemical or enzymatic modification steps can be utilized following the conjugation ofthe modified sugar to the peptide.
- an enzyme e.g., fucosyltransferase
- a glycosyl unit e.g., fucose
- an enzymatic reaction is utilized to "cap" (e.g., sialylate) sites to which the modified sugar failed to conjugate.
- a chemical reaction is utilized to alter the structure ofthe conjugated modified sugar.
- the conjugated modified sugar is reacted with agents that stabilize or destabilize its linkage with the peptide component to which the modified sugar is attached.
- a component ofthe modified sugar is deprotected following its conjugation to the peptide.
- Glycosyltransferases catalyze the addition of activated sugars (donor NDP-sugars), in a step- wise fashion, to a protein, glycopeptide, lipid or glycolipid or to the non-reducing end of a growing oligosaccharide.
- N-linked glycopeptides are synthesized via a transferase and a lipid-linked oligosaccharide donor Dol-PP-NAG Glc 3 Man 9 in an en block transfer followed by trimming ofthe core. In this case the nature ofthe "core" saccharide is somewhat different from subsequent attachments.
- a very large number of glycosyltransferases are known in the art.
- glycosyltransferase to be used in the present invention may be any as long as it can utilize the modified sugar as a sugar donor.
- examples of such enzymes include Leloir
- N-acetylgalactosaminyltransferase fucosyltransferase, sialyltransferase, mannosyltransferase, xylosyltransferase, glucurononyltransferase and the like.
- glycosyltransferase For enzymatic saccharide syntheses that involve glycosyltransferase reactions, glycosyltransferase can be cloned, or isolated from any source. Many cloned glycosyltransferases are known, as are their polynucleotide sequences. See, e.g., "The WWW Guide To Cloned Glycosyltransferases," (http://www.vei.co.uk/TGN/gt guide.htm).
- Glycosyltransferase amino acid sequences and nucleotide sequences encoding glycosyltransferases from which the amino acid sequences can be deduced are also found in various publicly available databases, including GenBank, Swiss-Prot, EMBL, and others.
- Glycosyltransferases that can be employed in the methods ofthe invention include, but are not limited to, galactosyltransferases, fucosyltransferases, glucosyltransferases, N- acetylgalactosaminyltransferases, N-acetylglucosaminyltransferases, glucuronyltransferases, sialyltransferases, mannosyltransferases, glucuronic acid transferases, galacturonic acid transferases, and oligosaccharyltransferases.
- Suitable glycosyltransferases include those obtained from eukaryotes, as well as from prokaryotes.
- DNA encoding the enzyme glycosyltransferases may be obtained by chemical synthesis, by screening reverse transcripts of mRNA from appropriate cells or cell line cultures, by screening genomic libraries from appropriate cells, or by combinations of these procedures. Screening of mRNA or genomic DNA may be carried out with oligonucleotide probes generated from the glycosyltransferases gene sequence. Probes may be labeled with a detectable group such as a fluorescent group, a radioactive atom or a chemiluminescent group in accordance with known procedures and used in conventional hybridization assays.
- a detectable group such as a fluorescent group, a radioactive atom or a chemiluminescent group in accordance with known procedures and used in conventional hybridization assays.
- glycosyltransferases gene sequences may be obtained by use ofthe polymerase chain reaction (PCR) procedure, with the PCR oligonucleotide primers being produced from the glycosyltransferases gene sequence.
- PCR polymerase chain reaction
- the glycosyltransferases enzyme may be synthesized in host cells transformed with vectors containing DNA encoding the glycosyltransferases enzyme.
- a vector is a replicable DNA construct. Nectors are used either to amplify D ⁇ A encoding the glycosyltransferases enzyme and/or to express D ⁇ A which encodes the glycosyltransferases enzyme.
- An expression vector is a replicable D ⁇ A construct in which a D ⁇ A sequence encoding the ⁇ iycos ; yitra ⁇ Srer ⁇ 'es.enz riJte:: ⁇ S'''o ⁇ i@rably linked to suitable control sequences capable of effecting the expression ofthe glycosyltransferases enzyme in a suitable host.
- suitable control sequences capable of effecting the expression ofthe glycosyltransferases enzyme in a suitable host.
- control sequences include a transcriptional promoter, an optional operator sequence to control transcription, a sequence encoding suitable mRNA ribosomal binding sites, and sequences which control the termination of transcription and translation.
- Amplification vectors do not require expression control domains. All that is needed is the ability to replicate in a host, usually conferred by an origin of replication, and a selection gene to facilitate recognition of transformants. Fucosyltransferases
- a glycosyltransferase used in the method ofthe invention is a fucosyltransferase.
- Fucosyltransferases are known to those of skill in the art.
- Exemplary fuco.syltransferases include enzymes, which transfer L-fucose from GDP-fucose to a hydroxy position of an acceptor sugar.
- Fucosyltransferases that transfer non-nucleotide sugars to an acceptor are also of use in the present invention.
- the acceptor sugar is, for example, the GlcNAc in a Gal ⁇ (l— 3,4)GlcNAc ⁇ - group in an oligosaccharide glycoside.
- Suitable fucosyltransferases for this reaction include the Gal ⁇ (l ⁇ 3,4)GlcNAc ⁇ l- ⁇ (l ⁇ 3,4)fucosyltransferase (FTIII E.G. No. 2.4.1.65), which was first characterized from human milk (see, Palcic, et al, Carbohydrate Res. 190: 1-11 (1989); Prieels, et al, J. Biol. Chem. 256: 10456-10463 (1981); and Nunez, et al, Can. J. Chem.
- FTNII a sialyl ⁇ (2-> ⁇ )Gal ⁇ ((l-»3)GlcNAc ⁇ fucosyltransferase
- FTNIII a sialyl ⁇ (2-> ⁇ )Gal ⁇ ((l-»3)GlcNAc ⁇ fucosyltransferase
- a recombinant form ofthe Gal ⁇ (l— »3,4) GlcNAc ⁇ - ⁇ (l- 3,4)fucosyltransferase has also been characterized (see, Dumas, et al, Bioorg. Med.
- fucosyltransferases include, for example, ⁇ l,2 fucosyltransferase (E.C. No. 2.4.1.69). Enzymatic fucosylation can be carried out by the methods described in Mollicone, et al, Eur. J. Biochem. 191: 169-176 (1990) or U.S. Patent No. 5,374,655. Cells that are used to produce a fucosyltransferase will also include an enzymatic system for synthesizing GDP-fucose. C aBsylfa sflr kes ' ,'
- the glycosyltransferase is a galactosyltransferase.
- exemplary galactosyltransferases include ⁇ (l,3) galactosyltransferases (E.C. No. 2.4.1.151, see, e.g., Dabkowski et al, Transplant Proc. 25:2921 (1993) and Yamamoto et al Nature 345: 229-233 (1990), bovine (GenBank J04989, Joziasse et al, J. Biol. Chem. 264: 14290- 14297 (1989)), murine (GenBank m26925; Larsen et al, Proc. N t 7. Acad. Sci.
- porcine GenBank L36152; Strahan et al, Immunogenetics 41: 101-105 (1995)
- Another suitable ⁇ l,3 galactosyltransferase is that which is involved in synthesis of the blood group B antigen (EC 2.4.1.37, Yamamoto et al, J. Biol. Chem. 265: 1146-1151 (1990) (human)).
- ⁇ (l,4) galactosyltransferases which include, for example, EC 2.4.1.90 (Lac ⁇ Ac synthetase) and EC 2.4.1.22 (lactose synthetase) (bovine (D'Agostaro et al, Eur. J. Biochem. 183: 211-217 (1989)), human (Masri et al, Biochem. Biophys. Res. Commun. 157: 657-663 (1988)), murine ( ⁇ akazawa et al, J. Biochem. 104: 165-168 (1988)), as well as E.C.
- GalNAc Ti ⁇ v The production of proteins such as the enzyme GalNAc Ti ⁇ v from cloned genes by genetic engineering is well known. See, eg., U.S. Pat. No. 4,761,371.
- One method involves collection of sufficient samples, then the amino acid sequence ofthe enzyme is determined by N-terminal sequencing. This information is then used to isolate a cDNA clone encoding a full-length (membrane bound) transferase which upon expression in the insect cell line Sf9 resulted in the synthesis of a fully active enzyme. The acceptor specificity ofthe enzyme is then determined using a semiquantitative analysis ofthe amino acids surrounding known glycosylation sites in 16 different proteins followed by in vitro glycosylation studies of synthetic peptides.
- Sialyltransferases are another type of glycosyltransferase that is useful in the recombinant cells and reaction mixtures ofthe invention. Cells that produce recombinant sialyltransferases will also produce CMP-sialic acid, which is a sialic acid donor for sialyltransferases.
- ST3Gal III e.g., a rat or human ST3Gal III
- ST3Gal IN ST3Gal I, ST6Gal I, ST3Gal N, ST6Gal II, ST6Gal ⁇ Ac I, ST6GalNAc II, and ST6GalNAc III
- ST3Gal III e.g., a rat or human ST3Gal III
- ⁇ (2,3)sialyltransferase (EC 2.4.99.6) transfers sialic acid to the non-reducing terminal Gal of a Gal ⁇ l— 3Glc disaccharide or glycoside.
- ⁇ (2,3)sialyltransferase (EC 2.4.99.6) transfers sialic acid to the non-reducing terminal Gal of a Gal ⁇ l— 3Glc disaccharide or glycoside.
- Another exemplary ⁇ 2,3-sialyltransferase (EC 2.4.99.4) transfers sialic acid to the non-reducing terminal Gal ofthe disaccharide or glycoside. see, Rearick et al, J. Biol. Chem. 254: 4444 (1979) and Gillespie et al, J. Biol. Chem. 267: 21004 (1992).
- Further exemplary enzymes include Gal- ⁇ -l,4-Glc ⁇ Ac ⁇ -2,6 sialyltransferase (See, Kurosawa et al. Eur. J. Biochem. 219: 375-381 (1994)).
- the sialyltransferase will be able to transfer sialic acid to the sequence Gal ⁇ l,4GlcNAc-, the most common penultimate sequence underlying the terminal sialic acid on fully sialylated carbohydrate structures (see, Table 3).
- ⁇ iaeBa'SUUSSWft ri.sc use the Gal ⁇ l,4GlcNAc sequence as an acceptor substrate
- sialyltransferase that is useful in the claimed methods is ST3Gal III, which is also referred to as ⁇ (2,3)sialyltransferase (EC 2.4.99.6).
- This enzyme catalyzes the transfer of sialic acid to the Gal of a Gal ⁇ 1,3 GlcNAc or Gal ⁇ l,4GlcNAc glycoside (see, e.g., Wen et al, J. Biol. Chem. 267: 21011 (1992); Van den Eijnden et al, J. Biol. Chem. 256: 3159 (1991)) and is responsible for sialylation of asparagine-linked oligosaccharides in glycopeptides.
- the sialic acid is linked to a Gal with the formation of an ⁇ -linkage between the two saccharides. Bonding (linkage) between the saccharides is between the 2-position of NeuAc and the 3-position of Gal.
- This particular enzyme can be isolated from rat liver
- sialyltransferases of use in the present invention include those isolated from Campylobacter jejuni, including the ⁇ (2,3). See, e.g, WO99/49051.
- Sialyltransferases other than those listed in Table 3, are also useful in an economic and efficient large-scale process for sialylation of commercially important glycopeptides.
- various amounts of each enzyme with asialo- ⁇ i AGP at 1-10 mg/ml to compare the ability ofthe sialyltransferase of interest to sialylate glycopeptides relative to either bovine ST6Gal I, ST3Gal III or both sialyltransferases.
- glycopeptides or glycopeptides, or N-linked oligosaccharides enzymatically released from the peptide backbone can be used in place of asialo-cti AGP for this evaluation.
- Sialyltransferases with the ability to sialylate N-linked oligosaccharides of glycopeptides more efficiently than ST6Gal I are useful in a practical large-scale process for peptide sialylation (as illustrated for ST3Gal III in this disclosure).
- glycosyltransferases can be substituted into similar transferase cycles as have been described in detail for the sialyltransferase.
- the glycosyltransferase can also be, for instance, glucosyltransferases, e.g., Alg8 (Stagljov et al, Proc. Natl. Acad. Sci. USA 91: 5977 (1994)) or Alg5 (Heesen et al, Eur. J. Biochem. 224: 71 (1994)).
- N-acetylgalactosaminylrransferases are also of use in practicing the present invention.
- Suitable N-acetylgalactosaminyltransferases include, but are not limited to, ⁇ (l,3) N-acetylgalactosaminyltransferase, ⁇ (l,4) N-acetylgalactosaminyltransferases (Nagata et al, J. Biol. Chem. 267: 12082-12089 (1992) and Smith et al, J. Biol Chem.
- N-acetylgalactosaminyltransferase Suitable N-acetylglucosaminyltransferases include GnTI (2.4.1.101, Hull et al, BBRC 176: 608 (1991)), GnTII, GnTIII (Ihara et al, J. Biochem. 113: 692 (1993)), GnTIV, and GnTV (Shoreiban et al, J. Biol. Chem.
- Mannosyltransferases are of use to transfer modified mannose moieties. Suitable mannosyltransferases include ⁇ (l,2) mannosyltransferase, ⁇ (l,3) mannosyltransferase, ⁇ (l,6) mannosyltransferase, ⁇ (l,4) mannosyltransferase, Dol-P-Man synthase, OChl, and Pmtl (see, Kornfeld et al, Annu. Rev. Biochem. 54: 631-664 (1985)).
- Xylosyl transferases are also useful in the present invention. See, for example, Rodgers, et al, Biochem.
- Prokaryotic glycosyltransferases are also useful in practicing the invention.
- Such glycosyltransferases include enzymes involved in synthesis of lipooligosaccharides (LOS), which are produced by many gram negative bacteria.
- the LOS typically have terminal glycan sequences that mimic glycoconjugates found on the surface of human epithelial cells or in host secretions (Preston et al, Critical Reviews in Microbiology 23(3): 139-180 (1996)).
- Such enzymes include, but are not limited to, the proteins ofthe rfa operons of species such as E.
- Salmonella typhimurium which include a ⁇ l,6 galactosyltransferase and a ⁇ l,3 galactosyltransferase (see, e.g., EMBL Accession Nos. M80599 and M86935 (E. coli); ⁇ MBL Accession No. S56361 (S. typhimurium)), a glucosyltransferase (Swiss-Prot Accession No. P25740 (E. coli), an ⁇ l,2-glucosyltransferase (r/ ⁇ J)(Swiss-Prot Accession No. P27129 (E. coli) and Swiss-Prot Accession No.
- glycosyltransferases for which amino acid sequences are known include those that are encoded by operons such as rfaB, which have been characterized in organisms such as Klebsiella pneumoniae, E. coli, Salmonella typhimurium, Salmonella enterica, Yersinia enter ocolitica, Mycobaderium leprosum, and the rhl operon of Pseudomonas aeruginosa.
- glycosyltransferases that are involved in producing structures containing lacto-N-neotetraose, D-galactosyl- ⁇ -l,4-N- acetyl-D-glucosaminyl- ⁇ -l,3-D-galactosyl- ⁇ -l,4-D-glucose, and the P k blood group trisaccharide sequence, D-galactosyl- ⁇ -l,4-D-galactosyl- ⁇ -l,4-D-glucose, which have been identified in the LOS ofthe mucosal pathogens Neisseria gonnorhoeae and N.
- N. meningitidis (Scholten et al, J. Med. Microbiol 41: 236-243 (1994)).
- the genes from N. meningitidis and N. gonorrhoeae that encode the glycosyltransferases involved in the biosynthesis of these structures have been identified from N. meningitidis immunotypes L3 and LI (Jennings et al, Mol Microbiol. 18: 729-740 (1995)) and the N. gonorrhoeae mutant F62 (Gotshlich, J. Exp. Med. 180: 2181-2190 (1994)).
- N. meningitidis immunotypes L3 and LI Jennings et al, Mol Microbiol. 18: 729-740 (1995)
- N. gonorrhoeae mutant F62 (Gotshlich, J. Exp. Med. 180: 2181-2190 (1994)).
- meningitidis a locus consisting of three genes, IgtA, IgtB and Ig E, encodes the glycosyltransferase enzymes required for addition ofthe last three ofthe sugars in the lacto-N-neotetraose chain (Wakarchuk et al, J. Biol. Chem. 271: 19166- 73 (1996)). Recently the enzymatic activity ofthe IgtB and IgtA gene product was demonstrated, providing the first direct evidence for their proposed glycosyltransferase 271(45): 28271-276 (1996)). In N.
- IgtD which adds ⁇ -D-Gal ⁇ Ac to the 3 position ofthe terminal galactose ofthe lacto-N-neotetraose structure
- IgtC which adds a terminal ⁇ -D-Gal to the lactose element of a truncated LOS, thus creating the P k blood group antigen structure (Gotshlich (1994), supra.).
- a separate immunotype LI also expresses the P k blood group antigen and has been shown to carry an IgtC gene (Jennings et al, (1995), supra.).
- Neisseria glycosyltransferases and associated genes are also described in USP ⁇ 5,545,553 (Gotschlich). Genes for ⁇ l,2-fucosyltransferase and ⁇ 1,3 -fucosyltransferase from Helicobader pylori has also been characterized (Martin et al, J. Biol. Chem. 272: 21349- 21356 (1997)). Also of use in the present invention are the glycosyltransferases of
- Campylobacter jejuni see, for example, http://afrnb.cnrs-rnrs.fr/ ⁇ pedro/CAZY/gtf_42.html).
- the invention also provides methods for producing peptides that include sulfated molecules, including, for example sulfated polysaccharides such as heparin, heparan sulfate, carragenen, and related compounds.
- Suitable sulfotransferases include, for example, chondroitin-6-sulphotransferase (chicken cD ⁇ A described by Fukuta et al, J. Biol. Chem. 270: 18575-18580 (1995); GenBank Accession No.
- glycosaminoglycan N- acetylglucosamine N-deacetylase/N-sulphotransferase 1 (Dixon et ⁇ /., Genomics 26: 239-241 (1995); UL18918), and glycosaminoglycan N-acetylglucosamine N-deacetylase/N- sulphotransferase 2 (murine cDNA described in Orellana et al, J. Biol. Chem. 269: 2270- 2276 (1994) and Eriksson et al, J. Biol. Chem. 269: 10438-10443 (1994); human cDNA described in GenBank Accession No. U2304).
- the enzymes utilized in the method ofthe invention are cell-bound glycosyltransferases. Although many soluble glycosyltransferases are known
- glycosyltransferases are generally in membrane- bound form when associated with cells. Many ofthe membrane-bound enzymes studied thus far are considered to be intrinsic proteins; that is, they are not released from the membranes by sonication and require detergents for solubilization. Surface glycosyltransferases have been identified on the surfaces of vertebrate and invertebrate cells, and it has also been recognized that these surface transferases maintain catalytic activity under physiological conditions.
- ⁇ .-D- galactosyl-l,4-N-acetyl-D-glucosaminide ⁇ -l,3-galactosyltransferase was transfected into COS-1 cells. The transfected cells were then cultured and assayed for ⁇ 1-3 galactosyltransferase activity.
- the methods ofthe invention utilize fusion proteins that have more than one enzymatic activity that is involved in synthesis of a desired glycopeptide conjugate.
- the fusion polypeptides can be composed of, for example, a catalytically active domain of a glycosyltransferase that is joined to a catalytically active domain of an accessory enzyme.
- the accessory enzyme catalytic domain can, for example, catalyze a step in the formation of a nucleotide sugar that is a donor for the glycosyltransferase, or catalyze a reaction involved in a glycosyltransferase cycle.
- a polynucleotide that encodes a glycosyltransferase can be joined, in-frame, to a polynucleotide that encodes an enzyme involved in nucleotide sugar synthesis.
- the resulting fusion protein can then catalyze not only the synthesis ofthe nucleotide sugar, but also the transfer ofthe sugar moiety to the acceptor molecule.
- the fusion protein can be two or more cycle enzymes linked into one expressible nucleotide sequence.
- the fusion protein includes the catalytically active domains of two or more glycosyltransferases. See, for example, 5,641,668.
- modified glycopeptides ofthe present invention can be ffe ⁇ d ⁇ lf de i ne IWd'nitriyifffifirel' utilizing various suitable fusion proteins (see, for example, PCT Patent Application PCT/CA98/01180, which was published as WO 99/31224 on June 24, 1999.)
- the present invention also provides for the use of enzymes that are immobilized on a solid and/or soluble support.
- a glycosyltransferase that is conjugated to a PEG via an intact glycosyl linker according to the methods of the invention.
- the PEG-linker-enzyme conjugate is optionally attached to solid support.
- solid supported enzymes in the methods of the invention simplifies the work up ofthe reaction mixture and purification ofthe reaction product, and also enables the facile recovery ofthe enzyme.
- the glycosyltransferase conjugate is utilized in the methods ofthe invention. Other combinations of enzymes and supports will be apparent to those of skill in the art.
- Glycosylation of a mutant human growth hormone may also be accomplished intracellularly by recombinant means.
- a polynucleotide sequence encoding a mutant human growth hormone, which comprises at least one newly introduced N- or O-linked glycosylation site may be transfected into a suitable host cell line, e.g., a eukaryotic cell line derived from yeast, insect, or mammalian origin.
- the mutant human growth hormone recombinantly produced from such a cell line is glycosylated by the host cell glycosylation machinery.
- glycosylated human growth hormone produced by the above processes is preferably purified before use.
- Standard, well known techniques such as thin or thick layer chromatography, column chromatography, ion exchange chromatography, or membrane filtration can be used. It is preferred to use membrane filtration, more preferably utilizing a reverse osmotic membrane, or one or more column chromatographic techniques for the recovery as is discussed hereinafter and in the literature cited herein.
- the particulate debris either host cells or lysed fragments
- the protein may be concentrated with a followed by separating the polypeptide variant from other impurities by one or more steps selected from immunoaffinity chromatography, ion-exchange column fractionation (e.g., on diethylaminoethyl (DEAE) or matrices containing carboxymethyl or sulfopropyl groups), chromatography on Blue- Sepharose, CM Blue-Sepharose, MONO-Q, MONO-S, lentil lectin-Sepharose, WGA- Sepharose, Con A-Sepharose, Ether Toyopearl, Butyl Toyopearl, Phenyl Toyopearl, SP- Sepharose, or protein A Sepharose, SDS-PAGE chromatography, si
- a glycosylated mutant human growth hormone produced in culture is usually isolated by initial extraction from cells, cell lysate, culture media, etc., followed by one or more concentration, salting-out, aqueous ion-exchange, or size-exclusion chromatography steps. Additionally, the glycoprotein may be purified by affinity chromatography. Finally, HPLC may be employed for final purification steps.
- a protease inhibitor e.g., methylsulfonylfluoride (PMSF) may be included in any of the foregoing steps to inhibit proteolysis and antibiotics may be included to prevent the growth of adventitious contaminants.
- PMSF methylsulfonylfluoride
- supernatants from systems that produce the glycosylated human growth hormone ofthe invention are first concentrated using a commercially available protein concentration filter, for example, an Amicon or Millipore Pellicon ultrafiltration unit. Following the concentration step, the concentrate may be applied to a suitable purification matrix.
- a suitable affinity matrix may comprise a ligand for the peptide, a lectin or antibody molecule bound to a suitable support.
- an anion-exchange resin may be employed, for example, a matrix or substrate having pendant DEAE groups.
- Suitable matrices include acrylamide, agarose, dextran, cellulose, or other types commonly employed in protein purification.
- a cation-exchange step may be employed.
- Suitable cation exchangers include various insoluble matrices comprising sulfopropyl or carboxymethyl groups. Sulfopropyl groups are particularly preferred.
- one or more RP-HPLC steps employing hydrophobic RP-HPLC media, e.g., silica gel having pendant methyl or other aliphatic groups, may be employed to further purify ⁇ gtM ' ft ⁇ hormone.
- hydrophobic RP-HPLC media e.g., silica gel having pendant methyl or other aliphatic groups.
- glycosylated mutant human growth hormone ofthe invention resulting from a large-scale fermentation may be purified by methods analogous to those disclosed by Urdal et al, J. Chromatog. 296: 171 (1984).
- This reference describes two sequential, RP-HPLC steps for purification of recombinant human IL-2 on a preparative HPLC column.
- techniques such as affinity chromatography, may be utilized to purify the glycoprotein.
- the biological functions ofthe glycoprotein are tested using several methods known in the art.
- the functional assays are based on various characteristics of human growth hormone, such as its specific binding to human growth hormone receptor, activation ofthe hGH receptor, and its activity in promoting cell growth. In each assay, wild- type human growth hormone is included as a positive control.
- a radioreceptor binding assay can be carried out to measure the binding between a radio-labeled hGH receptor and a mutant human growth hormone ofthe present invention. Detailed description for such an assay can be found in the literature, e.g., Tsushima et al, J. Clin.
- the animals are sacrificed on the sixth day, their foreleg knee bones taken out and the width ofthe epiphyseal plates measured.
- the weight of these rats at the start ofthe experiment and before being sacrificed is also monitored and compared among different groups receiving daily injections ofthe mutant human growth hormone at different concentrations.
- a mutant human growth hormone can be demonstrated in its ability to cause hGH-dependent tyrosine phosphorylation in IM-9 cells, which are derived from a clone of human lymphoblastoma and express human growth hormone receptor on the cell surface.
- MB-2 cells may also be sfittfbli ',, f tl
- the ' level of tyrosine phosphorylation of cellular proteins upon exposure to the mutant human growth hormone is shown by a monoclonal antibody against phosphorylated tyrosine, as described by Silva et al, Endocrinology, 132: 101 (1993) and U.S. Patent No. 6,238,915.
- the glycosylated mutant human growth hormone having desired oligosaccharide determinants described above can be used as therapeutics for treating a variety of diseases and conditions related to deficiency in growth hormone.
- Growth-related conditions that can be treated with the mutant human growth hormone ofthe present invention include: dwarfism, short-stature in children and adults, cachexia/muscle wasting, general muscular atrophy, and sex chromosome abnormality (e.g., Turner's Syndrome).
- mutant hGH ofthe present invention Other conditions may be treated using the mutant hGH ofthe present invention include: short-bowel syndrome, lipodystrophy, osteoporosis, uraemaia, burns, female infertility, bone regeneration, general diabetes, type II diabetes, osteo-arthritis, chronic obstructive pulmonary disease (COPD), and insomia.
- the mutant hGH ofthe invention may also be used to promote various healing processes, e.g., general tissue regeneration, bone regeneration, and wound healing, or as a vaccine adjunct.
- the present invention also provides pharmaceutical compositions comprising an effective amount of glycosylated mutant human growth hormone, which is produced according to the methods described above.
- Pharmaceutical compositions ofthe invention are suitable for use in a variety of drug delivery systems.
- compositions for use in the present invention are found in Remington's Pharmaceutical Sciences, Mack Publishing Company, Philadelphia, PA, 17th ed. (1985). For a brief review of methods for drug delivery, see, Langer, Science 249: 1527- 1533 (1990).
- the pharmaceutical compositions are intended for parenteral, intranasal, topical, oral, or local administration, such as by subcutaneous injection, aerosol inhalation, or transdermal adsorption, for prophylactic and/or therapeutic treatment. Commonly, the pharmaceutical compositions are administered parenterally, e.g., subcutaneously or intravenously.
- compositions for parenteral administration which comprise the glycosylated mutant human growth hormone dissolved or suspended in an acceptable carrier, preferably an aqueous carrier, e.g., water, buffered water, saline, PBS and the like.
- an acceptable carrier preferably an aqueous carrier, e.g., water, buffered water, saline, PBS and the like.
- the compositions may also contain detergents such as Tween 20 and Tween 80; sM ⁇ ize ''s e ⁇ ; ⁇ «fc ⁇ itii ⁇ ''fe'®r 'M
- compositions may contain pharmaceutically acceptable auxiliary substances as required to approximate physiological conditions, such as pH adjusting and buffering agents, tonicity adjusting agents, wetting agents, detergents and the like.
- auxiliary substances such as pH adjusting and buffering agents, tonicity adjusting agents, wetting agents, detergents and the like.
- These compositions may be sterilized by conventional sterilization techniques, or may be sterile filtered.
- the resulting aqueous solutions may be packaged for use as is, or lyophilized, the lyophilized preparation being combined with a sterile aqueous carrier prior to administration.
- the pH ofthe preparations typically will be between 3 and 11, more preferably from 5 to 9, and most preferably from 7 and 8.
- the compositions containing the glycosylated mutant human growth hormone can be administered for prophylactic and/or therapeutic treatments.
- compositions are administered to a patient already suffering from a disease or condition related to growth hormone deficiency, in an amount sufficient to cure or at least partially arrest the symptoms ofthe disease and its complications.
- An amount adequate to accomplish this is defined as a "therapeutically effective dose.” Amounts effective for this use will depend on the severity ofthe disease or condition and the weight and general state ofthe patient, but generally range from about 0.1 mg to about 2,000 mg of glycosylated mutant human growth hormone per day for a 70 kg patient, with dosages of from about 5 mg to about 200 mg ofthe compounds per day being more commonly used.
- compositions containing the glycosylated mutant human growth hormone ofthe invention are administered to a patient susceptible to or otherwise at risk of a particular disease.
- Such an amount is defined to be a “prophylactically effective dose.”
- the precise amounts again depend on the patient's state of health and weight, but generally range from about 0.1 mg to about 1,000 mg per 70 kilogram patient, more commonly from about 5 mg to about 200 mg per 70 kg of body weight.
- compositions can be carried out with dose levels and pattern being selected by the treating physician.
- pharmaceutical formulations should provide a quantity ofthe glycosylated mutant human growth hormone of this invention sufficient to effectively treat the patient.
- Human growth hormone occurs in a variety of different isoforms and different amino acid sequences.
- the two best characterized forms include placental derived hGH, which is also known as GH-N (PDB P01242) and pituitary derived hGH, which is also known as somatotropin or GH- ⁇ (P01241); see Figure 1.
- the pituitary derived hGH is not glycosylated and is produced in Escherichia coli as a therapeutic.
- the placental derived hGH (GH-N) has one ⁇ -glycosylation site at amino acid 140 (see Table 4 and FIG. 1, see arrow).
- the pituitary derived hGH (GH-N) can be modified at amino acid position 140 to introduce an N-linked glycosylation site by mutating the nucleotide sequence encoding this polypeptide so that instead of encoding the wild-type lysine (abbreviated as "k” at amino acid 140 ofthe GH-N polypeptide sequence in Table 5 and FIG. 1, see arrow), the nucleotide sequence will encode an asparagine (abbreviated "n") at amino acid position 140 of GH-N (see also FIG. 2).
- This mutated pituitary derived hGH can then be glycosylated or glycoconjugated (see WO 03/31464, inco ⁇ orated herein by reference).
- the mutated pituitary derived hGH is glycoPEGylated, wherein a polyethylene glycol (PEG) moiety is conjugated to the mutated pituitary derived hGH polypeptide via a glycosyl linkage (see WO 03/31464, incorporated herein by reference).
- FIG.3 describes the GlycoPEGylation of an hGH N-linked glycan mutant produced in either Sf9 insect cells or mammalian cells.
- GlycoPEGylation ofthe mibtitedi iM idMvedllh ⁇ H-Sfeei ected to result in improved biophysical properties that may include but are not limited to improved half-life, improved area under the curve (AUC) values, reduced clearance, and reduced immunogenicity.
- Example 2 An alternative approach is to create an O-linked glycosylation site into the pituitary derived hGH polypeptide.
- This O-linked glycosylation site may then be used as a site on which the mutated hGH polypeptide can be glycoPEGylated using a GalNAcT 2 enzyme or the like.
- One or more additional transferases may then be used to add glycans or glycoconjugates to that site.
- the mutated pituitary derived hGH polypeptide is glycoPEGylated.
- FIG.4 describes the glycoPEGylation of an hGH O-linked glycan mutant produced in Escherichia coli.
- the protein loop regions on pituitary derived hGH are best suited for mutation to introduce a glycosylation site (FIG. 5).
- the nucleotide sequence that encodes amino acids 1-6 FPTIPL; SEQ ID NO: 10
- amino acids 48-52 PQTSL; SEQ ID NO: 11
- amino acids 59-64 PTPSNR; SEQ ID NO: 12
- amino acids 133-139 PRTGQIF; SEQ ID NO: 13
- amino acids 133-145 PRTGQIFKQTYSK
- SEQ ID NO: 14 amino acids 139-142
- FKQT SEQ ID NO: 15
- FIG. 6 illustrates six (6) of these introduced O-linked glycosylation sites.
- the arrows in Figure 6 each represent the threonine residue on which O-linked glycosylation will occur in the GH-N O-linked glycan hGH mutant.
- FIG. 7 and FIG. 8 each illustrates two additional GH-N O-linked glycan hGH mutants.
- This example describes amino acid sequence mutations introducing O-linked glycosylation sites, i.e., serine or threonine residues, into a preferably proline-containing site of a wild- type human growth hormone sequence or any modified version thereof.
- N-terminus of a wild-type hGH, FP 2 TIP 5 LS; SEQ ID NO: 16 is replaced with either MXnTP 2 TIP 5 LS or MAPTSSXnP 2 TIP 5 LS.
- Preferred examples include:
- MQTPTIPLS MQTPTIPLS; SEQ ID NO: 18 MAPTSSPTIPLS; SEQ ID NO: 19 MAPTSSSPTIPLS (IL-2 N-terminus); SEQ ID NO:20 MPTTFPTIPLS; SEQ ID NO:21 MPTSSPTIPLS; SEQ ID NO:22
- mutants the N-terminus of a wild-type hGH, FP 2 TIP 5 LS; SEQ ID NO:24, is replaced with ZmP 2 T XnBoP 5 LS.
- Preferred mutations include:
- MFPTSIPLS SEQ ID NO:26 MFPTSSPLS; SEQ ID NO:27 MTPTQIPLS; SEQ ID NO:28 MFPTTTPLS; SEQ ID NO:29
- ammo acid sequence surrounding P AYIP KEQKY; SEQ ID NO:30
- AZmJqP 37 OrXnBo ⁇ pY where at least one of Z, J, O, X, and B is independently selected from either Thr or Ser;
- ⁇ may include Lys (K) and
- X may be Asp (D).
- Preferred examples include:
- amino acid sequence surrounding P 48 , LQNP 48 QTSLC; SEQ ID NO:35 is replaced with LZmJqP 48 OrXnBoLC, where at least one of Z, J, O, and X are independently selected from either Thr or Ser.
- Preferred examples include:
- amino acid sequence surrounding P 59 SESIP 59 TPNREET; SEQ ID NO:38, is replaced with SZmUsJqP 59 TPOrXnBo ⁇ rT, where at least one of Z, J, O, B, ⁇ , U, and X is independently selected from either Thr or Ser; B, ⁇ , and Z may include charged amino acids.
- Preferred examples include:
- Preferred examples include:
- SWLEP 89 TQGLRS SEQ ID NO:49 SWLEP 89 TQGATS; SEQ ID NO:50 SSQTP 89 NQFLRS; SEQ ID ⁇ O:51 SWLEP 89 TSSLSS; SEQ ID NO:52 SMVTP 89 VQFLRS; SEQ ID NO:53 7 Intdmal i iMttyibn,Sife»
- EDGSP 133 TNGQIF EDGSP 133 TNGQIF
- SEQ ID ⁇ O:58 EDGSP 133 TTTQIF
- SEQ ID NO:59 EDGSP 133 TNGQIF
- amino acid sequence surrounding P 140 GQIFK 140 QTYS; SEQ ID NO:65, is replace with GZmUsJq ⁇ r 140 OrXnBoS, where at least one of Z, U, J, O, B, and X is independently selected from either Thr or Ser.
- Preferred examples include:
- GQIFT 140 QTYS; SEQ ID NO:71 GQIST 140 QTYS; SEQ ID NO:72 GQIPT 140 TTYS; SEQ ID NO:73
- NEGSCGPTTTP SEQ ID ⁇ O:75 VEGSCGPTSSP; SEQ ID NO:76 VEGSCGPTQGAMP; SEQ ID NO:77
- VEGSCGPTTIP SEQ ID NO:78 NEGSCGPMVTP; SEQ ID ⁇ O:79
- X, Z, B, ⁇ , J, U, O, and ⁇ are independently selected from E (glutamate), any uncharged amino acid or dipeptide combination including M, F, MF, and the like; m, n, o, p, q, r, s, and t are independently selected from integers from 0 to 3.
- the N-terminal Met may be present or absent on any hGH mutant.
- the numbering of the amino acid residues is based on the initial unmodified sequence in which the left most residue is numbered 1. The numbering of unmodified amino acids remains unchanged following the modification. More than one ofthe above described sequence modifications may be present in a hGH mutant ofthe present invention.
Abstract
Description






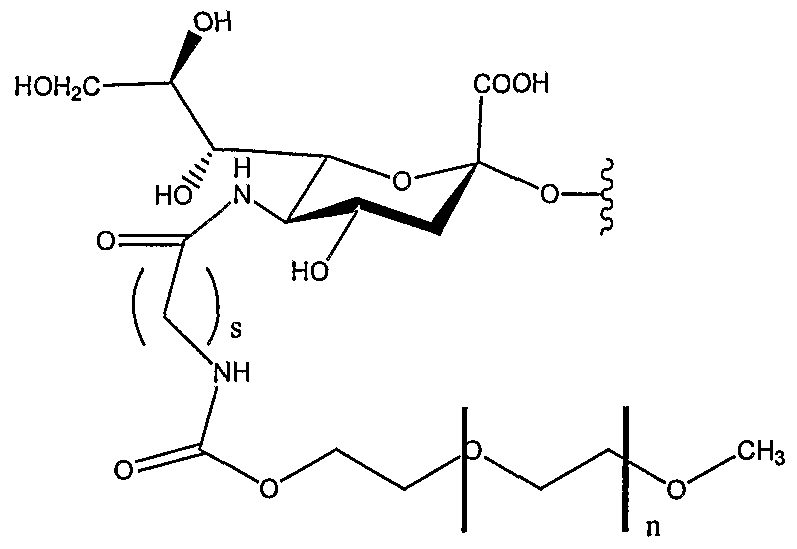














Claims
Priority Applications (9)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| MXPA05011832A MXPA05011832A (en) | 2003-05-09 | 2004-05-07 | Compositions and methods for the preparation of human growth hormone glycosylation mutants. |
| US10/556,094 US7932364B2 (en) | 2003-05-09 | 2004-05-07 | Compositions and methods for the preparation of human growth hormone glycosylation mutants |
| BRPI0410164-2A BRPI0410164A (en) | 2003-05-09 | 2004-05-07 | compositions and methods for preparing human growth hormone glycosylation mutants |
| EP04751591A EP1624847B1 (en) | 2003-05-09 | 2004-05-07 | Compositions and methods for the preparation of human growth hormone glycosylation mutants |
| CA002524936A CA2524936A1 (en) | 2003-05-09 | 2004-05-07 | Compositions and methods for the preparation of human growth hormone glycosylation mutants |
| AU2004240553A AU2004240553A1 (en) | 2003-05-09 | 2004-05-07 | Compositions and methods for the preparation of human growth hormone glycosylation mutants |
| AT04751591T ATE540055T1 (en) | 2003-05-09 | 2004-05-07 | COMPOSITIONS AND METHODS FOR PRODUCING HUMAN GROWTH HORMONE GLYCOSYLATION MUTANTS |
| ES04751591T ES2380093T3 (en) | 2003-05-09 | 2004-05-07 | Compositions and methods for the preparation of human growth hormone glycosylation mutants |
| JP2006532844A JP2007523630A (en) | 2003-05-09 | 2004-05-07 | Composition and formulation of human growth hormone glycosylation mutants |
Applications Claiming Priority (8)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US46911403P | 2003-05-09 | 2003-05-09 | |
| US60/469,114 | 2003-05-09 | ||
| US49475103P | 2003-08-13 | 2003-08-13 | |
| US60/494,751 | 2003-08-13 | ||
| US49507603P | 2003-08-14 | 2003-08-14 | |
| US60/495,076 | 2003-08-14 | ||
| US53529004P | 2004-01-08 | 2004-01-08 | |
| US60/535,290 | 2004-01-08 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| WO2004103275A2 true WO2004103275A2 (en) | 2004-12-02 |
| WO2004103275A3 WO2004103275A3 (en) | 2007-05-18 |
Family
ID=33479814
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2004/014254 WO2004103275A2 (en) | 2003-05-09 | 2004-05-07 | Compositions and methods for the preparation of human growth hormone glycosylation mutants |
Country Status (11)
| Country | Link |
|---|---|
| US (1) | US7932364B2 (en) |
| EP (1) | EP1624847B1 (en) |
| JP (1) | JP2007523630A (en) |
| KR (1) | KR20060030023A (en) |
| AT (1) | ATE540055T1 (en) |
| AU (1) | AU2004240553A1 (en) |
| BR (1) | BRPI0410164A (en) |
| CA (1) | CA2524936A1 (en) |
| ES (1) | ES2380093T3 (en) |
| MX (1) | MXPA05011832A (en) |
| WO (1) | WO2004103275A2 (en) |
Cited By (37)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007521807A (en) * | 2004-01-14 | 2007-08-09 | オハイオ ユニバーシティ | Method for producing peptides / proteins in plants and peptides / proteins produced thereby |
| WO2007120932A2 (en) | 2006-04-19 | 2007-10-25 | Neose Technologies, Inc. | Expression of o-glycosylated therapeutic proteins in prokaryotic microorganisms |
| WO2006121569A3 (en) * | 2005-04-08 | 2008-11-20 | Neose Technologies Inc | Compositions and methods for the preparation of protease resistant human growth hormone glycosylation mutants |
| JP2008542285A (en) * | 2005-05-25 | 2008-11-27 | ネオス テクノロジーズ インコーポレイテッド | Glycopegylated factor IX |
| EP2049144A2 (en) * | 2006-07-21 | 2009-04-22 | Neose Technologies, Inc. | Glycosylation of peptides via o-linked glycosylation sequences |
| WO2009156511A2 (en) * | 2008-06-27 | 2009-12-30 | Novo Nordisk A/S | N-glycosylated human growth hormone with prolonged circulatory half-life |
| US7696163B2 (en) | 2001-10-10 | 2010-04-13 | Novo Nordisk A/S | Erythropoietin: remodeling and glycoconjugation of erythropoietin |
| US7795210B2 (en) | 2001-10-10 | 2010-09-14 | Novo Nordisk A/S | Protein remodeling methods and proteins/peptides produced by the methods |
| US7803777B2 (en) | 2003-03-14 | 2010-09-28 | Biogenerix Ag | Branched water-soluble polymers and their conjugates |
| US7842661B2 (en) | 2003-11-24 | 2010-11-30 | Novo Nordisk A/S | Glycopegylated erythropoietin formulations |
| JP2011512121A (en) * | 2008-01-08 | 2011-04-21 | バイオジェネリックス アーゲー | Glycoconjugation of polypeptides using oligosaccharyltransferase |
| US7932364B2 (en) | 2003-05-09 | 2011-04-26 | Novo Nordisk A/S | Compositions and methods for the preparation of human growth hormone glycosylation mutants |
| US7956032B2 (en) | 2003-12-03 | 2011-06-07 | Novo Nordisk A/S | Glycopegylated granulocyte colony stimulating factor |
| US8043833B2 (en) | 2005-10-31 | 2011-10-25 | Novo Nordisk A/S | Expression of soluble therapeutic proteins |
| US8063015B2 (en) | 2003-04-09 | 2011-11-22 | Novo Nordisk A/S | Glycopegylation methods and proteins/peptides produced by the methods |
| US8076292B2 (en) | 2001-10-10 | 2011-12-13 | Novo Nordisk A/S | Factor VIII: remodeling and glycoconjugation of factor VIII |
| US8207112B2 (en) | 2007-08-29 | 2012-06-26 | Biogenerix Ag | Liquid formulation of G-CSF conjugate |
| US8268967B2 (en) | 2004-09-10 | 2012-09-18 | Novo Nordisk A/S | Glycopegylated interferon α |
| US8361961B2 (en) | 2004-01-08 | 2013-01-29 | Biogenerix Ag | O-linked glycosylation of peptides |
| US8563687B2 (en) | 1997-07-21 | 2013-10-22 | Ohio University | Synthetic genes for plant gums and other hydroxyproline rich glycoproteins |
| US8633157B2 (en) | 2003-11-24 | 2014-01-21 | Novo Nordisk A/S | Glycopegylated erythropoietin |
| US8632770B2 (en) | 2003-12-03 | 2014-01-21 | Novo Nordisk A/S | Glycopegylated factor IX |
| US8716239B2 (en) | 2001-10-10 | 2014-05-06 | Novo Nordisk A/S | Granulocyte colony stimulating factor: remodeling and glycoconjugation G-CSF |
| US8716240B2 (en) | 2001-10-10 | 2014-05-06 | Novo Nordisk A/S | Erythropoietin: remodeling and glycoconjugation of erythropoietin |
| US8791066B2 (en) | 2004-07-13 | 2014-07-29 | Novo Nordisk A/S | Branched PEG remodeling and glycosylation of glucagon-like peptide-1 [GLP-1] |
| US8791070B2 (en) | 2003-04-09 | 2014-07-29 | Novo Nordisk A/S | Glycopegylated factor IX |
| US8841439B2 (en) | 2005-11-03 | 2014-09-23 | Novo Nordisk A/S | Nucleotide sugar purification using membranes |
| US8911967B2 (en) | 2005-08-19 | 2014-12-16 | Novo Nordisk A/S | One pot desialylation and glycopegylation of therapeutic peptides |
| US8916360B2 (en) | 2003-11-24 | 2014-12-23 | Novo Nordisk A/S | Glycopegylated erythropoietin |
| US8969532B2 (en) | 2006-10-03 | 2015-03-03 | Novo Nordisk A/S | Methods for the purification of polypeptide conjugates comprising polyalkylene oxide using hydrophobic interaction chromatography |
| US9005625B2 (en) | 2003-07-25 | 2015-04-14 | Novo Nordisk A/S | Antibody toxin conjugates |
| US9029331B2 (en) | 2005-01-10 | 2015-05-12 | Novo Nordisk A/S | Glycopegylated granulocyte colony stimulating factor |
| US9050304B2 (en) | 2007-04-03 | 2015-06-09 | Ratiopharm Gmbh | Methods of treatment using glycopegylated G-CSF |
| US9150848B2 (en) | 2008-02-27 | 2015-10-06 | Novo Nordisk A/S | Conjugated factor VIII molecules |
| US9200049B2 (en) | 2004-10-29 | 2015-12-01 | Novo Nordisk A/S | Remodeling and glycopegylation of fibroblast growth factor (FGF) |
| US9493499B2 (en) | 2007-06-12 | 2016-11-15 | Novo Nordisk A/S | Process for the production of purified cytidinemonophosphate-sialic acid-polyalkylene oxide (CMP-SA-PEG) as modified nucleotide sugars via anion exchange chromatography |
| WO2018022939A1 (en) * | 2016-07-27 | 2018-02-01 | Amunix Operating Inc. | Treatment of adult growth hormone deficiency with human growth hormone analogues |
Families Citing this family (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6639050B1 (en) | 1997-07-21 | 2003-10-28 | Ohio University | Synthetic genes for plant gums and other hydroxyproline-rich glycoproteins |
| US8008252B2 (en) | 2001-10-10 | 2011-08-30 | Novo Nordisk A/S | Factor VII: remodeling and glycoconjugation of Factor VII |
| DE60336555D1 (en) | 2002-06-21 | 2011-05-12 | Novo Nordisk Healthcare Ag | PEGYLATED GLYCO FORMS OF FACTOR VII |
| US20100069264A1 (en) * | 2003-08-27 | 2010-03-18 | Gil Sharon | Libraries of recombinant chimeric proteins |
| ES2445948T3 (en) * | 2003-11-24 | 2014-03-06 | Ratiopharm Gmbh | Glycopegylated Erythropoietin |
| NZ547554A (en) * | 2003-12-03 | 2009-09-25 | Biogenerix Ag | Glycopegylated granulocyte colony stimulating factor |
| EP1751177A4 (en) | 2004-04-19 | 2008-07-16 | Univ Ohio | Cross-linkable glycoproteins and methods of making the same |
| US20090292110A1 (en) * | 2004-07-23 | 2009-11-26 | Defrees Shawn | Enzymatic modification of glycopeptides |
| US7998930B2 (en) | 2004-11-04 | 2011-08-16 | Hanall Biopharma Co., Ltd. | Modified growth hormones |
| US20100009902A1 (en) * | 2005-01-06 | 2010-01-14 | Neose Technologies, Inc. | Glycoconjugation Using Saccharyl Fragments |
| US20110003744A1 (en) * | 2005-05-25 | 2011-01-06 | Novo Nordisk A/S | Glycopegylated Erythropoietin Formulations |
| KR101524880B1 (en) * | 2006-08-31 | 2015-06-01 | 노파르티스 아게 | Pharmaceutical compositions comprising hgh for oral delivery |
| LT2068907T (en) * | 2006-10-04 | 2018-01-10 | Novo Nordisk A/S | Glycerol linked pegylated sugars and glycopeptides |
| EP2162535A4 (en) * | 2007-06-04 | 2011-02-23 | Novo Nordisk As | O-linked glycosylation using n-acetylglucosaminyl transferases |
| US7968811B2 (en) * | 2007-06-29 | 2011-06-28 | Harley-Davidson Motor Company Group, Inc. | Integrated ignition and key switch |
| US20110105735A1 (en) * | 2009-10-29 | 2011-05-05 | Heather Desaire | Methods of producing and purifying proteins |
| WO2016200645A1 (en) * | 2015-06-12 | 2016-12-15 | Tianxin Wang | Methods for protein modification in pharmaceutical applications |
Family Cites Families (231)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB1479268A (en) | 1973-07-05 | 1977-07-13 | Beecham Group Ltd | Pharmaceutical compositions |
| US4179337A (en) | 1973-07-20 | 1979-12-18 | Davis Frank F | Non-immunogenic polypeptides |
| CH596313A5 (en) | 1975-05-30 | 1978-03-15 | Battelle Memorial Institute | |
| US4385260A (en) | 1975-09-09 | 1983-05-24 | Beckman Instruments, Inc. | Bargraph display |
| US4414147A (en) | 1981-04-17 | 1983-11-08 | Massachusetts Institute Of Technology | Methods of decreasing the hydrophobicity of fibroblast and other interferons |
| JPS57206622A (en) | 1981-06-10 | 1982-12-18 | Ajinomoto Co Inc | Blood substitute |
| US4438253A (en) | 1982-11-12 | 1984-03-20 | American Cyanamid Company | Poly(glycolic acid)/poly(alkylene glycol) block copolymers and method of manufacturing the same |
| US4496689A (en) | 1983-12-27 | 1985-01-29 | Miles Laboratories, Inc. | Covalently attached complex of alpha-1-proteinase inhibitor with a water soluble polymer |
| US4565653A (en) | 1984-03-30 | 1986-01-21 | Pfizer Inc. | Acyltripeptide immunostimulants |
| US4879236A (en) | 1984-05-16 | 1989-11-07 | The Texas A&M University System | Method for producing a recombinant baculovirus expression vector |
| JPS6238172A (en) | 1985-08-12 | 1987-02-19 | 株式会社 高研 | Production of anti-thrombotic medical material |
| AU597574B2 (en) | 1986-03-07 | 1990-06-07 | Massachusetts Institute Of Technology | Method for enhancing glycoprotein stability |
| US4925796A (en) | 1986-03-07 | 1990-05-15 | Massachusetts Institute Of Technology | Method for enhancing glycoprotein stability |
| US4902505A (en) | 1986-07-30 | 1990-02-20 | Alkermes | Chimeric peptides for neuropeptide delivery through the blood-brain barrier |
| IL82834A (en) | 1987-06-09 | 1990-11-05 | Yissum Res Dev Co | Biodegradable polymeric materials based on polyether glycols,processes for the preparation thereof and surgical artiicles made therefrom |
| US5153265A (en) | 1988-01-20 | 1992-10-06 | Cetus Corporation | Conjugation of polymer to colony stimulating factor-1 |
| US4847325A (en) | 1988-01-20 | 1989-07-11 | Cetus Corporation | Conjugation of polymer to colony stimulating factor-1 |
| GB8810808D0 (en) | 1988-05-06 | 1988-06-08 | Wellcome Found | Vectors |
| US5169933A (en) | 1988-08-15 | 1992-12-08 | Neorx Corporation | Covalently-linked complexes and methods for enhanced cytotoxicity and imaging |
| US5104651A (en) | 1988-12-16 | 1992-04-14 | Amgen Inc. | Stabilized hydrophobic protein formulations of g-csf |
| US6166183A (en) | 1992-11-30 | 2000-12-26 | Kirin-Amgen, Inc. | Chemically-modified G-CSF |
| DE68925966T2 (en) | 1988-12-22 | 1996-08-29 | Kirin Amgen Inc | CHEMICALLY MODIFIED GRANULOCYTE COLONY EXCITING FACTOR |
| AU634517B2 (en) * | 1989-01-19 | 1993-02-25 | Pharmacia & Upjohn Company | Somatotropin analogs |
| AU620673B2 (en) * | 1989-01-31 | 1992-02-20 | Pharmacia & Upjohn Company | Somatotropin analogs |
| US5194376A (en) | 1989-02-28 | 1993-03-16 | University Of Ottawa | Baculovirus expression system capable of producing foreign gene proteins at high levels |
| US5122614A (en) | 1989-04-19 | 1992-06-16 | Enzon, Inc. | Active carbonates of polyalkylene oxides for modification of polypeptides |
| JP2875884B2 (en) | 1989-04-19 | 1999-03-31 | ノボ ノルディスク アクティーゼルスカブ | Active polyalkylene oxide carbonates for use in modifying polypeptides |
| US5324844A (en) | 1989-04-19 | 1994-06-28 | Enzon, Inc. | Active carbonates of polyalkylene oxides for modification of polypeptides |
| US5342940A (en) | 1989-05-27 | 1994-08-30 | Sumitomo Pharmaceuticals Company, Limited | Polyethylene glycol derivatives, process for preparing the same |
| US5672683A (en) | 1989-09-07 | 1997-09-30 | Alkermes, Inc. | Transferrin neuropharmaceutical agent fusion protein |
| US5154924A (en) | 1989-09-07 | 1992-10-13 | Alkermes, Inc. | Transferrin receptor specific antibody-neuropharmaceutical agent conjugates |
| US5977307A (en) | 1989-09-07 | 1999-11-02 | Alkermes, Inc. | Transferrin receptor specific ligand-neuropharmaceutical agent fusion proteins |
| US5182107A (en) | 1989-09-07 | 1993-01-26 | Alkermes, Inc. | Transferrin receptor specific antibody-neuropharmaceutical or diagnostic agent conjugates |
| US5527527A (en) | 1989-09-07 | 1996-06-18 | Alkermes, Inc. | Transferrin receptor specific antibody-neuropharmaceutical agent conjugates |
| US5032519A (en) | 1989-10-24 | 1991-07-16 | The Regents Of The Univ. Of California | Method for producing secretable glycosyltransferases and other Golgi processing enzymes |
| US5312808A (en) | 1989-11-22 | 1994-05-17 | Enzon, Inc. | Fractionation of polyalkylene oxide-conjugated hemoglobin solutions |
| US5595900A (en) | 1990-02-14 | 1997-01-21 | The Regents Of The University Of Michigan | Methods and products for the synthesis of oligosaccharide structures on glycoproteins, glycolipids, or as free molecules, and for the isolation of cloned genetic sequences that determine these structures |
| US5324663A (en) | 1990-02-14 | 1994-06-28 | The Regents Of The University Of Michigan | Methods and products for the synthesis of oligosaccharide structures on glycoproteins, glycolipids, or as free molecules, and for the isolation of cloned genetic sequences that determine these structures |
| DE4009630C2 (en) | 1990-03-26 | 1995-09-28 | Reinhard Prof Dr Dr Brossmer | CMP-activated fluorescent sialic acids and processes for their preparation |
| US5583042A (en) | 1990-04-16 | 1996-12-10 | Neose Pharmaceuticals, Inc. | Apparatus for the synthesis of saccharide compositions |
| US5951972A (en) | 1990-05-04 | 1999-09-14 | American Cyanamid Company | Stabilization of somatotropins and other proteins by modification of cysteine residues |
| US5219564A (en) | 1990-07-06 | 1993-06-15 | Enzon, Inc. | Poly(alkylene oxide) amino acid copolymers and drug carriers and charged copolymers based thereon |
| CU22302A1 (en) | 1990-09-07 | 1995-01-31 | Cigb | Codifying nucleotidic sequence for a protein of the external membrane of neisseria meningitidis and the use of that protein in preparing vaccines. |
| US5529914A (en) | 1990-10-15 | 1996-06-25 | The Board Of Regents The Univeristy Of Texas System | Gels for encapsulation of biological materials |
| US5410016A (en) | 1990-10-15 | 1995-04-25 | Board Of Regents, The University Of Texas System | Photopolymerizable biodegradable hydrogels as tissue contacting materials and controlled-release carriers |
| ATE196548T1 (en) * | 1991-05-10 | 2000-10-15 | Genentech Inc | SELECTING AGONISTS AND ANTAGONISTS OF LIGANDS |
| US5352670A (en) | 1991-06-10 | 1994-10-04 | Alberta Research Council | Methods for the enzymatic synthesis of alpha-sialylated oligosaccharide glycosides |
| US5374655A (en) | 1991-06-10 | 1994-12-20 | Alberta Research Council | Methods for the synthesis of monofucosylated oligosaccharides terminating in di-N-acetyllactosaminyl structures |
| KR950014915B1 (en) | 1991-06-19 | 1995-12-18 | 주식회사녹십자 | Asialoglycoprotein-conjugated compounds |
| US5281698A (en) | 1991-07-23 | 1994-01-25 | Cetus Oncology Corporation | Preparation of an activated polymer ester for protein conjugation |
| IT1260468B (en) | 1992-01-29 | 1996-04-09 | METHOD FOR MAINTAINING THE ACTIVITY OF PROTEOLYTIC ENZYMES MODIFIED WITH POLYETHYLENGLYCOL | |
| US5858751A (en) | 1992-03-09 | 1999-01-12 | The Regents Of The University Of California | Compositions and methods for producing sialyltransferases |
| US5962294A (en) | 1992-03-09 | 1999-10-05 | The Regents Of The University Of California | Compositions and methods for the identification and synthesis of sialyltransferases |
| US6037452A (en) | 1992-04-10 | 2000-03-14 | Alpha Therapeutic Corporation | Poly(alkylene oxide)-Factor VIII or Factor IX conjugate |
| US5614184A (en) | 1992-07-28 | 1997-03-25 | New England Deaconess Hospital | Recombinant human erythropoietin mutants and therapeutic methods employing them |
| WO1994004193A1 (en) | 1992-08-21 | 1994-03-03 | Enzon, Inc. | Novel attachment of polyalkylene oxides to bio-effecting substances |
| JP3979678B2 (en) | 1992-08-24 | 2007-09-19 | サントリー株式会社 | Novel glycosyltransferase, gene encoding the same, and method for producing the enzyme |
| NZ250375A (en) | 1992-12-09 | 1995-07-26 | Ortho Pharma Corp | Peg hydrazone and peg oxime linkage forming reagents and protein derivatives |
| WO1994015625A1 (en) | 1993-01-15 | 1994-07-21 | Enzon, Inc. | Factor viii - polymeric conjugates |
| US5349001A (en) | 1993-01-19 | 1994-09-20 | Enzon, Inc. | Cyclic imide thione activated polyalkylene oxides |
| US5321095A (en) | 1993-02-02 | 1994-06-14 | Enzon, Inc. | Azlactone activated polyalkylene oxides |
| US5202413A (en) | 1993-02-16 | 1993-04-13 | E. I. Du Pont De Nemours And Company | Alternating (ABA)N polylactide block copolymers |
| US5374541A (en) | 1993-05-04 | 1994-12-20 | The Scripps Research Institute | Combined use of β-galactosidase and sialyltransferase coupled with in situ regeneration of CMP-sialic acid for one pot synthesis of oligosaccharides |
| EP0726318A1 (en) | 1993-05-14 | 1996-08-14 | The Upjohn Company | An acceptor polypeptide for an N-acetylgalactosaminyltransferase |
| US5621039A (en) | 1993-06-08 | 1997-04-15 | Hallahan; Terrence W. | Factor IX- polymeric conjugates |
| US5919455A (en) | 1993-10-27 | 1999-07-06 | Enzon, Inc. | Non-antigenic branched polymer conjugates |
| US5643575A (en) | 1993-10-27 | 1997-07-01 | Enzon, Inc. | Non-antigenic branched polymer conjugates |
| US5446090A (en) | 1993-11-12 | 1995-08-29 | Shearwater Polymers, Inc. | Isolatable, water soluble, and hydrolytically stable active sulfones of poly(ethylene glycol) and related polymers for modification of surfaces and molecules |
| US5443953A (en) | 1993-12-08 | 1995-08-22 | Immunomedics, Inc. | Preparation and use of immunoconjugates |
| US5369017A (en) | 1994-02-04 | 1994-11-29 | The Scripps Research Institute | Process for solid phase glycopeptide synthesis |
| US5605793A (en) | 1994-02-17 | 1997-02-25 | Affymax Technologies N.V. | Methods for in vitro recombination |
| US5837458A (en) | 1994-02-17 | 1998-11-17 | Maxygen, Inc. | Methods and compositions for cellular and metabolic engineering |
| US5492841A (en) | 1994-02-18 | 1996-02-20 | E. I. Du Pont De Nemours And Company | Quaternary ammonium immunogenic conjugates and immunoassay reagents |
| US5432059A (en) | 1994-04-01 | 1995-07-11 | Specialty Laboratories, Inc. | Assay for glycosylation deficiency disorders |
| US5646113A (en) | 1994-04-07 | 1997-07-08 | Genentech, Inc. | Treatment of partial growth hormone insensitivity syndrome |
| US5629384A (en) | 1994-05-17 | 1997-05-13 | Consiglio Nazionale Delle Ricerche | Polymers of N-acryloylmorpholine activated at one end and conjugates with bioactive materials and surfaces |
| US5545553A (en) | 1994-09-26 | 1996-08-13 | The Rockefeller University | Glycosyltransferases for biosynthesis of oligosaccharides, and genes encoding them |
| US5834251A (en) | 1994-12-30 | 1998-11-10 | Alko Group Ltd. | Methods of modifying carbohydrate moieties |
| US5932462A (en) | 1995-01-10 | 1999-08-03 | Shearwater Polymers, Inc. | Multiarmed, monofunctional, polymer for coupling to molecules and surfaces |
| US5922577A (en) | 1995-04-11 | 1999-07-13 | Cytel Corporation | Enzymatic synthesis of glycosidic linkages |
| US6030815A (en) | 1995-04-11 | 2000-02-29 | Neose Technologies, Inc. | Enzymatic synthesis of oligosaccharides |
| US5728554A (en) | 1995-04-11 | 1998-03-17 | Cytel Corporation | Enzymatic synthesis of glycosidic linkages |
| US5876980A (en) | 1995-04-11 | 1999-03-02 | Cytel Corporation | Enzymatic synthesis of oligosaccharides |
| US6015555A (en) | 1995-05-19 | 2000-01-18 | Alkermes, Inc. | Transferrin receptor specific antibody-neuropharmaceutical or diagnostic agent conjugates |
| US5824864A (en) | 1995-05-25 | 1998-10-20 | Pioneer Hi-Bred International, Inc. | Maize gene and protein for insect control |
| US5858752A (en) | 1995-06-07 | 1999-01-12 | The General Hospital Corporation | Fucosyltransferase genes and uses thereof |
| US6127153A (en) | 1995-06-07 | 2000-10-03 | Neose Technologies, Inc. | Method of transferring at least two saccharide units with a polyglycosyltransferase, a polyglycosyltransferase and gene encoding a polyglycosyltransferase |
| US5672662A (en) | 1995-07-07 | 1997-09-30 | Shearwater Polymers, Inc. | Poly(ethylene glycol) and related polymers monosubstituted with propionic or butanoic acids and functional derivatives thereof for biotechnical applications |
| US5770420A (en) | 1995-09-08 | 1998-06-23 | The Regents Of The University Of Michigan | Methods and products for the synthesis of oligosaccharide structures on glycoproteins, glycolipids, or as free molecules, and for the isolation of cloned genetic sequences that determine these structures |
| ES2338431T3 (en) | 1995-09-21 | 2010-05-07 | Genentech, Inc. | VARIANTS OF HUMAN GROWTH HORMONE. |
| US5716812A (en) | 1995-12-12 | 1998-02-10 | The University Of British Columbia | Methods and compositions for synthesis of oligosaccharides, and the products formed thereby |
| ATE380820T1 (en) | 1996-03-08 | 2007-12-15 | Univ Michigan | MURINE ALPHA(1,3)-FUCOSYLTRANSFERASE (FUC-TVII) |
| US20020064546A1 (en) | 1996-09-13 | 2002-05-30 | J. Milton Harris | Degradable poly(ethylene glycol) hydrogels with controlled half-life and precursors therefor |
| JP2001502005A (en) | 1996-10-10 | 2001-02-13 | サイテル コーポレイション | Purification of carbohydrates using ultrafiltration, reverse osmosis and nanofiltration |
| HUP0000150A3 (en) | 1996-10-15 | 2002-07-29 | Liposome Company Inc Princeton | Peptide-lipid conjugates,liposomes and liposomal drug delivery |
| IL129843A0 (en) | 1996-11-08 | 2000-02-29 | Cytel Corp | Improved expression vectors |
| US6399336B1 (en) | 1997-01-16 | 2002-06-04 | Neose Technologies, Inc. | Practical in vitro sialylation of recombinant glycoproteins |
| US5945314A (en) | 1997-03-31 | 1999-08-31 | Abbott Laboratories | Process for synthesizing oligosaccharides |
| JP2002505574A (en) | 1997-04-30 | 2002-02-19 | エンゾン,インコーポレイテッド | Polyalkylene oxide-modified single-chain polypeptides |
| US6183738B1 (en) | 1997-05-12 | 2001-02-06 | Phoenix Pharamacologics, Inc. | Modified arginine deiminase |
| US6399337B1 (en) | 1997-06-06 | 2002-06-04 | The Governors Of The University Of Alberta | α1,3-fucosyltransferase |
| WO1999000150A2 (en) | 1997-06-27 | 1999-01-07 | Regents Of The University Of California | Drug targeting of a peptide radiopharmaceutical through the primate blood-brain barrier in vivo with a monoclonal antibody to the human insulin receptor |
| US20030027257A1 (en) * | 1997-08-21 | 2003-02-06 | University Technologies International, Inc. | Sequences for improving the efficiency of secretion of non-secreted protein from mammalian and insect cells |
| ATE419009T1 (en) | 1997-10-31 | 2009-01-15 | Genentech Inc | METHODS AND COMPOSITIONS CONSISTING OF GLYCOPROTEIN GLYCOFORMS |
| CA2312843A1 (en) | 1997-12-01 | 1999-06-10 | Neose Technologies Inc. | Enzymatic synthesis of gangliosides |
| EP0924298A1 (en) | 1997-12-18 | 1999-06-23 | Stichting Instituut voor Dierhouderij en Diergezondheid (ID-DLO) | Protein expression in baculovirus vector expression systems |
| DK1053019T3 (en) | 1998-01-07 | 2004-04-13 | Debio Rech Pharma Sa | Degradable heterobifunctional polyethylene glycol acrylates and gels and conjugates derived therefrom |
| JP4078032B2 (en) | 1998-03-12 | 2008-04-23 | ネクター セラピューティックス エイエル,コーポレイション | Poly (ethylene glycol) derivatives with proximal reactive groups |
| EP1091751A4 (en) * | 1998-03-25 | 2005-01-19 | Sloan Kettering Institutefor C | Trimeric antigenic o-linked glycopeptide conjugates, methods of preparation and uses thereof |
| US20030166525A1 (en) | 1998-07-23 | 2003-09-04 | Hoffmann James Arthur | FSH Formulation |
| US7304150B1 (en) | 1998-10-23 | 2007-12-04 | Amgen Inc. | Methods and compositions for the prevention and treatment of anemia |
| WO2000026354A1 (en) | 1998-10-30 | 2000-05-11 | Novozymes A/S | Glycosylated proteins having reduced allergenicity |
| DE19852729A1 (en) | 1998-11-16 | 2000-05-18 | Werner Reutter | Recombinant glycoproteins, processes for their preparation, medicaments containing them and their use |
| US6465220B1 (en) | 1998-12-21 | 2002-10-15 | Glycozym Aps | Glycosylation using GalNac-T4 transferase |
| US6949372B2 (en) | 1999-03-02 | 2005-09-27 | The Johns Hopkins University | Engineering intracellular sialylation pathways |
| US6261805B1 (en) | 1999-07-15 | 2001-07-17 | Boyce Thompson Institute For Plant Research, Inc. | Sialyiation of N-linked glycoproteins in the baculovirus expression vector system |
| US6537785B1 (en) | 1999-09-14 | 2003-03-25 | Genzyme Glycobiology Research Institute, Inc. | Methods of treating lysosomal storage diseases |
| US6716626B1 (en) | 1999-11-18 | 2004-04-06 | Chiron Corporation | Human FGF-21 nucleic acids |
| US6348558B1 (en) | 1999-12-10 | 2002-02-19 | Shearwater Corporation | Hydrolytically degradable polymers and hydrogels made therefrom |
| PT1259563E (en) | 1999-12-22 | 2009-04-14 | Nektar Therapeutics Al Corp | Method for the preparation of 1-benzotriazolyl carbonate esters of water soluble polymers. |
| WO2001049830A2 (en) | 1999-12-30 | 2001-07-12 | Maxygen Aps | Improved lysosomal enzymes and lysosomal enzyme activators |
| US6555660B2 (en) | 2000-01-10 | 2003-04-29 | Maxygen Holdings Ltd. | G-CSF conjugates |
| DK1257295T3 (en) | 2000-02-11 | 2009-08-10 | Bayer Healthcare Llc | Factor VII or VIIA-like molecules |
| AU2001232337A1 (en) | 2000-02-18 | 2001-08-27 | Kanagawa Academy Of Science And Technology | Pharmaceutical composition, reagent and method for intracerebral delivery of pharmaceutically active ingredient or labeling substance |
| EP1263771B1 (en) | 2000-03-16 | 2006-06-14 | The Regents Of The University Of California | Chemoselective ligation by use of a phosphine |
| US6586398B1 (en) | 2000-04-07 | 2003-07-01 | Amgen, Inc. | Chemically modified novel erythropoietin stimulating protein compositions and methods |
| US7338932B2 (en) | 2000-05-11 | 2008-03-04 | Glycozym Aps | Methods of modulating functions of polypeptide GalNAc-transferases and of screening test substances to find agents herefor, pharmaceutical compositions comprising such agents and the use of such agents for preparing medicaments |
| MXPA02011016A (en) | 2000-05-12 | 2004-03-16 | Neose Technologies Inc | In vitro. |
| NZ522030A (en) | 2000-05-15 | 2004-11-26 | F | Erythropoietin composition with a multiple charged inorganic anion i.e. a sulfate a citrate or a phosphate to stabilize the composition |
| ATE309385T1 (en) | 2000-06-28 | 2005-11-15 | Glycofi Inc | METHOD FOR PRODUCING MODIFIED GLYCOPROTEINS |
| AU2001267337A1 (en) | 2000-06-30 | 2002-01-14 | Maxygen Aps | Peptide extended glycosylated polypeptides |
| US6423826B1 (en) | 2000-06-30 | 2002-07-23 | Regents Of The University Of Minnesota | High molecular weight derivatives of vitamin K-dependent polypeptides |
| WO2002013843A2 (en) | 2000-08-17 | 2002-02-21 | University Of British Columbia | Chemotherapeutic agents conjugated to p97 and their methods of use in treating neurological tumours |
| KR100645843B1 (en) | 2000-12-20 | 2006-11-14 | 에프. 호프만-라 로슈 아게 | Erythropoietin conjugates |
| US7892730B2 (en) | 2000-12-22 | 2011-02-22 | Sagres Discovery, Inc. | Compositions and methods for cancer |
| PA8536201A1 (en) | 2000-12-29 | 2002-08-29 | Kenneth S Warren Inst Inc | PROTECTION AND IMPROVEMENT OF CELLS, FABRICS AND ORGANS RESPONDING TO Erythropoietin |
| US6531121B2 (en) | 2000-12-29 | 2003-03-11 | The Kenneth S. Warren Institute, Inc. | Protection and enhancement of erythropoietin-responsive cells, tissues and organs |
| DE60232434D1 (en) | 2001-02-27 | 2009-07-09 | Maxygen Aps | NEW INTERFERON-BETA-LIKE MOLECULES |
| US7235638B2 (en) | 2001-03-22 | 2007-06-26 | Novo Nordisk Healthcare A/G | Coagulation factor VII derivatives |
| WO2002092147A2 (en) | 2001-05-11 | 2002-11-21 | Aradigm Corporation | Optimization of the molecular properties and formulation of proteins delivered by inhalation |
| WO2002092619A2 (en) * | 2001-05-14 | 2002-11-21 | The Gouvernment Of The United States Of America, Represented By The Secretary, Department Of Health And Human Services | Modified growth hormone |
| KR100453877B1 (en) | 2001-07-26 | 2004-10-20 | 메덱스젠 주식회사 | METHOD OF MANUFACTURING Ig-FUSION PROTEINS BY CONCATAMERIZATION, TNFR/Fc FUSION PROTEINS MANUFACTURED BY THE METHOD, DNA CODING THE PROTEINS, VECTORS INCLUDING THE DNA, AND CELLS TRANSFORMED BY THE VECTOR |
| WO2003017949A2 (en) | 2001-08-29 | 2003-03-06 | Neose Technologies, Inc. | Novel synthetic ganglioside derivatives and compositions thereof |
| US7214660B2 (en) | 2001-10-10 | 2007-05-08 | Neose Technologies, Inc. | Erythropoietin: remodeling and glycoconjugation of erythropoietin |
| ES2556338T3 (en) | 2001-10-10 | 2016-01-15 | Novo Nordisk A/S | Remodeling and glycoconjugation of peptides |
| US7179617B2 (en) | 2001-10-10 | 2007-02-20 | Neose Technologies, Inc. | Factor IX: remolding and glycoconjugation of Factor IX |
| US7399613B2 (en) | 2001-10-10 | 2008-07-15 | Neose Technologies, Inc. | Sialic acid nucleotide sugars |
| US7125843B2 (en) | 2001-10-19 | 2006-10-24 | Neose Technologies, Inc. | Glycoconjugates including more than one peptide |
| US7696163B2 (en) | 2001-10-10 | 2010-04-13 | Novo Nordisk A/S | Erythropoietin: remodeling and glycoconjugation of erythropoietin |
| US7297511B2 (en) | 2001-10-10 | 2007-11-20 | Neose Technologies, Inc. | Interferon alpha: remodeling and glycoconjugation of interferon alpha |
| US7173003B2 (en) | 2001-10-10 | 2007-02-06 | Neose Technologies, Inc. | Granulocyte colony stimulating factor: remodeling and glycoconjugation of G-CSF |
| US7265084B2 (en) | 2001-10-10 | 2007-09-04 | Neose Technologies, Inc. | Glycopegylation methods and proteins/peptides produced by the methods |
| US7226903B2 (en) | 2001-10-10 | 2007-06-05 | Neose Technologies, Inc. | Interferon beta: remodeling and glycoconjugation of interferon beta |
| US7439043B2 (en) | 2001-10-10 | 2008-10-21 | Neose Technologies, Inc. | Galactosyl nucleotide sugars |
| US7795210B2 (en) | 2001-10-10 | 2010-09-14 | Novo Nordisk A/S | Protein remodeling methods and proteins/peptides produced by the methods |
| US8008252B2 (en) | 2001-10-10 | 2011-08-30 | Novo Nordisk A/S | Factor VII: remodeling and glycoconjugation of Factor VII |
| AU2004236174B2 (en) | 2001-10-10 | 2011-06-02 | Novo Nordisk A/S | Glycopegylation methods and proteins/peptides produced by the methods |
| US7157277B2 (en) | 2001-11-28 | 2007-01-02 | Neose Technologies, Inc. | Factor VIII remodeling and glycoconjugation of Factor VIII |
| US7265085B2 (en) | 2001-10-10 | 2007-09-04 | Neose Technologies, Inc. | Glycoconjugation methods and proteins/peptides produced by the methods |
| JP2005510229A (en) | 2001-11-28 | 2005-04-21 | ネオーズ テクノロジーズ, インコーポレイテッド | Remodeling of glycoproteins using amidases |
| US7473680B2 (en) | 2001-11-28 | 2009-01-06 | Neose Technologies, Inc. | Remodeling and glycoconjugation of peptides |
| US20060035224A1 (en) | 2002-03-21 | 2006-02-16 | Johansen Jack T | Purification methods for oligonucleotides and their analogs |
| DE60336555D1 (en) | 2002-06-21 | 2011-05-12 | Novo Nordisk Healthcare Ag | PEGYLATED GLYCO FORMS OF FACTOR VII |
| DE10232916B4 (en) | 2002-07-19 | 2008-08-07 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for characterizing an information signal |
| AU2003254139A1 (en) | 2002-07-23 | 2004-02-09 | Neose Technologies, Inc. | H. Pylori FUCOSYLTRANSFERASES |
| CA2497777A1 (en) | 2002-09-05 | 2004-03-18 | The General Hospital Corporation | Modified asialo-interferons and uses thereof |
| JP2006501820A (en) | 2002-09-06 | 2006-01-19 | バイエル・フアーマシユーチカルズ・コーポレーシヨン | Modified GLP-1 receptor agonists and their pharmacological uses |
| DE60314658D1 (en) | 2002-11-08 | 2007-08-09 | Glycozym Aps | METHOD OF IDENTIFYING AGENTS PAINTING THE FUNCTIONS OF POLYPEPTIDE GALNAC TRANSFERASE MODULES, PHARMACEUTICAL COMPOSITIONS COMPRISING SUCH AGENTS, AND USE OF SUCH AGENTS FOR THE MANUFACTURE OF MEDICAMENTS |
| JP4412461B2 (en) | 2002-11-20 | 2010-02-10 | 日油株式会社 | Modified bio-related substance, production method thereof and intermediate |
| US20050064540A1 (en) | 2002-11-27 | 2005-03-24 | Defrees Shawn Ph.D | Glycoprotein remodeling using endoglycanases |
| EP1424344A1 (en) | 2002-11-29 | 2004-06-02 | Aventis Behring Gesellschaft mit beschränkter Haftung | Modified cDNA factor VIII and its derivates |
| PT1428878E (en) | 2002-12-13 | 2008-11-18 | Bioceuticals Arzneimittel Ag | Process for the production and purification of erythropoietin |
| CA2519092C (en) | 2003-03-14 | 2014-08-05 | Neose Technologies, Inc. | Branched water-soluble polymers and their conjugates |
| US20060276618A1 (en) | 2003-03-18 | 2006-12-07 | Defrees Shawn | Activated forms of water-soluble polymers |
| EP1613261A4 (en) | 2003-04-09 | 2011-01-26 | Novo Nordisk As | Intracellular formation of peptide conjugates |
| US7718363B2 (en) | 2003-04-25 | 2010-05-18 | The Kenneth S. Warren Institute, Inc. | Tissue protective cytokine receptor complex and assays for identifying tissue protective compounds |
| ES2380093T3 (en) | 2003-05-09 | 2012-05-08 | Biogenerix Ag | Compositions and methods for the preparation of human growth hormone glycosylation mutants |
| WO2005012484A2 (en) | 2003-07-25 | 2005-02-10 | Neose Technologies, Inc. | Antibody-toxin conjugates |
| US20060198819A1 (en) | 2003-08-08 | 2006-09-07 | Novo Nordisk Healthcare A/G | Use of galactose oxidase for selective chemical conjugation of protractor molecules to proteins of therapeutic interest |
| BRPI0409650A (en) | 2003-09-09 | 2006-04-25 | Warren Pharmaceuticals Inc | methods for regulating hematocrit and human levels, artificial erythropoietin products, methods for preparing an erythropoietin product and for treating anemia in patients at risk of tissue damage, and, pharmaceutical composition |
| US7524813B2 (en) | 2003-10-10 | 2009-04-28 | Novo Nordisk Health Care Ag | Selectively conjugated peptides and methods of making the same |
| US8633157B2 (en) | 2003-11-24 | 2014-01-21 | Novo Nordisk A/S | Glycopegylated erythropoietin |
| US20080305992A1 (en) | 2003-11-24 | 2008-12-11 | Neose Technologies, Inc. | Glycopegylated erythropoietin |
| ES2445948T3 (en) | 2003-11-24 | 2014-03-06 | Ratiopharm Gmbh | Glycopegylated Erythropoietin |
| US7842661B2 (en) | 2003-11-24 | 2010-11-30 | Novo Nordisk A/S | Glycopegylated erythropoietin formulations |
| US7956032B2 (en) | 2003-12-03 | 2011-06-07 | Novo Nordisk A/S | Glycopegylated granulocyte colony stimulating factor |
| NZ547554A (en) | 2003-12-03 | 2009-09-25 | Biogenerix Ag | Glycopegylated granulocyte colony stimulating factor |
| JP2007515410A (en) | 2003-12-03 | 2007-06-14 | ネオス テクノロジーズ インコーポレイテッド | GlycoPEGylated follicle stimulating hormone |
| US20080318850A1 (en) | 2003-12-03 | 2008-12-25 | Neose Technologies, Inc. | Glycopegylated Factor Ix |
| CN101072789B (en) | 2004-01-08 | 2013-05-15 | 生物种属学股份公司 | O-linked glycosylation of peptides |
| WO2005067601A2 (en) | 2004-01-09 | 2005-07-28 | Neose Technologies, Inc. | Vectors for recombinant protein expression in e.coli |
| US20070105770A1 (en) | 2004-01-21 | 2007-05-10 | Novo Nordisk A/S | Transglutaminase mediated conjugation of peptides |
| EP1720892B1 (en) | 2004-01-26 | 2013-07-24 | BioGeneriX AG | Branched polymer-modified sugars and nucleotides |
| JP2007531715A (en) | 2004-03-17 | 2007-11-08 | イーライ リリー アンド カンパニー | Glycol-linked FGF-21 compound |
| KR20070008645A (en) | 2004-05-04 | 2007-01-17 | 노보 노르디스크 헬스 케어 악티엔게젤샤프트 | O-linked glycoforms of polypeptides and method to manufacture them |
| JP2008501344A (en) | 2004-06-03 | 2008-01-24 | ネオス テクノロジーズ インコーポレイティッド | Truncated ST6GalNAcI polypeptide and nucleic acid |
| WO2005121331A2 (en) | 2004-06-03 | 2005-12-22 | Neose Technologies, Inc. | Truncated galnact2 polypeptides and nucleic acids |
| WO2006014349A2 (en) | 2004-07-02 | 2006-02-09 | The Kenneth S. Warren Institute, Inc. | Method of producing fully carbamylated erythropoietin |
| WO2006014466A2 (en) | 2004-07-02 | 2006-02-09 | The Kenneth S. Warren Institute, Inc. | Novel carbamylated epo and method for its production |
| WO2006010143A2 (en) | 2004-07-13 | 2006-01-26 | Neose Technologies, Inc. | Branched peg remodeling and glycosylation of glucagon-like peptide-1 [glp-1] |
| US20090292110A1 (en) | 2004-07-23 | 2009-11-26 | Defrees Shawn | Enzymatic modification of glycopeptides |
| EP1778838A2 (en) | 2004-08-02 | 2007-05-02 | Novo Nordisk Health Care AG | Conjugation of fvii |
| US20060024286A1 (en) | 2004-08-02 | 2006-02-02 | Paul Glidden | Variants of tRNA synthetase fragments and uses thereof |
| EP1799249A2 (en) | 2004-09-10 | 2007-06-27 | Neose Technologies, Inc. | Glycopegylated interferon alpha |
| EP1797192A1 (en) | 2004-09-29 | 2007-06-20 | Novo Nordisk Health Care AG | Modified proteins |
| EP1814573B1 (en) | 2004-10-29 | 2016-03-09 | ratiopharm GmbH | Remodeling and glycopegylation of fibroblast growth factor (fgf) |
| US20090054623A1 (en) | 2004-12-17 | 2009-02-26 | Neose Technologies, Inc. | Lipo-Conjugation of Peptides |
| US20100009902A1 (en) | 2005-01-06 | 2010-01-14 | Neose Technologies, Inc. | Glycoconjugation Using Saccharyl Fragments |
| NZ556436A (en) | 2005-01-10 | 2010-11-26 | Biogenerix Ag | Glycopegylated granulocyte colony stimulating factor |
| WO2006078645A2 (en) | 2005-01-19 | 2006-07-27 | Neose Technologies, Inc. | Heterologous polypeptide expression using low multiplicity of infection of viruses |
| WO2006105426A2 (en) | 2005-03-30 | 2006-10-05 | Neose Technologies, Inc. | Manufacturing process for the production of peptides grown in insect cell lines |
| US9187546B2 (en) | 2005-04-08 | 2015-11-17 | Novo Nordisk A/S | Compositions and methods for the preparation of protease resistant human growth hormone glycosylation mutants |
| JP5216580B2 (en) | 2005-05-25 | 2013-06-19 | ノヴォ ノルディスク アー/エス | Glycopegylated factor IX |
| ES2553160T3 (en) | 2005-06-17 | 2015-12-04 | Novo Nordisk Health Care Ag | Selective reduction and derivatization of engineered Factor VII proteins comprising at least one non-native cysteine |
| US20070105755A1 (en) | 2005-10-26 | 2007-05-10 | Neose Technologies, Inc. | One pot desialylation and glycopegylation of therapeutic peptides |
| US20090305967A1 (en) | 2005-08-19 | 2009-12-10 | Novo Nordisk A/S | Glycopegylated factor vii and factor viia |
| EP1926817A2 (en) | 2005-09-14 | 2008-06-04 | Novo Nordisk Health Care AG | Human coagulation factor vii polypeptides |
| US20090048440A1 (en) | 2005-11-03 | 2009-02-19 | Neose Technologies, Inc. | Nucleotide Sugar Purification Using Membranes |
| CN101484576A (en) | 2006-05-24 | 2009-07-15 | 诺沃-诺迪斯克保健股份有限公司 | Factor IX analogues having prolonged in vivo half life |
| JP2009544327A (en) | 2006-07-21 | 2009-12-17 | ノヴォ ノルディスク アー/エス | Glycosylation of peptides with O-linked glycosylation sequences |
| ITMI20061624A1 (en) | 2006-08-11 | 2008-02-12 | Bioker Srl | SINGLE-CONJUGATE SITE-SPECIFIC OF G-CSF |
| ES2531934T3 (en) | 2006-09-01 | 2015-03-20 | Novo Nordisk Health Care Ag | Modified glycoproteins |
| JP2010505874A (en) | 2006-10-03 | 2010-02-25 | ノヴォ ノルディスク アー/エス | Purification method for polypeptide conjugates |
| LT2068907T (en) | 2006-10-04 | 2018-01-10 | Novo Nordisk A/S | Glycerol linked pegylated sugars and glycopeptides |
| US20080207487A1 (en) | 2006-11-02 | 2008-08-28 | Neose Technologies, Inc. | Manufacturing process for the production of polypeptides expressed in insect cell-lines |
| KR20150064246A (en) | 2007-04-03 | 2015-06-10 | 바이오제너릭스 게엠베하 | Methods of treatment using glycopegylated g―csf |
| US20090053167A1 (en) | 2007-05-14 | 2009-02-26 | Neose Technologies, Inc. | C-, S- and N-glycosylation of peptides |
| EP2162535A4 (en) | 2007-06-04 | 2011-02-23 | Novo Nordisk As | O-linked glycosylation using n-acetylglucosaminyl transferases |
| JP5876649B2 (en) | 2007-06-12 | 2016-03-02 | ラツィオファルム ゲーエムベーハーratiopharm GmbH | Improved process for producing nucleotide sugars |
| FR2918288B1 (en) | 2007-07-03 | 2009-08-28 | Zedel Soc Par Actions Simplifi | LOCKING UP DEVICE ON DOUBLE ROPE |
| US8207112B2 (en) | 2007-08-29 | 2012-06-26 | Biogenerix Ag | Liquid formulation of G-CSF conjugate |
-
2004
- 2004-05-07 ES ES04751591T patent/ES2380093T3/en active Active
- 2004-05-07 CA CA002524936A patent/CA2524936A1/en not_active Abandoned
- 2004-05-07 JP JP2006532844A patent/JP2007523630A/en active Pending
- 2004-05-07 MX MXPA05011832A patent/MXPA05011832A/en not_active Application Discontinuation
- 2004-05-07 WO PCT/US2004/014254 patent/WO2004103275A2/en active Application Filing
- 2004-05-07 US US10/556,094 patent/US7932364B2/en not_active Expired - Fee Related
- 2004-05-07 AU AU2004240553A patent/AU2004240553A1/en not_active Abandoned
- 2004-05-07 BR BRPI0410164-2A patent/BRPI0410164A/en not_active IP Right Cessation
- 2004-05-07 AT AT04751591T patent/ATE540055T1/en active
- 2004-05-07 EP EP04751591A patent/EP1624847B1/en not_active Not-in-force
-
2005
- 2005-05-07 KR KR1020057021304A patent/KR20060030023A/en not_active Application Discontinuation
Non-Patent Citations (2)
| Title |
|---|
| None |
| See also references of EP1624847A4 |
Cited By (48)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8563687B2 (en) | 1997-07-21 | 2013-10-22 | Ohio University | Synthetic genes for plant gums and other hydroxyproline rich glycoproteins |
| US7696163B2 (en) | 2001-10-10 | 2010-04-13 | Novo Nordisk A/S | Erythropoietin: remodeling and glycoconjugation of erythropoietin |
| US8076292B2 (en) | 2001-10-10 | 2011-12-13 | Novo Nordisk A/S | Factor VIII: remodeling and glycoconjugation of factor VIII |
| US8716240B2 (en) | 2001-10-10 | 2014-05-06 | Novo Nordisk A/S | Erythropoietin: remodeling and glycoconjugation of erythropoietin |
| US8716239B2 (en) | 2001-10-10 | 2014-05-06 | Novo Nordisk A/S | Granulocyte colony stimulating factor: remodeling and glycoconjugation G-CSF |
| US7795210B2 (en) | 2001-10-10 | 2010-09-14 | Novo Nordisk A/S | Protein remodeling methods and proteins/peptides produced by the methods |
| US8247381B2 (en) | 2003-03-14 | 2012-08-21 | Biogenerix Ag | Branched water-soluble polymers and their conjugates |
| US7803777B2 (en) | 2003-03-14 | 2010-09-28 | Biogenerix Ag | Branched water-soluble polymers and their conjugates |
| US8791070B2 (en) | 2003-04-09 | 2014-07-29 | Novo Nordisk A/S | Glycopegylated factor IX |
| US8853161B2 (en) | 2003-04-09 | 2014-10-07 | Novo Nordisk A/S | Glycopegylation methods and proteins/peptides produced by the methods |
| US8063015B2 (en) | 2003-04-09 | 2011-11-22 | Novo Nordisk A/S | Glycopegylation methods and proteins/peptides produced by the methods |
| US7932364B2 (en) | 2003-05-09 | 2011-04-26 | Novo Nordisk A/S | Compositions and methods for the preparation of human growth hormone glycosylation mutants |
| US9005625B2 (en) | 2003-07-25 | 2015-04-14 | Novo Nordisk A/S | Antibody toxin conjugates |
| US7842661B2 (en) | 2003-11-24 | 2010-11-30 | Novo Nordisk A/S | Glycopegylated erythropoietin formulations |
| US8633157B2 (en) | 2003-11-24 | 2014-01-21 | Novo Nordisk A/S | Glycopegylated erythropoietin |
| US8916360B2 (en) | 2003-11-24 | 2014-12-23 | Novo Nordisk A/S | Glycopegylated erythropoietin |
| US8632770B2 (en) | 2003-12-03 | 2014-01-21 | Novo Nordisk A/S | Glycopegylated factor IX |
| US7956032B2 (en) | 2003-12-03 | 2011-06-07 | Novo Nordisk A/S | Glycopegylated granulocyte colony stimulating factor |
| US8361961B2 (en) | 2004-01-08 | 2013-01-29 | Biogenerix Ag | O-linked glycosylation of peptides |
| JP2007521807A (en) * | 2004-01-14 | 2007-08-09 | オハイオ ユニバーシティ | Method for producing peptides / proteins in plants and peptides / proteins produced thereby |
| US9006410B2 (en) | 2004-01-14 | 2015-04-14 | Ohio University | Nucleic acid for plant expression of a fusion protein comprising hydroxyproline O-glycosylation glycomodule |
| US8791066B2 (en) | 2004-07-13 | 2014-07-29 | Novo Nordisk A/S | Branched PEG remodeling and glycosylation of glucagon-like peptide-1 [GLP-1] |
| US8268967B2 (en) | 2004-09-10 | 2012-09-18 | Novo Nordisk A/S | Glycopegylated interferon α |
| US10874714B2 (en) | 2004-10-29 | 2020-12-29 | 89Bio Ltd. | Method of treating fibroblast growth factor 21 (FGF-21) deficiency |
| US9200049B2 (en) | 2004-10-29 | 2015-12-01 | Novo Nordisk A/S | Remodeling and glycopegylation of fibroblast growth factor (FGF) |
| US9029331B2 (en) | 2005-01-10 | 2015-05-12 | Novo Nordisk A/S | Glycopegylated granulocyte colony stimulating factor |
| WO2006121569A3 (en) * | 2005-04-08 | 2008-11-20 | Neose Technologies Inc | Compositions and methods for the preparation of protease resistant human growth hormone glycosylation mutants |
| EP2386571A3 (en) * | 2005-04-08 | 2012-02-15 | BioGeneriX AG | Compositions and methods for the preparation of protease resistant human growth hormone glycosylation mutants |
| US8404809B2 (en) | 2005-05-25 | 2013-03-26 | Novo Nordisk A/S | Glycopegylated factor IX |
| JP2008542285A (en) * | 2005-05-25 | 2008-11-27 | ネオス テクノロジーズ インコーポレイテッド | Glycopegylated factor IX |
| US8911967B2 (en) | 2005-08-19 | 2014-12-16 | Novo Nordisk A/S | One pot desialylation and glycopegylation of therapeutic peptides |
| US8043833B2 (en) | 2005-10-31 | 2011-10-25 | Novo Nordisk A/S | Expression of soluble therapeutic proteins |
| US8841439B2 (en) | 2005-11-03 | 2014-09-23 | Novo Nordisk A/S | Nucleotide sugar purification using membranes |
| WO2007120932A2 (en) | 2006-04-19 | 2007-10-25 | Neose Technologies, Inc. | Expression of o-glycosylated therapeutic proteins in prokaryotic microorganisms |
| US9187532B2 (en) * | 2006-07-21 | 2015-11-17 | Novo Nordisk A/S | Glycosylation of peptides via O-linked glycosylation sequences |
| JP2009544327A (en) * | 2006-07-21 | 2009-12-17 | ノヴォ ノルディスク アー/エス | Glycosylation of peptides with O-linked glycosylation sequences |
| EP2049144A4 (en) * | 2006-07-21 | 2012-07-25 | Novo Nordisk As | Glycosylation of peptides via o-linked glycosylation sequences |
| EP2049144A2 (en) * | 2006-07-21 | 2009-04-22 | Neose Technologies, Inc. | Glycosylation of peptides via o-linked glycosylation sequences |
| US8969532B2 (en) | 2006-10-03 | 2015-03-03 | Novo Nordisk A/S | Methods for the purification of polypeptide conjugates comprising polyalkylene oxide using hydrophobic interaction chromatography |
| US9050304B2 (en) | 2007-04-03 | 2015-06-09 | Ratiopharm Gmbh | Methods of treatment using glycopegylated G-CSF |
| US9493499B2 (en) | 2007-06-12 | 2016-11-15 | Novo Nordisk A/S | Process for the production of purified cytidinemonophosphate-sialic acid-polyalkylene oxide (CMP-SA-PEG) as modified nucleotide sugars via anion exchange chromatography |
| US8207112B2 (en) | 2007-08-29 | 2012-06-26 | Biogenerix Ag | Liquid formulation of G-CSF conjugate |
| JP2011512121A (en) * | 2008-01-08 | 2011-04-21 | バイオジェネリックス アーゲー | Glycoconjugation of polypeptides using oligosaccharyltransferase |
| US9150848B2 (en) | 2008-02-27 | 2015-10-06 | Novo Nordisk A/S | Conjugated factor VIII molecules |
| US20110118183A1 (en) * | 2008-06-27 | 2011-05-19 | Novo Nordisk Health Care Ag | N-glycosylated human growth hormone with prolonged circulatory half-life |
| WO2009156511A3 (en) * | 2008-06-27 | 2010-04-01 | Novo Nordisk Health Care Ag | N-glycosylated human growth hormone with prolonged circulatory half-life |
| WO2009156511A2 (en) * | 2008-06-27 | 2009-12-30 | Novo Nordisk A/S | N-glycosylated human growth hormone with prolonged circulatory half-life |
| WO2018022939A1 (en) * | 2016-07-27 | 2018-02-01 | Amunix Operating Inc. | Treatment of adult growth hormone deficiency with human growth hormone analogues |
Also Published As
| Publication number | Publication date |
|---|---|
| MXPA05011832A (en) | 2006-02-17 |
| KR20060030023A (en) | 2006-04-07 |
| ATE540055T1 (en) | 2012-01-15 |
| CA2524936A1 (en) | 2004-12-02 |
| US7932364B2 (en) | 2011-04-26 |
| EP1624847A2 (en) | 2006-02-15 |
| AU2004240553A1 (en) | 2004-12-02 |
| BRPI0410164A (en) | 2006-05-16 |
| US20080102083A1 (en) | 2008-05-01 |
| ES2380093T3 (en) | 2012-05-08 |
| EP1624847A4 (en) | 2008-06-18 |
| WO2004103275A3 (en) | 2007-05-18 |
| JP2007523630A (en) | 2007-08-23 |
| EP1624847B1 (en) | 2012-01-04 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP1624847B1 (en) | Compositions and methods for the preparation of human growth hormone glycosylation mutants | |
| EP1765853B1 (en) | O-linked glycosylation of G-CSF peptides | |
| US8791066B2 (en) | Branched PEG remodeling and glycosylation of glucagon-like peptide-1 [GLP-1] | |
| EP2049144B1 (en) | Glycosylation of peptides via o-linked glycosylation sequences | |
| US20090053167A1 (en) | C-, S- and N-glycosylation of peptides | |
| US20100286067A1 (en) | Glycoconjugation of polypeptides using oligosaccharyltransferases | |
| WO2008151258A2 (en) | O-linked glycosylation using n-acetylglucosaminyl transferases | |
| ZA200701909B (en) | Compositions and methods for the preparation of human growth hormone glycosylation mutants | |
| MXPA06007725A (en) | O-linked glycosylation of peptides |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| AK | Designated states |
Kind code of ref document: A2 Designated state(s): AE AG AL AM AT AU AZ BA BB BG BR BW BY BZ CA CH CN CO CR CU CZ DE DK DM DZ EC EE EG ES FI GB GD GE GH GM HR HU ID IL IN IS JP KE KG KP KR KZ LC LK LR LS LT LU LV MA MD MG MK MN MW MX MZ NA NI NO NZ OM PG PH PL PT RO RU SC SD SE SG SK SL SY TJ TM TN TR TT TZ UA UG US UZ VC VN YU ZA ZM ZW |
|
| AL | Designated countries for regional patents |
Kind code of ref document: A2 Designated state(s): BW GH GM KE LS MW MZ NA SD SL SZ TZ UG ZM ZW AM AZ BY KG KZ MD RU TJ TM AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HU IE IT LU MC NL PL PT RO SE SI SK TR BF BJ CF CG CI CM GA GN GQ GW ML MR NE SN TD TG |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application | ||
| WWE | Wipo information: entry into national phase |
Ref document number: 2004240553 Country of ref document: AU |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 543137 Country of ref document: NZ |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2006532844 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 171592 Country of ref document: IL |
|
| DPEN | Request for preliminary examination filed prior to expiration of 19th month from priority date (pct application filed from 20040101) | ||
| ENP | Entry into the national phase |
Ref document number: 2004240553 Country of ref document: AU Date of ref document: 20040507 Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: PA/a/2005/011832 Country of ref document: MX |
|
| WWP | Wipo information: published in national office |
Ref document number: 2004240553 Country of ref document: AU |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2524936 Country of ref document: CA |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 1020057021304 Country of ref document: KR |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 02351/KOLNP/2005 Country of ref document: IN Ref document number: 2351/KOLNP/2005 Country of ref document: IN |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2004751591 Country of ref document: EP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2005/09864 Country of ref document: ZA Ref document number: 200509864 Country of ref document: ZA |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 20048168473 Country of ref document: CN |
|
| WWP | Wipo information: published in national office |
Ref document number: 2004751591 Country of ref document: EP |
|
| WWP | Wipo information: published in national office |
Ref document number: 1020057021304 Country of ref document: KR |
|
| ENP | Entry into the national phase |
Ref document number: PI0410164 Country of ref document: BR |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 10556094 Country of ref document: US |