WO1984004620A1 - Apparatus and method for speaker independently recognizing isolated speech utterances - Google Patents
Apparatus and method for speaker independently recognizing isolated speech utterances Download PDFInfo
- Publication number
- WO1984004620A1 WO1984004620A1 PCT/US1983/000750 US8300750W WO8404620A1 WO 1984004620 A1 WO1984004620 A1 WO 1984004620A1 US 8300750 W US8300750 W US 8300750W WO 8404620 A1 WO8404620 A1 WO 8404620A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- utterance
- signal
- unknown
- word
- predefined
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 65
- KKEBXNMGHUCPEZ-UHFFFAOYSA-N 4-phenyl-1-(2-sulfanylethyl)imidazolidin-2-one Chemical compound N1C(=O)N(CCS)CC1C1=CC=CC=C1 KKEBXNMGHUCPEZ-UHFFFAOYSA-N 0.000 claims description 7
- 230000000063 preceeding effect Effects 0.000 claims description 2
- 238000004458 analytical method Methods 0.000 description 15
- 238000012545 processing Methods 0.000 description 6
- 101000782167 Homo sapiens Zinc finger protein 234 Proteins 0.000 description 2
- 101000785650 Homo sapiens Zinc finger protein 268 Proteins 0.000 description 2
- 108091008770 Rev-ErbAß Proteins 0.000 description 2
- 102100036555 Zinc finger protein 234 Human genes 0.000 description 2
- 102100026522 Zinc finger protein 267 Human genes 0.000 description 2
- 102100026516 Zinc finger protein 268 Human genes 0.000 description 2
- 230000005540 biological transmission Effects 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- 229910003460 diamond Inorganic materials 0.000 description 2
- 239000010432 diamond Substances 0.000 description 2
- 239000002360 explosive Substances 0.000 description 2
- RZVHIXYEVGDQDX-UHFFFAOYSA-N 9,10-anthraquinone Chemical compound C1=CC=C2C(=O)C3=CC=CC=C3C(=O)C2=C1 RZVHIXYEVGDQDX-UHFFFAOYSA-N 0.000 description 1
- 241000256844 Apis mellifera Species 0.000 description 1
- 241001470502 Auzakia danava Species 0.000 description 1
- 101000785648 Homo sapiens Zinc finger protein 266 Proteins 0.000 description 1
- 241000405961 Scomberomorus regalis Species 0.000 description 1
- 102100026521 Zinc finger protein 266 Human genes 0.000 description 1
- 230000003466 anti-cipated effect Effects 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 230000036571 hydration Effects 0.000 description 1
- 238000006703 hydration reaction Methods 0.000 description 1
- 238000007689 inspection Methods 0.000 description 1
- 229920006395 saturated elastomer Polymers 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 238000012795 verification Methods 0.000 description 1
Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/78—Detection of presence or absence of voice signals
- G10L25/87—Detection of discrete points within a voice signal
Definitions
- This invention relates to improvements in apparatuses and methods for recognizing unknown speech utterances or words, and more particularly to improvements in such apparatuses and methods in which such recognition is enabled independently of the speaker; i.e., without requiring a prior memorization of a par- 10 ticular speaker's voice patterns for particular words to be recognized.
- Speech independent recognition is generally held to mean recognition of at least a predefined vocabulary or set of words without a requirement for prior knowledge of the particular voice characteristics, such as dialect, pitch, speaking rate, etc., of the speaker.
- feature analysis a technique of word or speech-utterance identification which is referred to herein as "feature analysis”. This is in contra ⁇ distinction to the prior art which often is referred to as “template analysis”.
- template analysis an utterance of a
- 25 particular speaker is memorized in digital or analog form and subsequent utterances are compared against the template. If a match is found, the word is identified, otherwise the word is not identified.
- One of the problems of the "template analysis" tech- niques of the prior is that they are, in general, speaker de ⁇ pendent. That is, a particular word spoken by one individual produces a unique temp-late which does not match the speech pat ⁇ tern of most speakers saying the same word.
- each speaker whose words are to be identified preproduce a template vocabulary of the words to be recognized. It can be seen that it would be of great advantage to provide a system which is speaker independent, that is, does not require a series of individual speaker templates.
- feature analysis recognizes words by determining several predefined charac- teristics of the word-acoustic patterns and through decisional software routines, eliminating from consideration, or including in consideration, possible word candidates to be identified. The process may be accomplished at various levels and stages using some or all of the characteristics, but, it should be emphasized that a particular word or utterance to be recognized is not routinely compared to each of the word candidates possible to be recognized in the system. It is this feature which distinguishes the technique of the invention from the "template analysis” of the prior art which required such precision complete unknown word to template comparisions. (The prior art, in fact, usually com ⁇ pared the utterance to each and every word of the vocabulary even though a match was found early in the comparison process.)
- FIG. 1 is a diagrammatic box-diagram of an apparatus for speaker independently determining unknown speech utterances, in accordance with the invention.
- FIG. 2 is a flow chart illustrating the general or generic method for speaker independently determining unknown speech utterances in conjunction with the apparatus of FIG. 1, and in accordance with the invention.
- FIG. 3 is a silhouette of an acoustic waveform of the word
- FIG. 4 is a silhouette of an acoustic waveform of the word "one".
- FIG. 5 is a silhouette of an acoustic waveform of the word "two".
- FIG. 6 is a silhouette of an acoustic waveform of the word "three".
- FIG . 7 is a silhouette of an acoustic waveform of the word
- FIG. 8 is a silhouette of an acoustic waveform of the word
- FIG. 9 is a silhouette of an acoustic waveform of the word "six”.
- FIG. 10 is a silhouette of an acoustic waveform of the word "seven”.
- FIG. 11 is a silhouette of an acoustic waveform of the word "eight".
- FIG. 12 is a silhouette of an acoustic waveform of the word "nine".
- an object of the invention to provide a speaker-independent voice recognition apparatus and method.
- the invention provides an apparatus and method for identifying voice utterances or words including the steps of generating the digitized signal representing the utterance, determining the features of the digital representation including the zero crossing frequencies, energy, zero crossing rates, grouping the determined features into vowel, consonant and syllable groups and identifying the grouped features.
- the method includes the steps of companding the digitized signal to generate a complete decodeable signal representation of the utterance over the dyna-
- the method for recognizing an unknown word or speech utterance as one of a pre- 5 defined set of words includes the steps of establishing at least one flag (feature indicator) which is set when a predefined utterance pattern is present in the unknown speech utterance. At least one signal representing the gross parameter of the unknown . utterance is established, and a plurality of signals representing 0. fine parameters of predefined representations of the unknown utterance are also established. The unknown speech utterance is tested to determine whether to set the flag, and the gross para ⁇ meter representing the signal is determined.
- the predefined set of words is searched to identify at least one of them which is 5 characterized by at least the utterance pattern indicated by the set flag, if any, and by at least the gross parameter indicated by the gross parameter indicating signal. Finally, it is deter ⁇ mined whether the set of identified features associated with the unknown word are adequate to identify the word.
- the voice control recognition system in accordance with a preferred embodiment of the invention, is achieved with both hardware and software requirements presently defined. It should be emphasized that the apparatus and method herein described 5 achieves speaker-independent voice recognition as a time-domain process, without regard to frequency-domain analysis. That is, no complicated orthogonal analysis or fast Fourier transformed analysis are used, thereby enabling rapid, real time operation of
- a system 10 utilizes a central pro- 5 cessing unit (CPU) 11 in conjunction with other hardware elements to be described.
- the CPU 11 can be any general purpose appropriately programmed computer, and, in fact, can be a CPU portion of any widely available home computer, such as those sold by IBM, APPLE, COMMODORE, RADIO SHACK, and other vendors.
- a 10 memory element 12 is in data and control communication with the
- An output device 15 is provided to convert the output signal generated by the CPU 11 to an appropriate useable form.
- the output of the apparatus 10 is delivered to a CRT screen 16 for display; con ⁇ sequently, the output box 15 in the embodiment illustrated will contain appropriate data decoders and CRT drivers, as will be apparent to those skilled in the art. Also, it will be apparent 20. to those skilled in the art that many other output utilization devices can be equally advantageously employed. For instance, by way of example and not limitation, robots, data receivers for flight control apparatuses, automatic banking devices, and the like may be used. Diverse utilization application devices will 25 be clearly apparent to those skilled in the art.
- a bandpass filter 20 At the data input port of the CPU 11, a bandpass filter 20, an analog-to-digital (A/D) and companding circuitry 21 are pro ⁇ vided.
- A/D analog-to-digital
- companding circuitry 21 At the data input port of the CPU 11, a bandpass filter 20, an analog-to-digital (A/D) and companding circuitry 21 are pro ⁇ vided.
- the companding operation provided by the A/D and com ⁇ panding circuitry 21 enables a wide, dynamic energy range of
- a microphone or other speech-receiving apparatus 23 is provided into which a speech utterance made by a person 24 is received and applied to the CPU 11 via the bandpass filter 20 and A/D in companding cir ⁇ cuitry 21.
- control algorithm portion 27 of the memory is provided in which the various machine CPU operational steps are contained. Also contained in the memory element 12 is a word buffer 28 as well as a portion for various data tables developed by the control algorithm 27 from the received utterance delivered to the CPU 11. The detailed characteristic portion are contained in the area 29.
- the analog signal is applied to a bandpass filter 20, then to the A/D and companded circuitry 21 where it is digitized and companded.
- the bandpass filter and A/D compander 21 may be of any commercial available bandpass, A/D and com ⁇ panding circuits, an example of which are, respectively, an MK5912 and MK5116, provided by Mostek Corporation of Dallas, Texas.
- the companding circuitry 21 follows the u-255 Law Companding Code.
- the signal received along the path including the microphone 23, bandpass filter 20 and A/D and companding circuitry 21 continuously receives and applies a signal to the CPU 11 which, under the control of the control algorithm 27 in the memory element 12, examines or deter ⁇ mines when the signal represents a speech utterance or, as referred to herein, a word.
- the detailed characteristic data tables 29 and summary tables 33 are developed, as well as the various flags 35.
- the wordset 36 is then examined, and wordsubsets determined, both of possible can ⁇ didates for the word to be detected and also sets of words which are not the word to be detected.
- the characteristics of the received word are then further refined and the word selection/elimination process is continued until the final word is selected, or until no word is selected.
- the CPU develops an output to the output device 15, either directly on line 45 or indirectly via the A/D and com ⁇ panding circuitry 21 on line 46 for application to the output utilization device, in the embodiment illustrated, the television or CRT display 16.
- the A/D and com ⁇ panding circuitry 20 includes a decoder circuit so that if desired, the unknown word can be decoded and applied in analog form to the output device 15 for application to a speaker (not shown) or the like for verification. More particularly, the steps for determining the word or other speech utterance are shown in box-diagram form in FIG.
- the unknown word 50 in analog form, is digi ⁇ tized and companded, box 52.
- the human ear is particularly adapted for detecting subtle nuances of volume or intensity of sounds in human speech recognition, machines or apparatuses used in the past do not have such dynamic range readily available.
- the companded signals can be uncompanded or decoded at a receiving terminal to enable the original signal to be recreated for the listener.
- the signal to be recognized is first companded in the box indicated by the reference numeral 52. This enables the signal having low levels to be amplified so that the ordinarily recognizable low energy levels of the signal can be recognized, and, additionally, the high level portions of the signal can be preserved for appropriate processing.
- companding is recognized in the telecommunications art, one companding law being referred to, for example, is the u-255 Law Companding Code.
- the companding pro ⁇ cess in essence produces a signal having an output energy level which is nonlinearly related to the input signal level at high and low signal levels, and linearly related at the mid-range signal level values.
- the decoder has an appropriate inverse transfer function. As mentioned with reference to FIG. 1, the digitized and companded signal is applied to the CPU 11 con ⁇ tinuously, and as the various sounds and other background noises are received, the presence, if any, of a word or any other speech utterance is determined, box 53.
- the manner in which the start of an unknown word is determined is to monitor con ⁇ tinuously the signal output from the A/D and companding circuitry 21 and noting when the signal level exceeds a predetermined level for a predetermined time.
- a "word" is initially defined (although, as below described, if a major vowel is not found in the word, the development of the data representing the characteristics of the word is not completed) . It has been found that a level of approximately l/8th of the maximum anticipated signal level for about 45 milliseconds can be used to reliably determine the beginning of a signal having a higher probability of being an appropriate word to be recognized.
- a word length of 600 milliseconds is stored for analysis.
- the word to be recognized is defined to be contained in a window of 600 millise ⁇ cond. It will be appreciated that some words will occupy more time space of the 600 millisecond window than others, but the amount of window space can be, if desired, one of the parameters or characteristics used in including and excluding word patterns of the possible set of words which the unknown word could possibly be.
- the signal detected at the input to the system is con ⁇ tinuously circulated through the unknown word buffer of the memory until the signal having the required level and duration occurs.
- the central processing unit 11 on an interrupt level begins the process of defining the word "window".
- the first step in defining the word "window” is to examine the data in the unknown word buffer 28 backwards in time until a silence condition is detected. From the point at which silence is detected, a 600 millisecond window is defined. It should be emphasized that during this time, once the beginning of the 600 millisecond window is defined, the various characteristic data tables are being generated, thus, enabling rapid, dynamic processing of the unknown word.
- the window is divided into ten millisecond sections or frames, each frame containing a portion of the digitized word signal in the window. This is indicated in box 55.
- Table 1 represents the number of zero crossings of the companded signal, each of the numbers in each frame representing the number of zero crossings of the signal in that particular frame.
- H thirtee
- the companded signal there are fifteen(H) crossings.
- the third ten millisecond frame there are also fiftee (H) zero crossing.
- the fourth ten millisecond frame there are eighteen(H) zero crossings, and so forth.
- Table 2 represents an energy-related value of the signal represented in each ten millisecond frame.
- the energy approxi ⁇ mation in accordance with the invention is determined by the sum of the absolute value of the positive going signal excursions of the companded signal in each frame multiplied times four.
- the value in the first ten millisecond frames is eight(H).
- the values in the second and third ten millisecond frames are A(H) and B(H), respectively .
- Table 3 represents in accordance with the invention, the value of the peak-to-peak maximum voltage of the companded signal in each of the respective ten millisecond frames.
- the peak-to-peak maximum voltage in the first three ten millisecond 10. frames is four(H).
- the value in the fourth ten millisecond frame is five(H) and the value in the fifth ten millisecond frame is five(H), and so on.
- Table 4 is the number of major cycles contained in each of the ten millisecond frames.
- a major cycle is determined by the 15 number of cycles which exceed 50 percent of the maximum amplitude of the signal contained throughout the entire 600 millisecond word window.
- the number of major cycles is one(H).
- the number of major cycles is two(H).
- the number of major cycles is five(H) , and so on.
- Table 5 represents the absolute number of cycles contained within each ten millisecond frame.
- the absolute number of cycles contains both the number of major cycles, as set forth in 25 Table 4 as well as the lesser cycles, i.e., those having less than 50 percent of the amplitude of the signal contained in the 600 millisecond window.
- the first ten millisecond fra ⁇ me has a value of D(H).
- the second frame has a value of thirteen ( H) and the third frame has a value of seventeen(H) , and so on . 15
- Summary Characteristic Data Table 6 includes four values. s
- VST Vehicle Start
- VEN Vehicle End - Start of Second Syllable
- frame 1B Frame 1B(H)
- VEN2 End of Second Syllable
- the vowel start frame is determined from the data contained in the detailed characteristic data table representing the peak- to-peak maximum voltage, Table 3.
- the method by which the vowel start is determined is by determining whether a predetermined peak-to-peak voltage value exists for a predetermined number of frames. For example, if 3/4ths of the maximum peak-to-peak value exists in six frames, a major vowel would appear to be present. From the point at which the first 3/4ths peak-to-peak value appears in the 600 millisecond word window, the previous word frames are examined to a point at which the voltage drop is at least l/8th of the peak-to-peak voltage value.
- Other methods for determining the vowel start can be used from the data in the • tables, for example, another method which can be used is to exa ⁇ mine the data preceeding the 3/4ths peak-to-peak value frame
- the vowel end (or start of the second syllable) frame is determined from an examination of the detailed characteristic data tables. More particularly, the detailed characteristic data table contain the energy related values, Table 2 , are examined to determine the vowel end. Thus, when the energy falls to a prede ⁇ termined level of energy for a predetermined number of frames , then the vowel end is defined. For example, if the energy falls to a value of 1/8th of the maximum energy for a period of about eight frames, the frame at which the energy falls to the l/8th level is defined as the vowel end.
- the end of the second syllable is determined from the detailed characteristic data tables in a fashion similar to the determination of the Vowel End (VEN) determination above described.
- the maximum peak-to-peak voltage over the entire sample is determined directly from the data in Table 3, from which it can be seen that the largest value in the table is the value FKH) which occurs at frame 16.
- the data in the summary characteristic data tables * 7, 8, and 9, are generated from grouped data from the detailed characteristic data tables 1-5.
- the word to be evaluated within the 6/10ths second window is divided into four sections, beginning with the vowel-start frame indicated by the parameter VST in Table 6 and ending with the vowel end frame, as indicated by the parameter VEN in Table 6.
- the vowel- start frame begins in frame D(H) and the vowel ends in frame 17(H).
- the first- l/4th of the divided data is contained in frames 13 to 15
- the second l/4th is contained in frames 16 to
- the third l/4th is contained in frames 19 to 21, and the last l/4th is contained in frames 22 to 23.
- Summary characteristic data table 7 is developed from the detailed characteristic data table presenting the approximate energy set forth in Table 2.
- the summary values listed in Table 7 are as follows: HZl - the average number of zero crossings of the companded signal in the first quarter of the frames beginning at the vowel start (VST) and ending at the end of the first vowel (VEN).
- HZ2 - is the average number of zero crossings of the com ⁇ panded signal for the second and third quarters of the frames
- HZ3 - is the average number of zero crossings of the com ⁇ panded signal for the last quarter during the period VST-VEN.
- HZ4 - set forth in Table 7 is a post-end characteristic 5 which represents the average number of zero crossings of the com ⁇ panded signal beginning at a point after the end of the first vowel and includes the second syllable, if any. In the case illustrated, the values in this region is the "VEN" sound of the word "seven”. JLO In similar fashion, a summary table of the average number of major cycles over the same one-quarter portions of the period between the vowel start (VST) and vowel end (VEN) is developed.
- HZF1 is the average number of major cycles in the first quarter
- HZF2 is the average number of major cycles in the second 15 and third quarters
- HZF3 is the average number of major cycles in the fourth quarter
- HZF4 is the average number of major cycles in the post-end period.
- HZAl represents the average of the abso ⁇ lute number of cycles in the first quarter
- HZA2 represents the 25 average of the absolute number of cycles in the second and third quarters
- HZA3 represents the average of the absolute number of cycles in the fourth quarter
- HZA4 represents the average of the absolute number of cycles in the post-end period.
- a number of special flags are determined.
- the preliminary special flags are* set upon the existence of: a leading "s”, a leading "t”, a trailing "s”, a trailing "t”, a multiple syllable word, a second syllable empha- sized word, a trailing "p", a leading "f”, a trailing "f”, a leading "w”, a possible leading "s”, a possible leading "t”, a possible trailing "s”, a possible trailing "t”, and a possible trailing "p".
- the energy values of the word “one” has a relatively shallow leading edge building up to a peak-energy value.
- the word “two” has an explosive initial energy value, followed by a period of minimum energy, then the remaining word sounds completing the word after the initial "t” sound.
- one or more special charac ⁇ teristics can be defined.
- the characteristics which are defined depend primarily upon the type of characteristics necessary to recognize the word as well as distinguishing characteristics which distinguish the word from other words which may be in the system vocabulary. The greater the number of words in the vocab ⁇ ulary and the closer the number of words from which an unknown word must be distinguished, the greater the number of charac ⁇ teristics which must be included and examined before an unknown word can be identified.
- the word “six” can have six different characteristics by which the word “six” is deter ⁇ mined when the included vocabulary against which it is compared includes only the numbers 0 through 9 and not words which are of close sound, such as the words “sex”, “socks”, “sucks”, etc.
- the six numerically distinguishing characteristics are: (1) a leading "s” must be present (leading "s” flagset);
- the vowel must be a high-frequency vowel (determined from tables 1 and 5 ⁇ ; 22
- the post-end characteristic must be of low amplitude with a high frequency tail of hydration, for example, greater than 30 milliseconds.
- J.Q of word identification is not dependent upon the speed against which each word in the vocabulary is compared.
- the issue to be determined in each particular system is that of determining the number of characteristics of a particular unknown word which must be identified before the word can be identified.
- the issue is determined principally by the
Abstract
Apparatus (Fig. 1) and method (Fig. 2) for identifying voice utterances or words includes the steps of generating the digitized signal (52) representing the utterance, determining the features of the digital representation including the zero crossing frequencies, energy, zero crossing rates (56), grouping the determined features into vowel, consonant an syllable groups and identifying the grouped features. The method includes the steps of companding (52) the digitized signal to generate a complete decodeable signal representation of the utterance over the dynamic energy range of the signal to achieve increased accuracy of speaker independent voice recognition. The method for recognizing an unknown word or speech utterance as one of a predefined set of words includes the steps of establishing at least one flag (feature indicator) which is set (60) when a predefined utterance pattern is present in the unknown speech utterance. At least the gross parameters of the unknown utterance are established, and a plurality of fine parameters of predefined representations of the unknown utterance are also established. The unknown speech utterance is tested to determine whether to set the flag, and the gross parameter representing the signal is determined. The predefined set of words is searched to identify at least one of them which is characterized by at least the gross parameters. Finally, it is determined whether the set of identified feature associated with the unknown word are adequate to identify the word.
Description
APPARATUS AND METHOD FOR SPEAKER
INDEPENDENTLY RECOGNIZING ISOLATED SPEECH UTTERANCES
BACKGROUND OF THE INVENTION
1. FIELD OF THE INVENTION
*. 5 This invention relates to improvements in apparatuses and methods for recognizing unknown speech utterances or words, and more particularly to improvements in such apparatuses and methods in which such recognition is enabled independently of the speaker; i.e., without requiring a prior memorization of a par- 10 ticular speaker's voice patterns for particular words to be recognized.
2. DESCRIPTION OF THE PRIOR ART
In the field of voice recognition, a large amount of interest has been expressed in achieving "speaker independent"
15 recognition. "Speaker independent" recognition is generally held to mean recognition of at least a predefined vocabulary or set of words without a requirement for prior knowledge of the particular voice characteristics, such as dialect, pitch, speaking rate, etc., of the speaker.
20 As will become apparent, the invention is directed toward a technique of word or speech-utterance identification which is referred to herein as "feature analysis". This is in contra¬ distinction to the prior art which often is referred to as "template analysis". In "template analysis" an utterance of a
25 particular speaker is memorized in digital or analog form and subsequent utterances are compared against the template. If a match is found, the word is identified, otherwise the word is not identified. One of the problems of the "template analysis" tech-
niques of the prior is that they are, in general, speaker de¬ pendent. That is, a particular word spoken by one individual produces a unique temp-late which does not match the speech pat¬ tern of most speakers saying the same word. Thus, to be effec- tive, one requirement of the prior art systems is that each speaker whose words are to be identified preproduce a template vocabulary of the words to be recognized. It can be seen that it would be of great advantage to provide a system which is speaker independent, that is, does not require a series of individual speaker templates.
In accordance with the present invention, a speech word or utterance recognition or technique is provided which is referred to herein "feature analysis". Broadly, "feature analysis" recognizes words by determining several predefined charac- teristics of the word-acoustic patterns and through decisional software routines, eliminating from consideration, or including in consideration, possible word candidates to be identified. The process may be accomplished at various levels and stages using some or all of the characteristics, but, it should be emphasized that a particular word or utterance to be recognized is not routinely compared to each of the word candidates possible to be recognized in the system. It is this feature which distinguishes the technique of the invention from the "template analysis" of the prior art which required such precision complete unknown word to template comparisions. (The prior art, in fact, usually com¬ pared the utterance to each and every word of the vocabulary even though a match was found early in the comparison process.)
In efforts of others to achieve speaker independent voice recognition, complicated mathematical frequency analyses
were performed, usually some form of a fast Fourier analysis. From an analysis of the frequencies determined to be present, attempts were made to determine the identity of the word spoken. These techniques, although valid for some purposes, are generally extremely slow in execution, requiring considerable time to accomplish, even on high-speed computers. In addition, problems are encountered in distinguishing voice patterns of voices of significantly different base or natural frequencies, such as male and female voices, female and σhildrens' voices, and so forth.
BRIEF DESCRIPTION OF THE DRAWINGS
The invention is illustrated in the accompanying drawings in which:
FIG. 1 is a diagrammatic box-diagram of an apparatus for speaker independently determining unknown speech utterances, in accordance with the invention.
FIG. 2 is a flow chart illustrating the general or generic method for speaker independently determining unknown speech utterances in conjunction with the apparatus of FIG. 1, and in accordance with the invention. FIG. 3 is a silhouette of an acoustic waveform of the word
"zero"
FIG. 4 is a silhouette of an acoustic waveform of the word "one".
FIG. 5 is a silhouette of an acoustic waveform of the word "two".
FIG. 6 is a silhouette of an acoustic waveform of the word "three".
OMPI °
FIG . 7 is a silhouette of an acoustic waveform of the word
" four" .
FIG. 8 is a silhouette of an acoustic waveform of the word
"five". FIG. 9 is a silhouette of an acoustic waveform of the word "six".
FIG. 10 is a silhouette of an acoustic waveform of the word "seven".
FIG. 11 is a silhouette of an acoustic waveform of the word "eight".
And FIG. 12 is a silhouette of an acoustic waveform of the word "nine".
In the various figures of the drawings r the sizes, shapes and dimensions of the waveforms and frequencies have been exaggerated or distorted for clarity of illustration and ease of description.
SUMMARY OF THE INVENTION
In light of the above, it is, therefore, an object of the invention to provide a speaker-independent voice recognition apparatus and method.
It is another object of the invention to provide an apparatus and method of the type described which achieves word recognition with high speed and accuracy.
It is another object of the invention to provide an appara- tus and method of the type described which is essentially time domain based, not frequency domain based.
It is another object of the invention to provide an appara-
tus and method of the type described which does not require large amounts of computer memory to achieve a relatively sizeable voca¬ bulary recognition capability.
It is another object of the invention to provide an appara- tus and a method of the type described which can recognize words of speakers of significantly different pitch or natural frequen¬ cies such as male and female voices and the like.
It is another object of the invention to provide an appara¬ tus and a method of the type described which recognizes a relati- vely large vocabulary of words, speaker independently, with a high degree of accuracy.
It is another object of the invention to provide an appara¬ tus and method of the type described which can be achieved with minimal hardware requirements and readily available computer capabilities.
These and other objects, features and advantages will become apparent to those skilled in the art from the following detailed description when read in conjunction with the accompanying drawings and dependent claims. In its broad aspect, the invention provides an apparatus and method for identifying voice utterances or words including the steps of generating the digitized signal representing the utterance, determining the features of the digital representation including the zero crossing frequencies, energy, zero crossing rates, grouping the determined features into vowel, consonant and syllable groups and identifying the grouped features.
In another aspect of the invention, the method includes the steps of companding the digitized signal to generate a complete decodeable signal representation of the utterance over the dyna-
-g3REΛ OMP WIPO
mic energy range of the signal to achieve increased accuracy of speaker independent voice recognition.
In still another aspect of the invention, the method for recognizing an unknown word or speech utterance as one of a pre- 5 defined set of words includes the steps of establishing at least one flag (feature indicator) which is set when a predefined utterance pattern is present in the unknown speech utterance. At least one signal representing the gross parameter of the unknown . utterance is established, and a plurality of signals representing 0. fine parameters of predefined representations of the unknown utterance are also established. The unknown speech utterance is tested to determine whether to set the flag, and the gross para¬ meter representing the signal is determined. The predefined set of words is searched to identify at least one of them which is 5 characterized by at least the utterance pattern indicated by the set flag, if any, and by at least the gross parameter indicated by the gross parameter indicating signal. Finally, it is deter¬ mined whether the set of identified features associated with the unknown word are adequate to identify the word.
0 Detailed Description of the Preferred Embodiments
The voice control recognition system, in accordance with a preferred embodiment of the invention, is achieved with both hardware and software requirements presently defined. It should be emphasized that the apparatus and method herein described 5 achieves speaker-independent voice recognition as a time-domain process, without regard to frequency-domain analysis. That is, no complicated orthogonal analysis or fast Fourier transformed analysis are used, thereby enabling rapid, real time operation of
OMPI
the system. It should be noted that in some instances frequency analysis may be useful or necessary; however, in the system herein described, the time-domain processes are sufficient. Thus, as shown in FIG. 1, a system 10 utilizes a central pro- 5 cessing unit (CPU) 11 in conjunction with other hardware elements to be described. The CPU 11 can be any general purpose appropriately programmed computer, and, in fact, can be a CPU portion of any widely available home computer, such as those sold by IBM, APPLE, COMMODORE, RADIO SHACK, and other vendors. A 10 memory element 12 is in data and control communication with the
CPU 11. The control and data software is contained in the memory element 12, and is described generally and in detail below. An output device 15 is provided to convert the output signal generated by the CPU 11 to an appropriate useable form. In the 15 embodiment shown in FIG. 1, for instance, the output of the apparatus 10 is delivered to a CRT screen 16 for display; con¬ sequently, the output box 15 in the embodiment illustrated will contain appropriate data decoders and CRT drivers, as will be apparent to those skilled in the art. Also, it will be apparent 20. to those skilled in the art that many other output utilization devices can be equally advantageously employed. For instance, by way of example and not limitation, robots, data receivers for flight control apparatuses, automatic banking devices, and the like may be used. Diverse utilization application devices will 25 be clearly apparent to those skilled in the art.
At the data input port of the CPU 11, a bandpass filter 20, an analog-to-digital (A/D) and companding circuitry 21 are pro¬ vided. The companding operation provided by the A/D and com¬ panding circuitry 21 enables a wide, dynamic energy range of
OMPI
input signals to be processed.
Finally, in the embodiment illustrated, a microphone or other speech-receiving apparatus 23 is provided into which a speech utterance made by a person 24 is received and applied to the CPU 11 via the bandpass filter 20 and A/D in companding cir¬ cuitry 21.
Within the memory element 12 is contained a number of com¬ puter programs and word data, described below in detail. Briefly, a control algorithm portion 27 of the memory is provided in which the various machine CPU operational steps are contained. Also contained in the memory element 12 is a word buffer 28 as well as a portion for various data tables developed by the control algorithm 27 from the received utterance delivered to the CPU 11. The detailed characteristic portion are contained in the area 29. Five summary table parameters, denoted "HZ", "EH",
"HV", "ZF" and "AHZ" are in the areas 33 of the memory element 12. A number of flags 35 are contained in the memory element 12 as well as data defining various word parameters for particular words to be recognized 36. As shown, for example, the words "yes", "no", "stop", "begin", "up", "backward", "down", "left", "right", "forward", etc., etc., "zero", "one", "two", "three", "four", "five", "six", "seven", "eight", "nine", etc., etc., are contained.
It should be noted that although different block areas are shown for the various described software within the memory ele¬ ment 12, the blocks shown are symbolic only and that the data and machine instructions within the memory element 12 can be resident at any memory location accessible in accordance with known data
processing and handling techniques. The blocks are shown merely by way of pictoralizing the electronic signals contained within the hardware memory element 12.
Thus, in general, with reference to FIG. 1, when a word is
•*■ spoken by a speaker 24, such as the word "seven" indicated, it is received by the microphone 23, which produces an analog signal on the output line '40. The analog signal is applied to a bandpass filter 20, then to the A/D and companded circuitry 21 where it is digitized and companded. The bandpass filter and A/D compander 21 may be of any commercial available bandpass, A/D and com¬ panding circuits, an example of which are, respectively, an MK5912 and MK5116, provided by Mostek Corporation of Dallas, Texas. In the embodiment illustrated, the companding circuitry 21 follows the u-255 Law Companding Code. The signal received along the path including the microphone 23, bandpass filter 20 and A/D and companding circuitry 21 continuously receives and applies a signal to the CPU 11 which, under the control of the control algorithm 27 in the memory element 12, examines or deter¬ mines when the signal represents a speech utterance or, as referred to herein, a word. When a word is detected, the detailed characteristic data tables 29 and summary tables 33 are developed, as well as the various flags 35. The wordset 36 is then examined, and wordsubsets determined, both of possible can¬ didates for the word to be detected and also sets of words which are not the word to be detected. The characteristics of the received word are then further refined and the word selection/elimination process is continued until the final word is selected, or until no word is selected. When the word is determined, or a determination is made that the word is not
recognized, the CPU develops an output to the output device 15, either directly on line 45 or indirectly via the A/D and com¬ panding circuitry 21 on line 46 for application to the output utilization device, in the embodiment illustrated, the television or CRT display 16. It should be noted that the A/D and com¬ panding circuitry 20 includes a decoder circuit so that if desired, the unknown word can be decoded and applied in analog form to the output device 15 for application to a speaker (not shown) or the like for verification. More particularly, the steps for determining the word or other speech utterance are shown in box-diagram form in FIG. 2 as shown initially, the unknown word 50, in analog form, is digi¬ tized and companded, box 52. In analyzing a particular speech utterance, one of the problems encountered is the enormous, dyna- mic energy range over which the utterance may extend. Thus, although the human ear is particularly adapted for detecting subtle nuances of volume or intensity of sounds in human speech recognition, machines or apparatuses used in the past do not have such dynamic range readily available. In the past, especially in speech recognition apparatuses of the type in which the unknown speech utterance is first digitized before being processed, ordi¬ narily, a considerable amount of identification information is lost, either because the information is at such a low level as to not be detectable or because the information is at such a high level that the information is clipped or saturated within the apparatus and considered out of range. Thus,- in the past, the speech recognition circuits or apparatuses operated principally upon the middle energy values of the signal being considered. The importance of retaining the entire voice signal to be decoded
has been recognized in the telephone industry in which telephone signals are companded prior to their transmission over data transmission channels. By reverse operations, the companded signals can be uncompanded or decoded at a receiving terminal to enable the original signal to be recreated for the listener. To date, it is not believed that such companding techniques have been applied to voice recognition technology. Accordingly, as shown, in accordance with one aspect of. the invention, the signal to be recognized is first companded in the box indicated by the reference numeral 52. This enables the signal having low levels to be amplified so that the ordinarily recognizable low energy levels of the signal can be recognized, and, additionally, the high level portions of the signal can be preserved for appropriate processing.
By way of note, the term companding is recognized in the telecommunications art, one companding law being referred to, for example, is the u-255 Law Companding Code. The companding pro¬ cess in essence produces a signal having an output energy level which is nonlinearly related to the input signal level at high and low signal levels, and linearly related at the mid-range signal level values. The decoder has an appropriate inverse transfer function. As mentioned with reference to FIG. 1, the digitized and companded signal is applied to the CPU 11 con¬ tinuously, and as the various sounds and other background noises are received, the presence, if any, of a word or any other speech utterance is determined, box 53. Presently, the manner in which the start of an unknown word is determined is to monitor con¬ tinuously the signal output from the A/D and companding circuitry 21 and noting when the signal level exceeds a predetermined
level for a predetermined time. When this event occurs, a "word" is initially defined (although, as below described, if a major vowel is not found in the word, the development of the data representing the characteristics of the word is not completed) . It has been found that a level of approximately l/8th of the maximum anticipated signal level for about 45 milliseconds can be used to reliably determine the beginning of a signal having a higher probability of being an appropriate word to be recognized. Once the word is declared to have been started, a word length of 600 milliseconds is stored for analysis. Thus, the word to be recognized is defined to be contained in a window of 600 millise¬ cond. It will be appreciated that some words will occupy more time space of the 600 millisecond window than others, but the amount of window space can be, if desired, one of the parameters or characteristics used in including and excluding word patterns of the possible set of words which the unknown word could possibly be.
Thus, the signal detected at the input to the system is con¬ tinuously circulated through the unknown word buffer of the memory until the signal having the required level and duration occurs. At that time, the central processing unit 11 on an interrupt level begins the process of defining the word "window". The first step in defining the word "window" is to examine the data in the unknown word buffer 28 backwards in time until a silence condition is detected. From the point at which silence is detected, a 600 millisecond window is defined. It should be emphasized that during this time, once the beginning of the 600 millisecond window is defined, the various characteristic data tables are being generated, thus, enabling rapid, dynamic
processing of the unknown word.
Once the 600 millisecond word window has been defined, the window is divided into ten millisecond sections or frames, each frame containing a portion of the digitized word signal in the window. This is indicated in box 55.
With the word data thus defined sectioned and divided, five detailed word characteristic data tables are generated, box 56. An example of the detailed characteristic data tables of an unknown word "seven" to be recognized are set forth in Table 1 below. The detailed characteristic data tables represent the data in each of the 10 millisecond frames throughout the 600 millisecond word. It should be noted that the values stated in Tables 1-5 are hexadecimal values. The hexadecimal numbers are indicated herein by apparenthetical "H" (H) following the hexade- cimal number.
In accordance with the invention. Table 1 represents the number of zero crossings of the companded signal, each of the numbers in each frame representing the number of zero crossings of the signal in that particular frame. Thus, for example, in the table illustrated in the first ten milliseconds, there are thirtee (H) number of crossings of the companded signal. During the next ten milliseconds, there are fifteen(H) crossings. In the third ten millisecond frame there are also fiftee (H) zero crossing. In the fourth ten millisecond frame there are eighteen(H) zero crossings, and so forth.
Table 2 represents an energy-related value of the signal represented in each ten millisecond frame. The energy approxi¬ mation in accordance with the invention, is determined by the sum of the absolute value of the positive going signal excursions of
the companded signal in each frame multiplied times four. Thus, the value in the first ten millisecond frames is eight(H). The values in the second and third ten millisecond frames are A(H) and B(H), respectively . The value in the fourth ten millisecond
5 frames is D(H), and so on.
Table 3 represents in accordance with the invention, the value of the peak-to-peak maximum voltage of the companded signal in each of the respective ten millisecond frames. Thus, the peak-to-peak maximum voltage in the first three ten millisecond 10. frames is four(H). The value in the fourth ten millisecond frame is five(H) and the value in the fifth ten millisecond frame is five(H), and so on.
Table 4 is the number of major cycles contained in each of the ten millisecond frames. A major cycle is determined by the 15 number of cycles which exceed 50 percent of the maximum amplitude of the signal contained throughout the entire 600 millisecond word window. Thus, during the first two ten millisecond fra¬ mes, the number of major cycles is one(H). During the third ten millisecond frame, the number of major cycles is two(H). During 20 the fourth ten millisecond frame, the number of major cycles is five(H) , and so on.
Table 5 represents the absolute number of cycles contained within each ten millisecond frame. The absolute number of cycles contains both the number of major cycles, as set forth in 25 Table 4 as well as the lesser cycles, i.e., those having less than 50 percent of the amplitude of the signal contained in the 600 millisecond window. Thus, the first ten millisecond fra¬ me has a value of D(H). The second frame has a value of thirteen(H) and the third frame has a value of seventeen(H) , and
so on . 15
Once the detailed characteristic data tables of the unknown word are configured, box 56, in accordance with the. example Tables 1-5, a set of summary characteristic data tables of the unknown word are generated, box 59.
Summary Characteristic Data Table 6 includes four values. s
The four values are representative of: VST (Vowel Start) [frame 8(H)] VEN (Vowel End - Start of Second Syllable) [frame 1B(H)] VEN2 (End of Second Syllable) [frame 22(H)]
HW (Maximum Peak-to-Peak Voltage Over the First Syllable Vowel Area [frame FF(H)]
The vowel start frame is determined from the data contained in the detailed characteristic data table representing the peak- to-peak maximum voltage, Table 3. The method by which the vowel start is determined is by determining whether a predetermined peak-to-peak voltage value exists for a predetermined number of frames. For example, if 3/4ths of the maximum peak-to-peak value exists in six frames, a major vowel would appear to be present. From the point at which the first 3/4ths peak-to-peak value appears in the 600 millisecond word window, the previous word frames are examined to a point at which the voltage drop is at least l/8th of the peak-to-peak voltage value. Other methods for determining the vowel start can be used from the data in the • tables, for example, another method which can be used is to exa¬ mine the data preceeding the 3/4ths peak-to-peak value frame
_ until the voltage drops to l/4ths of the peak-to-peak maximum voltage value and a frequency shift occurs, as would be indicated from the detailed characteristic table setting forth the absolute
number of cycles. Table 5. In some instances, both methods may be desirably employed.
The vowel end (or start of the second syllable) frame is determined from an examination of the detailed characteristic data tables. More particularly, the detailed characteristic data table contain the energy related values, Table 2 , are examined to determine the vowel end. Thus, when the energy falls to a prede¬ termined level of energy for a predetermined number of frames , then the vowel end is defined. For example, if the energy falls to a value of 1/8th of the maximum energy for a period of about eight frames, the frame at which the energy falls to the l/8th level is defined as the vowel end.
At this point it should be noted that in the processing of the unknown word, to this point it was assumed that a word was in fact present. If it is determined at this point that no vowel start and vowel end values exist as determined by VST and VEN, defined as above described, the entire processing is discontinued with no further characteristic data tables being generated. If a major vowel is determined to be present, the generation of the summary characteristic data tables of the unknown word is con¬ tinued. If not, an output message is generated, box 64, indi¬ cating either "Please Repeat" or "Word Not Known" or other message indicating that the method and apparatus is unable to decipher the word. The end of the second syllable is determined from the detailed characteristic data tables in a fashion similar to the determination of the Vowel End (VEN) determination above described. The maximum peak-to-peak voltage over the entire sample is
determined directly from the data in Table 3, from which it can be seen that the largest value in the table is the value FKH) which occurs at frame 16.
The data in the summary characteristic data tables* 7, 8, and 9, are generated from grouped data from the detailed characteristic data tables 1-5. Thus, in the development of
Tables 7, 8, and 9, the word to be evaluated within the 6/10ths second window is divided into four sections, beginning with the vowel-start frame indicated by the parameter VST
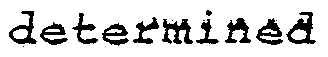 in Table 6 and ending with the vowel end frame, as indicated by the parameter VEN in Table 6. Thus, in the example shown, the vowel- start frame begins in frame D(H) and the vowel ends in frame 17(H). With the data thus determined in the examples shown, for instance, the first- l/4th of the divided data is contained in frames 13 to 15, the second l/4th is contained in frames 16 to
in Table 6 and ending with the vowel end frame, as indicated by the parameter VEN in Table 6. Thus, in the example shown, the vowel- start frame begins in frame D(H) and the vowel ends in frame 17(H). With the data thus determined in the examples shown, for instance, the first- l/4th of the divided data is contained in frames 13 to 15, the second l/4th is contained in frames 16 to
18, the third l/4th is contained in frames 19 to 21, and the last l/4th is contained in frames 22 to 23.
After the data in the detailed characteristic data tables has been thus divided into four equal sections, summary characteristic data tables 7, 8 and 9 are generated. Summary characteristic data table 7 is developed from the detailed characteristic data table presenting the approximate energy set forth in Table 2. The summary values listed in Table 7 are as follows: HZl - the average number of zero crossings of the companded signal in the first quarter of the frames beginning at the vowel start (VST) and ending at the end of the first vowel (VEN).
HZ2 - is the average number of zero crossings of the com¬ panded signal for the second and third quarters of the frames
OM
in the VST-VEN region of Table 1.
HZ3 - is the average number of zero crossings of the com¬ panded signal for the last quarter during the period VST-VEN. HZ4 - set forth in Table 7 is a post-end characteristic 5 which represents the average number of zero crossings of the com¬ panded signal beginning at a point after the end of the first vowel and includes the second syllable, if any. In the case illustrated, the values in this region is the "VEN" sound of the word "seven". JLO In similar fashion, a summary table of the average number of major cycles over the same one-quarter portions of the period between the vowel start (VST) and vowel end (VEN) is developed. Thus, HZF1 is the average number of major cycles in the first quarter, HZF2 is the average number of major cycles in the second 15 and third quarters, and HZF3 is the average number of major cycles in the fourth quarter, and HZF4 is the average number of major cycles in the post-end period.
Finally, a summary table is developed from the absolute number of cycles, set forth in Table 5, the summaries being set 20 forth in Table 9. The summaries set forth in Table 9 represent the average of the absolute number of cycles in the same one- quarter segments between the vowel start (VST) and vowel end (VEN) sections. Thus, HZAl represents the average of the abso¬ lute number of cycles in the first quarter, HZA2 represents the 25 average of the absolute number of cycles in the second and third quarters, HZA3 represents the average of the absolute number of cycles in the fourth quarter, and HZA4 represents the average of the absolute number of cycles in the post-end period.
With the detailed and summary characteristic tables thus
-- ΕE PI
generated, a number of special flags are determined. As set forth in box 60, the preliminary special flags are* set upon the existence of: a leading "s", a leading "t", a trailing "s", a trailing "t", a multiple syllable word, a second syllable empha- sized word, a trailing "p", a leading "f", a trailing "f", a leading "w", a possible leading "s", a possible leading "t", a possible trailing "s", a possible trailing "t", and a possible trailing "p".
As is known in the art, certain sounds are easily identified as having particular characteristics, such as a leading "p" or "t" which is characterized by an immediate rise in energy in an explosive manner, followed by a fairly pronounced period of silence. Thus, in the word "two", at the beginning of the word is a pronounced energy spike representing the formation of the "t" sound. Other letter sounds also have easily identifiable characteristics. Thus, by identifying initially the existence or possible existence of certain letters or letter sounds, imme¬ diately, classes of words can be eliminated as possible can¬ didates for identification of the word. An example is in distinguishing the sounds of the word "one" from the word "two" can be seen by a comparison of the energy values shown in FIGS. 4 and 5. The energy values of the word "one" has a relatively shallow leading edge building up to a peak-energy value. On the other hand, the word "two" has an explosive initial energy value, followed by a period of minimum energy, then the remaining word sounds completing the word after the initial "t" sound. Thus, in the identification of a sound having an initial energy burst as shown in FIG. 5 for the word "two", entire classes of words such as "one", "nine", "four", and such, can be eliminated as possible PI
candidates and other classes of words, such as "begin", "toward", and the like, can be selected or included as possible candidates.
This initial classification, as mentioned is accomplished by setting certain special flags. Thus, the specific flags that are
5. set will determine the remaining possible word candidates.
- ,. .The selection of word subsets is continued upon examination of the existence (or not) of the special flags set in box 60, as indicated by the boxes 65 and 66. Thus, after a determination of all of the selected words in the subset indicated by the
Iffi existence (or not) of these special flags, a condition exists in which a subset of possible words is selected, box 68. This selection is achieved by retrieving the known characteristic tables for the selected words, box 70, from a memory or ROM 71, and against which the data determined by the flags is compared.
I5:. In the example given, the data contained for the number 7, indi¬ cated by the boxed area 72 of the ROM 71 is retrieved, box 70, and against which the flags are compared.
Once the word subset is selected from the comparison of the special flags, box 63, a decision is made as to whether only one 0 word exists in the subset, diamond 75. If only one word exists, the word is immediately identified, box 76, and an output is generated, box 78, to display the word selected, as indicated by the number 7, indicated by the reference numeral 80.
3" In the event that more than one word is determined to be pre¬ sent in the selected word subset, boxes 60 and 75, the character¬ istics of the unknown word are compared to the characteristics known of the words in the selected subset, box 78. In the event that the word can be positively identified, it is identified in
box 76 and the output generated, box 78. On the other hand, in some cases, if a conflict is determined to exist, diamond 80, it may be possible to (reduce) the parameters of the comparison, box
81 and the comparison remade, box 82. If the word still cannot be determined after narrowing the parameters and recomparing the words, the word is not identified and the output message generated in box 64 can be sent to the screen indicating "Word
Not Known" or "Please Repeat".
With respect to the words contained in the vocabulary of the apparatus which can be recognized, one or more special charac¬ teristics can be defined. The characteristics which are defined depend primarily upon the type of characteristics necessary to recognize the word as well as distinguishing characteristics which distinguish the word from other words which may be in the system vocabulary. The greater the number of words in the vocab¬ ulary and the closer the number of words from which an unknown word must be distinguished, the greater the number of charac¬ teristics which must be included and examined before an unknown word can be identified. As an example, the word "six" can have six different characteristics by which the word "six" is deter¬ mined when the included vocabulary against which it is compared includes only the numbers 0 through 9 and not words which are of close sound, such as the words "sex", "socks", "sucks", etc. The six numerically distinguishing characteristics are: (1) a leading "s" must be present (leading "s" flagset);
(2) the vowel must be connected to the leading "s" [compare, for instance, the word "stop" in which the vowel must not be con¬ nected to the leading "s"];
(3) the vowel must be a high-frequency vowel (determined from
tables 1 and 5 } ; 22
(4) a period of total silence of between 20 and 120 millise¬ conds must exist after the major vowel;
(5) the energy of the vowel must be maintained to the period of silence with a relatively fast drop; and
(6) the post-end characteristic must be of low amplitude with a high frequency tail of hydration, for example, greater than 30 milliseconds.
As will be apparent to those skilled in the art, other characteristics can be developed, depending upon the vocabulary which is in the system. Additional characteristics can be readily accomplished using the detailed and summary Tables 1-9 as above defined. For instance, if the word "six" were to be distinguished from the word "socks", the characteristics of the vowel must be examined. It can be seen that a frequency dif¬ ference exists between the vowel sounds of the two words which would be apparent from an examination of the number of zero crossing of the companded signal, Table 1 and the absolute number of Les, Table 5. The high-frequency, high-sound would be appare* acause the absolute number of cycles would be signi¬ ficantly higher than the number of zero crossings of the com¬ panded signal which tends to fill with the high-frequency components. Thus, if the values of the frames of Table 5 were higher than the values of Table 1, the unknown word would more likely be "six" rather than "socks".
Again it should be emphasized that although a number of characteristics for each word may be defined, it is not necessarily true that all of the characteristics must be positi-
vely identified before the word can be positively known. For instance, again using the word "six" with reference to the flow chart of Figure 2, again assuming only a numerical vocabulary in the system, once a leading and trailing "s" flag is set in box 5* 60, the selected word subset determined in box 65 would select only the one word "six" in which case no additional comparison need be made and the word can be positively identified. On the other hand, assuming that a conflicting word such as "socks" were to be contained in the vocabulary, additional comparisons would 0 necessarily need to be made in box 78 to determine the' distinc¬ tion between the word "six" and "socks".
Using the example "seven" illustrated, again assuming a numerical vocabulary in the system, if the leading "s" and multiple-syllable flags are set in box 60, again only one word would be selected in box 68 enabling the word "seven" to be generated at the output, box 78. In some instances, however, it may be desirable for some dialect which are desired to be recognized, to define the word "zero" to be recognized when it is pronounced "sero" or "cero". If the word "zero" is so defined, it can be seen that merely the setting of the leading "s" and multiple-syllable flags in box 60 would result in two words being selected as possible candidates for the unknown word in box 68. Thus, the vowel sounds of the unknown word would necessarily need to be examined before a final word could be chosen to be out- putted from the system, in the manner above described.
In summary, it is believed that by recognition of the possi¬ bility of developing data tables representative of the number of zero crossings of the companded signal, the approximated energy, peak maximum voltage, and the absolute number of cycles, enables
data to be generated by which word characteristics can be defined to enable words to be recognized independently of the speaker. It can further be seen that compensation for different dialects such as southern, eastern, mid-western, even foreign, can be 5 taken into account to enable the words to be effectively distinguished from other words in pre-defined vocabulary. Additionally, because the word selection is done by means of logical selection or exclusion of possible word subsets, the system can be operated essentially in real time since the speed
J.Q of word identification is not dependent upon the speed against which each word in the vocabulary is compared.
From an inspection of the silhouettes of acoustic wave forms of the numbers 0-9 and respective Figures 3-12, it can be seen that different distinguishing characteristics of each word can be
15 defined using the detailed data Tables 1-5, in the manner above described. Again, the issue to be determined in each particular system is that of determining the number of characteristics of a particular unknown word which must be identified before the word can be identified. The issue is determined principally by the
2Q number of similar words in the vocabulary, as is apparent from the discussion above.
Although the invention has been described and illustrated with a certain degree of particularity, it is understood that the present disclosure has been made by way of example only, and that
25 numerous changes in the combination and arrangement of parts may be re-examined to by those skilled in the art without departing from the spirit and the scope of the invention as hereinafter claimed.
25 TABLE 1
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
HZ 13 15 15 18 15 18 19 19 17 19 18 1A 13 OC OE 10 OF OC OF 10 11 OC OF 11 13 OA 06 07 06 OD 10 10 OF 10 11 OF 11 10 OC 08 04 05 06 04 06 06 04 05 06 04 09 06 08 03 02 00 00 00 00 00
TABLE 2
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
EH 08 OA OB OD OB OD OF OE OB OB OD OD 09 08 13 IF ID 1A IF ID ID 1C 19 18 10 05 02 02 03 OB 12 11 11 11 OF OE 11 10 08 04 02 02 03 02 03 02 01 02 02 02 04 03 02 00 00 00 00 00 00 00
TABLE 3
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
HV 04 04 04 05 05 05 06 04 04 04 05 05 05 49 A2 C8 Fl EB DC DC
DC E6 D8 6B 18 07 04 04 OE 31 53 54 4E 44 2F 2D 27 24 ID OA
09 08 07 07 06 06 05 05 04 05 07 06 04 03 01 00 00 00 00 00
TABLE 4
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
HZF 01 01 02 05 03 02 07 05 03 02 02 05 04 06 07 OE OE 09 OB 09 09 OA OB OA OB 03 02 02 02 05 07 07 08 07 07 08 09 OA 04 03 01 02 02 01 02 02 01 02 02 01 02 02 01 00 00 00 00 00 00 00
TABLE 5
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
ABHZ OD 13 17 18 13 19 19 18 13 15 15 17 15 OE 14 17 13 10 14 14
14 14 14 14 14 OF 09 OE OF 10 11 12 13 14 16 14 16 16 OE OD
08 OB OA 08 09 08 06 07 07 05 10 08 OE 08 01 00 00 00 00 00
TABLE 6 VST VEN VEN2 HW
OD 17 19 Fl
-glJfEX^ OMPI
26 TABLE 7
HZ1 HZ2 HZ3 HZ4
OD OE OE 11
TABLE 8
HZFl HZF2 HZF3 HZF4
06 08 OA OA
TABLE 9
HZAl HZA2 HZA3 HZA4 11 13 14 14
OMPI
Claims
lAl i 2 7
1 1. A method for recognizing an unknown speech utterance as
2 one of a predefined set of words, comprising:
3 establishing a plurality of signals representing detailed
4 parameters of predefined characteristics of said unknown •5 utterance,
6 establishing from said detailed parameter indicating signals
7 at least one flag signal which is set when a predefined utterance
8 pattern is present in said unknown utterance,
9 searching said predefined set of words to identify at least
10 one which is characterized by at least one flag, and
11 selecting said at least one word as being the unknown speech
12 utterance.
1- 2. The method of claim 1 further comprising setting said at
2 least one flag when a predefined utterance pattern exists at a
3 leading portion of the unknown utterance.
1 3. The method of claim 1 comprising setting said at least
2 one flag when a predefined utterance pattern exists in a trailing
3 portion of the unknown utterance.
1 4. The method of claim 1 wherein at least two flag signals
2 are set, and further comprising setting said at least two flag
3 signals, respectively, when a predefined utterance pattern exists »4 at a leading portion of the unknown utterance and a trailing por-
5 tion of the unknown utterance.
1 5. The method of claim 1 further comprising establishing
2 from said detailed characteristics at least one summary parameter
S or said unxnown utterance.
1 6. The method of claim 5 wherein said summary parameter
2 indicates a time location within said utterance at which a vowel
3 start is located.
7. The method of any of claims 1, 2, 3, 4, or 5 wherein
2 said step of establishing a plurality of signal characteristics representing detailed parameters comprises: establishing a table of values representing the number of
5 zero crossings of a companded signal representing the unknown
6 speech utterance; establishing a table of values related to energy of the com- panded signal; establishing a table of values representing the peak-to-peak maximum voltage of the companded signal; establishing a table of values representing the number of cycles of the unknown speech utterance of greater than 50% of the maximum amplitude contained in the unknown speech utterance; and establishing a table of values representing the absolute number of cycles contained in the unknown speech utterance.
8. A method for recognizing an unknown speech utterance
2 from a predefined set of known words, comprising: determining at least one characteristic of said unknown
4 speech utterance,
5 determining a subset of known word candidates from the known
6 presence and absence of said at least one characteristic in the
7 words of said predefined set of known words,
8 determining at least another characteristic of said unknown
9 speech utterance, and
-ξUREA OMPI
I.Q determining the word to be recognized from said subset from
11 the presence and absence of said another characteristic within
12 the words of said subset.
1 9. In the method of recognizing an unknown speech utterance
2 of the type in which the unknown utterance is digitized and
3 applied to recognition circuitry, the improvement comprising com-
4 panding the signal to generate a complete decodeable digital
5 signal representation of the utterance over the dynamic energy
6 range of this signal.
1 10. A method for identifying voice utterances, comprising:
2 generating a digitized signal representing the voice
3 utterance,
4 determining the characteristics of the digital represen-
5 tation, including the number of zero crossings, energy, and zero 6*. crossing rates,
7 grouping the- determined featues into vowel, consonant, and
8 syllable groups, and
9 identifying the grouped features.
1 11. The method of claim 10 wherein said step of generating a
2 digitized signal comprises:
3 generating an electrical analog signal from the voice
4 utterance, and generating a companded digitized signal from the
5 analog signal.
1 12. The method of claims 10 or 11 wherein said step of iden-
2 tifying the grouped features comprises comparing the grouped
3. features to a predefined characteristic table, and selecting a
4 word from the feature table most nearly corresponding to the
5 features identified as being present.
1 13. The method of claim 12 further comprising establishing
2 said feature table by defining a recognition algorithm.
1 14. The method of claim 10 further comprising the step of
2 providing an output indication to an external device.
1 15. The method of claim 10 further comprising the steps of
2 providing a microphone to receive the voice utterances to produce
3 an anolog signal therefrom,
4 providing a bandpass filter to filter the signal produced by
5 the microphone to limit the bandwidth,
6 providing an analog digital and comanding circuit to receive
7 the output from the bandpass filter to produce a companded digi-
8 tal representation of the voice utterance.
1 16. In a method for recogizing an unknown speech utterance,
2 the method for determining the start of a recognizable utterance
3 comprising:
4 providing means for receiving an acoustic signal including
5 the unknown speech utterance;
6 continuously generating a digital signal representing said
7 acoustic signal;
8 providing a memory; θ- continually entering said digital signal into said memory;
10 determining when said digital signal exceeds a predefined
11 amplitude level for a predefined period of time;
1-2. upon the determination that the digitized signal has
13 exceeded the predefined amplitude for the predefined period,
1.4 discontinuing the entry of the digitized word into said memory, 15* determining a period of time preceeding the occurrence of
-ξtj-RE OMPI
said determination at which the digital representation of said digital signal represents essentially a silent condition of said acoustic signal, and measuring a predefined length of said memory, said prede- fined length containing said unknown speech utterance.
17. The method of claim 1 wherein said at least one flag represents the occurrence of a leading "s".
18. The method of claim 1 wherein the occurrence of at least one flag indicates the existence of a leading "t".
19. The method of claim 1 wherein the occurrence of said at least one flag indicates the existence of a trailing "p".-
20. The method of claim 1 wherein the setting of at least one flag indicates the occurrence of a leading "f".
21. The method of claim 1 wherein the setting of said at least one flag indicates the existence of a trailing "f".
22. The method of claim 1 wherein the setting of said flag indicates the existence of a leading "w".
23. The method of claim 1 wherein the setting of at least one flag indicates the existence of a possible leading "s".
24. The method of claim 1 wherein the setting of at least one flag indicates the existence of a possible leading "t".
25. The method of claim 1 wherein the setting of said at least one flag indicates the existence of a possible trailing
26. The method of claim 1 wherein the setting of said at least one flag indicates the existence of a possible trailing "p".
27. The method of claim 1 wherein the setting of said at least one flag indicates the existence of a multiple syllable word.
28. The method of claim 1 wherein the setting of said at least one flag indicates that said unknown speech utterance has the emphasis on the second syllable.
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/US1983/000750 WO1984004620A1 (en) | 1983-05-16 | 1983-05-16 | Apparatus and method for speaker independently recognizing isolated speech utterances |
| EP19830902050 EP0148171A1 (en) | 1983-05-16 | 1983-05-16 | Apparatus and method for speaker independently recognizing isolated speech utterances |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/US1983/000750 WO1984004620A1 (en) | 1983-05-16 | 1983-05-16 | Apparatus and method for speaker independently recognizing isolated speech utterances |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO1984004620A1 true WO1984004620A1 (en) | 1984-11-22 |
Family
ID=22175144
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US1983/000750 WO1984004620A1 (en) | 1983-05-16 | 1983-05-16 | Apparatus and method for speaker independently recognizing isolated speech utterances |
Country Status (2)
| Country | Link |
|---|---|
| EP (1) | EP0148171A1 (en) |
| WO (1) | WO1984004620A1 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5774851A (en) * | 1985-08-15 | 1998-06-30 | Canon Kabushiki Kaisha | Speech recognition apparatus utilizing utterance length information |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3499987A (en) * | 1966-09-30 | 1970-03-10 | Philco Ford Corp | Single equivalent formant speech recognition system |
| US3553372A (en) * | 1965-11-05 | 1971-01-05 | Int Standard Electric Corp | Speech recognition apparatus |
| US3940565A (en) * | 1973-07-27 | 1976-02-24 | Klaus Wilhelm Lindenberg | Time domain speech recognition system |
| US4335302A (en) * | 1980-08-20 | 1982-06-15 | R.L.S. Industries, Inc. | Bar code scanner using non-coherent light source |
-
1983
- 1983-05-16 WO PCT/US1983/000750 patent/WO1984004620A1/en unknown
- 1983-05-16 EP EP19830902050 patent/EP0148171A1/en not_active Withdrawn
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3553372A (en) * | 1965-11-05 | 1971-01-05 | Int Standard Electric Corp | Speech recognition apparatus |
| US3499987A (en) * | 1966-09-30 | 1970-03-10 | Philco Ford Corp | Single equivalent formant speech recognition system |
| US3940565A (en) * | 1973-07-27 | 1976-02-24 | Klaus Wilhelm Lindenberg | Time domain speech recognition system |
| US4335302A (en) * | 1980-08-20 | 1982-06-15 | R.L.S. Industries, Inc. | Bar code scanner using non-coherent light source |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5774851A (en) * | 1985-08-15 | 1998-06-30 | Canon Kabushiki Kaisha | Speech recognition apparatus utilizing utterance length information |
Also Published As
| Publication number | Publication date |
|---|---|
| EP0148171A1 (en) | 1985-07-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US4284846A (en) | System and method for sound recognition | |
| US4181813A (en) | System and method for speech recognition | |
| EP0691022B1 (en) | Speech recognition with pause detection | |
| Abdelatty Ali et al. | Acoustic-phonetic features for the automatic classification of fricatives | |
| US3770892A (en) | Connected word recognition system | |
| EP0109190A1 (en) | Monosyllable recognition apparatus | |
| JPH0376472B2 (en) | ||
| KR19990028694A (en) | Method and device for evaluating the property of speech transmission signal | |
| Ivanov et al. | Modulation Spectrum Analysis for Speaker Personality Trait Recognition. | |
| US4665548A (en) | Speech analysis syllabic segmenter | |
| US5995924A (en) | Computer-based method and apparatus for classifying statement types based on intonation analysis | |
| JPH0312319B2 (en) | ||
| JP2018180334A (en) | Emotion recognition device, method and program | |
| US3198884A (en) | Sound analyzing system | |
| Shareef et al. | Gender voice classification with huge accuracy rate | |
| De Mori | A descriptive technique for automatic speech recognition | |
| WO1984004620A1 (en) | Apparatus and method for speaker independently recognizing isolated speech utterances | |
| JP2996019B2 (en) | Voice recognition device | |
| David | Artificial auditory recognition in telephony | |
| KR20040047428A (en) | Apparatus and method of voice region detection | |
| CN111341298A (en) | Speech recognition algorithm scoring method | |
| Mufungulwa et al. | Enhanced running spectrum analysis for robust speech recognition under adverse conditions: A case study on japanese speech | |
| Gulzar et al. | An improved endpoint detection algorithm using bit wise approach for isolated, spoken paired and Hindi hybrid paired words | |
| Tien et al. | Speech Feature Extraction and Data Visualisation-Vowel recognition and phonology analysis of four Asian ESL accents | |
| Paudzi et al. | Evaluation of prosody-related features and word frequency for Malay speeches |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| AK | Designated states |
Designated state(s): JP US |
|
| AL | Designated countries for regional patents |
Designated state(s): DE FR GB SE |