US6191800B1 - Dynamic balancing of graphics workloads using a tiling strategy - Google Patents
Dynamic balancing of graphics workloads using a tiling strategy Download PDFInfo
- Publication number
- US6191800B1 US6191800B1 US09/132,856 US13285698A US6191800B1 US 6191800 B1 US6191800 B1 US 6191800B1 US 13285698 A US13285698 A US 13285698A US 6191800 B1 US6191800 B1 US 6191800B1
- Authority
- US
- United States
- Prior art keywords
- rendering
- tile
- tiles
- display device
- frame
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Lifetime
Links
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T15/00—3D [Three Dimensional] image rendering
- G06T15/005—General purpose rendering architectures
-
- G—PHYSICS
- G09—EDUCATION; CRYPTOGRAPHY; DISPLAY; ADVERTISING; SEALS
- G09G—ARRANGEMENTS OR CIRCUITS FOR CONTROL OF INDICATING DEVICES USING STATIC MEANS TO PRESENT VARIABLE INFORMATION
- G09G5/00—Control arrangements or circuits for visual indicators common to cathode-ray tube indicators and other visual indicators
- G09G5/36—Control arrangements or circuits for visual indicators common to cathode-ray tube indicators and other visual indicators characterised by the display of a graphic pattern, e.g. using an all-points-addressable [APA] memory
- G09G5/39—Control of the bit-mapped memory
- G09G5/393—Arrangements for updating the contents of the bit-mapped memory
Definitions
- the present invention generally relates to computer systems, and more particularly to the generation of computer graphics employing an improved method of balancing graphics workloads using multiple concurrent rendering processes to refresh the computer display, the method utilizing a novel tiling strategy.
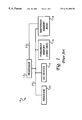
- Computer system 10 has at least one central processing unit (CPU) or processor 12 which is connected to several peripheral devices, including input/output devices 14 (such as a display monitor, keyboard, and graphical pointing device) for the user interface, a permanent memory device 16 (such as a hard disk) for storing the computer's operating system and user programs, and a temporary memory device 18 (such as random access memory or RAM) that is used by processor 12 to carry out program instructions.
- processor 12 communicates with the peripheral devices by various means, including a bus 20 or a direct channel 22 .
- Computer system 10 may have many additional components which are not shown, such as serial and parallel ports for connection to, e.g., modems or printers.
- Computer system 10 also includes firmware 24 whose primary purpose is to seek out and load an operating system from one of the peripherals (usually permanent memory device 16 ) whenever the computer is first turned on.
- GUI graphical user interface
- a generic application program entitled “Document Manager” is presented by the GUI as a primary application window (parent window) 26 on a display device 28 (i.e., video monitor).
- the application window has several secondary, enclosed windows (child windows) 30 , 32 and 34 which depict the contents of various files that are handled by the program.
- the file depicted in window 32 is a video animation (moving images).
- a menu bar 36 with a standard set of commands, a toolbar 38 , and a status bar 40 may be provided as part of the GUI, to simplify manipulation and control of the objects (e.g., text, charts and graphics) within the child windows, using a graphical pointer 42 which is controlled by a pointing device (mouse).
- objects e.g., text, charts and graphics
- a graphical pointer 42 which is controlled by a pointing device (mouse).
- the present invention is directed to a method of handling graphics workloads which are used by the computer system to repaint the screen.
- a computer program (including an operating system which is responsible for displaying a GUI) can be broken down into a collection of processes which are executed by the processor(s).
- the smallest unit of operation to be performed within a process is referred to as a thread.
- Threads allow multiple execution paths within a single address space (the process context) to run concurrently on a processor. This “multithreading” increases throughput in a multi-processor system, and provides modularity in a uni-processor system.
- a “rendering process” refers to either a thread of an application or a distinct application.
- “concurrent rendering processes” refers to two or more threads of an application, two or more applications on the same system, two or more applications on different systems, or a combination of these, all rendering portions of an image (concurrent rendering processes can be distributed among several processes in a cluster).
- One possible way in which the work may be distributed among the available rendering processes is to subdivide the display into multiple rectangular regions, or tiles, and then assign one or more tiles to a process. While this simple technique does distribute the work to the available processes, it may not be optimal in the sense that each process may or may not perform an equal share of the work.
- a window is divided vertically into right and left sides (only two tiles). If an object (image) is rendered in the center of the window, then the workload will be approximately equal between the two tiles, but if the object is located in the right tile then the process associated with this tile will do all the work leaving the process associated with the left tile with very little work to perform.
- a common approach to solving this workload distribution problem is to simply subdivide the window into a large number of fixed size tiles, and then assign to each rendering process a set of several tiles which are distributed over the entire window.
- the set of tiles is determined in a static manner (i.e., according to a predetermined function).
- the expectation with this approach is that, no matter where an object is placed, the rendering workload will be distributed relatively equally among the rendering processes.
- the workload will become more evenly distributed with this approach.
- this strategy can be effective, it can also lead to a great deal of complexity in designing a graphics subsystem in which a single process can efficiently render multiple tiles, due to the additional burden of managing multiple tiles. This overhead burden can adversely affect graphics generation, wiping out any performance gains that might otherwise be achieved using tiling.
- a method of generating graphic images on a display device of a computer system generally comprising the steps of dividing the viewable area of the display device into a plurality of tiles, assigning each of the tiles to a respective one of a plurality of rendering processes, rendering a frame on the display device using the respective rendering processes, and adjusting the sizes of at least two of the tiles in response to the rendering step.
- the method then uses the adjusted tile sizes to render the next frame with the respective rendering processes. In certain situations, it may be desirable to constrain the tile areas from becoming too small, in which case they are assigned a predetermined minimum value.
- the adjusted tile sizes may optionally be smoothed, such as by averaging in weighted sizes from previous frames.
- the tile sizes are adjusted by measuring the rendering times required for each rendering process to complete a respective portion of the frame, and then resizing the tiles based on the measured rendering times.
- FIG. 1 is a block diagram of a conventional computer system
- FIG. 2 is an illustration of a computer display showing a conventional graphical user interface (GUI) having various windows for viewing different multimedia content, such as text, graphics, and video animation;
- GUI graphical user interface
- FIGS. 3A-3C are illustrations of a computer display showing how the viewable area of the display is divided into three vertical tiles to generate graphic images, and how the tiles are dynamically resized, in accordance with a simplified implementation of the present invention.
- FIG. 4 is a chart depicting logic flow according to the method of the present invention for dynamically balancing graphics workloads using the tiling strategy illustrated in FIGS. 3A-3C.
- the present invention is directed to a data processing system which speeds up generation of graphic images by utilizing multiple concurrent rendering processes to refresh a video display.
- the invention is particularly advantageous when performing animation on a computer display.
- the computer system's hardware may include the various components shown in FIG. 1, but the computer system is not necessarily conventional, i.e., it could include new hardware components as well, or have a novel interconnection architecture for existing components. Therefore, while the present invention may be understood with reference to FIG. 1, this reference should not be construed in a limiting sense.
- the method of the present invention may further be adapted for use with existing operating systems such as OS/2 (a trademark of International Business Machines Corp.) or Windows 98 (a trademark of Microsoft Corp.).
- the present invention introduces the concept of dynamically balancing graphics workloads among the available rendering processes, by subdividing the window or display into multiple rectangular regions or tiles, assigning a single tile to each rendering process, and then distributing the workload by adjusting the tile size so that each process gets approximately equal amounts of work to perform.
- this technique is particularly advantageous for use in an application performing some type of animation sequence which requires high frame rates.
- the illustrative embodiment assumes some degree of communication/collaboration between the rendering processes.
- FIG. 3A depicts a graphical user interface (GUI) 50 which is generated using the novel tiling strategy of the present invention.
- GUI 50 is presented on a display device 52 of the computer system, and may include standard features such as the menu bar 54 , toolbar 56 , status bar 58 , and graphical pointer 60 .
- a preselected number of tiles are evenly arranged to construct the GUI.
- three vertical tiles of generally equal size are shown by the dashed lines forming a grid in FIG. 3 A.
- Each of the tiles is assigned to a respective rendering process.
- FIG. 3A also depicts a champagne bottle which is being opened (uncorked) in a video animation window 62 . In this initial frame, the bottle is shown fully corked.
- the cork of the champagne bottle has been moved to the lip of the bottle.
- the sizes of the tiles have also been adjusted dynamically based on the amount of work that was performed in advancing to the second frame. Since the primary movement was the cork, the tile to the left of the cork has enlarged to include a portion of the cork, so as to divide up the job of rendering the cork motion between two tiles (the left and center tiles).
- the tile to the right of graphical pointer 60 (which was also moved slightly by the user) has also been enlarged to include the graphical pointer. This adjustment of the tile sizes begins to balance out the workloads between the processes handling the respective tiles.
- the cork of the champagne bottle has exited the bottle and champagne is splashing out.
- the sizes of the tiles have again been adjusted, with the center tile shrinking even smaller to include the central portion of the splashing champagne, and the changing number in the elapsed time field.
- FIGS. 3A-3C conceptually illustrate an overly simplified, specific example of how the present invention may be implemented. More generally, the technique may be applied to any number of tiles with more complicated restructuring of the tile sizes (and not necessarily limited to vertical tiles).
- the method is accomplished by having each process update its tile geometry/size and measure the time required to render its portion of the image. Based on the current tile configurations and rendering times, new tile sizes are calculated.
- the new tile configurations may be smoothed using a weighted average technique to minimize oscillations in the solution, as explained further below. Finally, the procedure is repeated as each process again updates its tile geometry/size, and measures the latest time required to render its portion of the new image.
- the innovative feature of the proposed solution focuses on continuously updating the tile geometries so that the work is distributed equally among the processes and maximum scalability is achieved as additional processes are added. This requires solving the following problem.
- a window of total area A The window is subdivided into a series of non-overlapping tiles a( 1 ), a( 2 ), a( 3 ), . . . , a(N), where N is some integer greater than 1. It is assumed for this implementation that each rendering process is assigned to only one tile.
- the following expression for the total window area A is then obtained in terms of the individual tiles:
- This condition describes the situation in which all of the rendering process are each performing an equal amount of work. To solve these equations a relationship is needed between the rendering times and the tile areas. This relationship is developed by utilizing the information from the last rendered frame in the animation sequence, as follows:
- a_last(i) and t_last(i) are the tile area and the rendering time respectively for the i-th tile from the last rendered frame.
- Eqs. 1-3 may require resorting to a numerical solution technique.
- an approximate solution may be employed by first using Eq. 5 to obtain the initial unconstrained solution. If a tile is found with an area less than A_Minimum, then this tile area is set to A_Minimum, and in turn all the other tile areas are proportionately reduced so that Eq. 1 still applies. This procedure may have to be repeated numerous times as needed for any additional tiles which satisfy Eq. 6.
- a_avg [ w ( 0 )* a ( j )]+[ w ( 1 )* a ( j ⁇ 1)]+[ w ( 2 )* a ( j ⁇ 2)]+ . . . +[ w ( M )* a ( j ⁇ M )] (Eq. 7)
- a_avg is the averaged tile area
- M is the number of previous frames used in the averaging
- a(j) is the current solution for the i-th tile from Eq. 5
- a(j ⁇ 1) is the i-th tile for at the j ⁇ 1 animation frame
- a(j ⁇ 2) is the i-th tile for at the j ⁇ 2 animation frame
- so on for the remaining animation frames.
- each w(i) is a weighing factor.
- a_avg W*a ( j )+[(1 ⁇ W )* a ( j ⁇ 1)] (Eq. 9)
- FIG. 4 is a flow chart which summarizes the basic logic carried out the by present invention.
- the first step is to initialize the tile settings ( 70 ). Suitable values for N (the total number of tiles) preferably range from 2 to 10. Each tile is updated one frame, and the various times that it takes for each tile to be rendered are measured ( 72 ). New tile sizes are then calculated, using Eqs. 5b and 5a, constrained by Eq. 6 ( 74 ). The new tile configurations are smoothed using the weighting of Eq. 7 ( 76 ). Once the final tile area values a(i) are known, the relative geometries are determined using standard topological techniques ( 78 ). The logic flow then returns to step 72 for repeated iterations.
- the technique described herein provides a novel load balancing technique for use when a graphics animation sequence is rendering by multiple processes utilizing a tiling strategy for work division.
- the unique aspect of the solution methodology consists of continuously monitoring the rendering times of each tile and then adjusting the tile size so the workload is distributed among the tiles into approximately equal amounts.
- a set of algebraic equations are described which distribute the workload in a near optimal fashion. These equations yield a simple closed form solution, as shown in Eq. 5. Performance measurements indicate rendering speed-ups of approximately 20% over a similar statically tiled solution are possible.
- the invention is particularly useful in rendering three-dimensional (3-D) graphic animation and when used in a multi-processor system where concurrent rendering processes can be distributed among several processes in a cluster.
Abstract
Description
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US09/132,856 US6191800B1 (en) | 1998-08-11 | 1998-08-11 | Dynamic balancing of graphics workloads using a tiling strategy |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US09/132,856 US6191800B1 (en) | 1998-08-11 | 1998-08-11 | Dynamic balancing of graphics workloads using a tiling strategy |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| US6191800B1 true US6191800B1 (en) | 2001-02-20 |
Family
ID=22455910
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US09/132,856 Expired - Lifetime US6191800B1 (en) | 1998-08-11 | 1998-08-11 | Dynamic balancing of graphics workloads using a tiling strategy |
Country Status (1)
| Country | Link |
|---|---|
| US (1) | US6191800B1 (en) |
Cited By (69)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20020145612A1 (en) * | 2001-01-29 | 2002-10-10 | Blythe David R. | Method and system for minimizing an amount of data needed to test data against subarea boundaries in spatially composited digital video |
| US6567092B1 (en) * | 1999-02-10 | 2003-05-20 | Microsoft Corporation | Method for interfacing to ultra-high resolution output devices |
| US20030169269A1 (en) * | 2002-03-11 | 2003-09-11 | Nobuo Sasaki | System and method of optimizing graphics processing |
| US20030195735A1 (en) * | 2002-04-11 | 2003-10-16 | Rosedale Philip E. | Distributed simulation |
| US20040025112A1 (en) * | 2002-08-01 | 2004-02-05 | Chasen Jeffrey Martin | Method and apparatus for resizing video content displayed within a graphical user interface |
| US20040104913A1 (en) * | 2001-12-21 | 2004-06-03 | Walls Jeffrey J. | System and method for automatically configuring graphics pipelines by tracking a region of interest in a computer graphical display system |
| US20040125111A1 (en) * | 2002-12-30 | 2004-07-01 | Silicon Graphics, Inc. | System, method, and computer program product for near-real time load balancing across multiple rendering pipelines |
| US20040196283A1 (en) * | 2000-05-01 | 2004-10-07 | Lewis Michael C. | Method and system for reducing overflows in a computer graphics system |
| US20040222994A1 (en) * | 2003-05-05 | 2004-11-11 | Silicon Graphics, Inc. | Method, system, and computer program product for determining a structure of a graphics compositor tree |
| US20050041031A1 (en) * | 2003-08-18 | 2005-02-24 | Nvidia Corporation | Adaptive load balancing in a multi-processor graphics processing system |
| US20050183017A1 (en) * | 2001-01-31 | 2005-08-18 | Microsoft Corporation | Seekbar in taskbar player visualization mode |
| US20050190190A1 (en) * | 2004-02-27 | 2005-09-01 | Nvidia Corporation | Graphics device clustering with PCI-express |
| US20050282538A1 (en) * | 2004-05-28 | 2005-12-22 | Marc Balon | Method and system for improving mobile radio communications |
| US7027072B1 (en) | 2000-10-13 | 2006-04-11 | Silicon Graphics, Inc. | Method and system for spatially compositing digital video images with a tile pattern library |
| EP1687732A2 (en) * | 2003-11-19 | 2006-08-09 | Lucid Information Technology Ltd. | Method and system for multiple 3-d graphic pipeline over a pc bus |
| US7092983B1 (en) | 2000-04-19 | 2006-08-15 | Silicon Graphics, Inc. | Method and system for secure remote distributed rendering |
| US7117136B1 (en) | 2000-08-18 | 2006-10-03 | Linden Research, Inc. | Input and feedback system |
| US20060232590A1 (en) * | 2004-01-28 | 2006-10-19 | Reuven Bakalash | Graphics processing and display system employing multiple graphics cores on a silicon chip of monolithic construction |
| US20060267991A1 (en) * | 2005-05-27 | 2006-11-30 | Preetham Arcot J | Antialiasing system and method |
| US20060267993A1 (en) * | 2005-05-27 | 2006-11-30 | James Hunkins | Compositing in multiple video processing unit (VPU) systems |
| US20060267988A1 (en) * | 2005-05-27 | 2006-11-30 | Hussain Syed A | Synchronizing multiple cards in multiple video processing unit (VPU) systems |
| US20060271717A1 (en) * | 2005-05-27 | 2006-11-30 | Raja Koduri | Frame synchronization in multiple video processing unit (VPU) systems |
| WO2006126092A2 (en) * | 2005-05-27 | 2006-11-30 | Ati Technologies, Inc. | Dynamic load balancing in multiple video processing unit (vpu) systems |
| US20060267990A1 (en) * | 2005-05-27 | 2006-11-30 | Rogers Philip J | Multiple video processor unit (VPU) memory mapping |
| US20060274073A1 (en) * | 2004-11-17 | 2006-12-07 | Johnson Philip B | Multiple graphics adapter connection systems |
| US7219308B2 (en) | 2002-06-21 | 2007-05-15 | Microsoft Corporation | User interface for media player program |
| US20070245021A1 (en) * | 2006-03-29 | 2007-10-18 | Casio Computer Co., Ltd. | Server apparatus and server control method in computer system |
| US7340547B1 (en) | 2003-12-02 | 2008-03-04 | Nvidia Corporation | Servicing of multiple interrupts using a deferred procedure call in a multiprocessor system |
| US20080088630A1 (en) * | 2003-11-19 | 2008-04-17 | Reuven Bakalash | Multi-mode parallel graphics rendering and display subsystem employing a graphics hub device (GHD) for interconnecting CPU memory space and multple graphics processing pipelines (GPPLs) employed with said system |
| US7372465B1 (en) | 2004-12-17 | 2008-05-13 | Nvidia Corporation | Scalable graphics processing for remote display |
| US20080117217A1 (en) * | 2003-11-19 | 2008-05-22 | Reuven Bakalash | Multi-mode parallel graphics rendering system employing real-time automatic scene profiling and mode control |
| US7383412B1 (en) | 2005-02-28 | 2008-06-03 | Nvidia Corporation | On-demand memory synchronization for peripheral systems with multiple parallel processors |
| US20080158236A1 (en) * | 2006-12-31 | 2008-07-03 | Reuven Bakalash | Parallel graphics system employing multiple graphics pipelines wtih multiple graphics processing units (GPUs) and supporting the object division mode of parallel graphics rendering using pixel processing resources provided therewithin |
| US20080284677A1 (en) * | 2005-12-06 | 2008-11-20 | Dolby Laboratories Licensing Corporation | Modular Electronic Displays |
| US7456833B1 (en) | 2005-06-15 | 2008-11-25 | Nvidia Corporation | Graphical representation of load balancing and overlap |
| US7477256B1 (en) | 2004-11-17 | 2009-01-13 | Nvidia Corporation | Connecting graphics adapters for scalable performance |
| US20090027402A1 (en) * | 2003-11-19 | 2009-01-29 | Lucid Information Technology, Ltd. | Method of controlling the mode of parallel operation of a multi-mode parallel graphics processing system (MMPGPS) embodied within a host comuting system |
| US20090096798A1 (en) * | 2005-01-25 | 2009-04-16 | Reuven Bakalash | Graphics Processing and Display System Employing Multiple Graphics Cores on a Silicon Chip of Monolithic Construction |
| US7522167B1 (en) | 2004-12-16 | 2009-04-21 | Nvidia Corporation | Coherence of displayed images for split-frame rendering in multi-processor graphics system |
| US7525549B1 (en) | 2004-12-16 | 2009-04-28 | Nvidia Corporation | Display balance/metering |
| US7525547B1 (en) | 2003-08-12 | 2009-04-28 | Nvidia Corporation | Programming multiple chips from a command buffer to process multiple images |
| US20090128550A1 (en) * | 2003-11-19 | 2009-05-21 | Reuven Bakalash | Computing system supporting parallel 3D graphics processes based on the division of objects in 3D scenes |
| US20090141033A1 (en) * | 2007-11-30 | 2009-06-04 | Qualcomm Incorporated | System and method for using a secondary processor in a graphics system |
| US7545380B1 (en) | 2004-12-16 | 2009-06-09 | Nvidia Corporation | Sequencing of displayed images for alternate frame rendering in a multi-processor graphics system |
| US7576745B1 (en) | 2004-11-17 | 2009-08-18 | Nvidia Corporation | Connecting graphics adapters |
| US20090208098A1 (en) * | 2008-02-15 | 2009-08-20 | Microsoft Corporation | Tiling and merging framework for segmenting large images |
| US7602395B1 (en) | 2005-04-22 | 2009-10-13 | Nvidia Corporation | Programming multiple chips from a command buffer for stereo image generation |
| US7616207B1 (en) | 2005-04-25 | 2009-11-10 | Nvidia Corporation | Graphics processing system including at least three bus devices |
| US7629978B1 (en) | 2005-10-31 | 2009-12-08 | Nvidia Corporation | Multichip rendering with state control |
| US20100110084A1 (en) * | 2002-11-27 | 2010-05-06 | Ati Technologies Ulc | Parallel pipeline graphics system |
| US7721118B1 (en) | 2004-09-27 | 2010-05-18 | Nvidia Corporation | Optimizing power and performance for multi-processor graphics processing |
| US20100153842A1 (en) * | 2008-12-12 | 2010-06-17 | Microsoft Corporation | Rendering source content for display |
| US7783695B1 (en) * | 2000-04-19 | 2010-08-24 | Graphics Properties Holdings, Inc. | Method and system for distributed rendering |
| US20100251175A1 (en) * | 2009-03-24 | 2010-09-30 | International Business Machines Corporation | Auto-positioning a context menu on a gui |
| US20100269043A1 (en) * | 2003-06-25 | 2010-10-21 | Microsoft Corporation | Taskbar media player |
| US20100289803A1 (en) * | 2009-05-13 | 2010-11-18 | International Business Machines Corporation | Managing graphics load balancing strategies |
| US8054314B2 (en) | 2005-05-27 | 2011-11-08 | Ati Technologies, Inc. | Applying non-homogeneous properties to multiple video processing units (VPUs) |
| US8134568B1 (en) | 2004-12-15 | 2012-03-13 | Nvidia Corporation | Frame buffer region redirection for multiple graphics adapters |
| US8212831B1 (en) | 2004-12-15 | 2012-07-03 | Nvidia Corporation | Broadcast aperture remapping for multiple graphics adapters |
| US8453056B2 (en) | 2003-06-25 | 2013-05-28 | Microsoft Corporation | Switching of media presentation |
| WO2013068498A3 (en) * | 2011-11-08 | 2013-08-15 | Telefonaktiebolaget L M Ericsson (Publ) | Tile size in video coding |
| US20130222395A1 (en) * | 2012-02-29 | 2013-08-29 | Joaquin Cruz Blas, JR. | Dynamic Splitting of Content |
| EP2674939A1 (en) * | 2012-06-11 | 2013-12-18 | QNX Software Systems Limited | Cell-based composited windowing system |
| US8994750B2 (en) | 2012-06-11 | 2015-03-31 | 2236008 Ontario Inc. | Cell-based composited windowing system |
| US9704212B2 (en) | 2013-02-07 | 2017-07-11 | Nvidia Corporation | System and method for image processing |
| US10026140B2 (en) | 2005-06-10 | 2018-07-17 | Nvidia Corporation | Using a scalable graphics system to enable a general-purpose multi-user computer system |
| GB2558885A (en) * | 2017-01-12 | 2018-07-25 | Imagination Tech Ltd | Graphics processing units and methods for subdividing a set of one or more tiles of a rendering space for rendering |
| US10937119B2 (en) * | 2018-03-15 | 2021-03-02 | Intel Corporation | Apparatus and method for virtualized scheduling of multiple duplicate graphics engines |
| US20230106345A1 (en) * | 2021-10-01 | 2023-04-06 | Sap Se | Printing electronic documents from large html screens |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5757385A (en) * | 1994-07-21 | 1998-05-26 | International Business Machines Corporation | Method and apparatus for managing multiprocessor graphical workload distribution |
| US5798770A (en) * | 1995-03-24 | 1998-08-25 | 3Dlabs Inc. Ltd. | Graphics rendering system with reconfigurable pipeline sequence |
| US5818469A (en) * | 1997-04-10 | 1998-10-06 | International Business Machines Corporation | Graphics interface processing methodology in symmetric multiprocessing or distributed network environments |
| US5852443A (en) * | 1995-08-04 | 1998-12-22 | Microsoft Corporation | Method and system for memory decomposition in a graphics rendering system |
| US6046752A (en) * | 1995-12-06 | 2000-04-04 | Intergraph Corporation | Peer-to-peer parallel processing graphics accelerator |
| US6052125A (en) * | 1998-01-07 | 2000-04-18 | Evans & Sutherland Computer Corporation | Method for reducing the rendering load for high depth complexity scenes on a computer graphics display |
-
1998
- 1998-08-11 US US09/132,856 patent/US6191800B1/en not_active Expired - Lifetime
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5757385A (en) * | 1994-07-21 | 1998-05-26 | International Business Machines Corporation | Method and apparatus for managing multiprocessor graphical workload distribution |
| US5798770A (en) * | 1995-03-24 | 1998-08-25 | 3Dlabs Inc. Ltd. | Graphics rendering system with reconfigurable pipeline sequence |
| US5852443A (en) * | 1995-08-04 | 1998-12-22 | Microsoft Corporation | Method and system for memory decomposition in a graphics rendering system |
| US6046752A (en) * | 1995-12-06 | 2000-04-04 | Intergraph Corporation | Peer-to-peer parallel processing graphics accelerator |
| US5818469A (en) * | 1997-04-10 | 1998-10-06 | International Business Machines Corporation | Graphics interface processing methodology in symmetric multiprocessing or distributed network environments |
| US6052125A (en) * | 1998-01-07 | 2000-04-18 | Evans & Sutherland Computer Corporation | Method for reducing the rendering load for high depth complexity scenes on a computer graphics display |
Non-Patent Citations (4)
| Title |
|---|
| A. Rockwood, K. Heaton, T. Davis, "Real-Time Rendering of Trimmed Surfaces", Computer Graphics, vol. 23, No. 3, Jul. 1989, pp. 107-116. * |
| R. Samanta et al., "Load Balancing for Multi-Project Rendering Systems", Proceedings 1999 Eurographics/SIGGRAPH Workshop on Graphics Hardware, 1999, pp. 107-116. * |
| S. Whitman, "A Task Adaptive Parallel Graphics Renderer", Proceedings of the 1993 Symposium on Parallel Rendering, 1993, pp. 27-34. * |
| T. Nguyen, & J. Zahorjan, "Scheduling Policies to Support Distributed 3D Multimedia Applications", Joint Intl Conf on Measurement & Modeling of Computer Sys, 1998, pp. 244-253. * |
Cited By (170)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6567092B1 (en) * | 1999-02-10 | 2003-05-20 | Microsoft Corporation | Method for interfacing to ultra-high resolution output devices |
| US7783695B1 (en) * | 2000-04-19 | 2010-08-24 | Graphics Properties Holdings, Inc. | Method and system for distributed rendering |
| US7092983B1 (en) | 2000-04-19 | 2006-08-15 | Silicon Graphics, Inc. | Method and system for secure remote distributed rendering |
| US20040196283A1 (en) * | 2000-05-01 | 2004-10-07 | Lewis Michael C. | Method and system for reducing overflows in a computer graphics system |
| US7117136B1 (en) | 2000-08-18 | 2006-10-03 | Linden Research, Inc. | Input and feedback system |
| US7027072B1 (en) | 2000-10-13 | 2006-04-11 | Silicon Graphics, Inc. | Method and system for spatially compositing digital video images with a tile pattern library |
| US20020145612A1 (en) * | 2001-01-29 | 2002-10-10 | Blythe David R. | Method and system for minimizing an amount of data needed to test data against subarea boundaries in spatially composited digital video |
| US7737982B2 (en) | 2001-01-29 | 2010-06-15 | Graphics Properties Holdings, Inc. | Method and system for minimizing an amount of data needed to test data against subarea boundaries in spatially composited digital video |
| US20080211805A1 (en) * | 2001-01-29 | 2008-09-04 | Silicon Graphics, Inc. | Method and System for Minimizing an Amount of Data Needed to Test Data Against Subarea Boundaries in Spatially Composited Digital Video |
| US7358974B2 (en) | 2001-01-29 | 2008-04-15 | Silicon Graphics, Inc. | Method and system for minimizing an amount of data needed to test data against subarea boundaries in spatially composited digital video |
| US7924287B2 (en) | 2001-01-29 | 2011-04-12 | Graphics Properties Holdings, Inc. | Method and system for minimizing an amount of data needed to test data against subarea boundaries in spatially composited digital video |
| US20050183017A1 (en) * | 2001-01-31 | 2005-08-18 | Microsoft Corporation | Seekbar in taskbar player visualization mode |
| US20040104913A1 (en) * | 2001-12-21 | 2004-06-03 | Walls Jeffrey J. | System and method for automatically configuring graphics pipelines by tracking a region of interest in a computer graphical display system |
| CN1317682C (en) * | 2002-03-11 | 2007-05-23 | 索尼计算机娱乐公司 | System and method of optimizing graphics processing |
| US6919896B2 (en) | 2002-03-11 | 2005-07-19 | Sony Computer Entertainment Inc. | System and method of optimizing graphics processing |
| US20030169269A1 (en) * | 2002-03-11 | 2003-09-11 | Nobuo Sasaki | System and method of optimizing graphics processing |
| WO2003077120A2 (en) * | 2002-03-11 | 2003-09-18 | Sony Computer Entertainment Inc. | System and method of optimizing graphics processing |
| WO2003077120A3 (en) * | 2002-03-11 | 2004-11-25 | Sony Computer Entertainment Inc | System and method of optimizing graphics processing |
| EP1662441A1 (en) * | 2002-03-11 | 2006-05-31 | Sony Computer Entertainment Inc. | System and method of optimizing graphics processing using tessellation |
| US8612196B2 (en) | 2002-04-11 | 2013-12-17 | Linden Research, Inc. | System and method for distributed simulation in which different simulation servers simulate different regions of a simulation space |
| US20030195735A1 (en) * | 2002-04-11 | 2003-10-16 | Rosedale Philip E. | Distributed simulation |
| US7219308B2 (en) | 2002-06-21 | 2007-05-15 | Microsoft Corporation | User interface for media player program |
| US20040025112A1 (en) * | 2002-08-01 | 2004-02-05 | Chasen Jeffrey Martin | Method and apparatus for resizing video content displayed within a graphical user interface |
| US7549127B2 (en) * | 2002-08-01 | 2009-06-16 | Realnetworks, Inc. | Method and apparatus for resizing video content displayed within a graphical user interface |
| US20100110084A1 (en) * | 2002-11-27 | 2010-05-06 | Ati Technologies Ulc | Parallel pipeline graphics system |
| EP1581908A4 (en) * | 2002-12-30 | 2008-05-28 | Silicon Graphics Inc | System, method, and computer program product for near-real time load balancing across multiple rendering pipelines |
| EP1581908A2 (en) * | 2002-12-30 | 2005-10-05 | Silicon Graphics, Inc. | System, method, and computer program product for near-real time load balancing across multiple rendering pipelines |
| US20040125111A1 (en) * | 2002-12-30 | 2004-07-01 | Silicon Graphics, Inc. | System, method, and computer program product for near-real time load balancing across multiple rendering pipelines |
| US6885376B2 (en) * | 2002-12-30 | 2005-04-26 | Silicon Graphics, Inc. | System, method, and computer program product for near-real time load balancing across multiple rendering pipelines |
| US20040222994A1 (en) * | 2003-05-05 | 2004-11-11 | Silicon Graphics, Inc. | Method, system, and computer program product for determining a structure of a graphics compositor tree |
| US7034837B2 (en) | 2003-05-05 | 2006-04-25 | Silicon Graphics, Inc. | Method, system, and computer program product for determining a structure of a graphics compositor tree |
| US20100269043A1 (en) * | 2003-06-25 | 2010-10-21 | Microsoft Corporation | Taskbar media player |
| US10261665B2 (en) | 2003-06-25 | 2019-04-16 | Microsoft Technology Licensing, Llc | Taskbar media player |
| US9275673B2 (en) | 2003-06-25 | 2016-03-01 | Microsoft Technology Licensing, Llc | Taskbar media player |
| US8453056B2 (en) | 2003-06-25 | 2013-05-28 | Microsoft Corporation | Switching of media presentation |
| US8214759B2 (en) | 2003-06-25 | 2012-07-03 | Microsoft Corporation | Taskbar media player |
| US7525547B1 (en) | 2003-08-12 | 2009-04-28 | Nvidia Corporation | Programming multiple chips from a command buffer to process multiple images |
| US20050041031A1 (en) * | 2003-08-18 | 2005-02-24 | Nvidia Corporation | Adaptive load balancing in a multi-processor graphics processing system |
| JP2007503059A (en) * | 2003-08-18 | 2007-02-15 | エヌビディア・コーポレーション | Adaptive load balancing for multiprocessor graphics processing systems |
| JP4691493B2 (en) * | 2003-08-18 | 2011-06-01 | エヌヴィディア コーポレイション | Adaptive load balancing for multiprocessor graphics processing systems |
| US20100271375A1 (en) * | 2003-08-18 | 2010-10-28 | Nvidia Corporation | Adaptive load balancing in a multi processor graphics processing system |
| US20060221087A1 (en) * | 2003-08-18 | 2006-10-05 | Nvidia Corporation | Adaptive load balancing in a multi-processor graphics processing system |
| US20060221086A1 (en) * | 2003-08-18 | 2006-10-05 | Nvidia Corporation | Adaptive load balancing in a multi-processor graphics processing system |
| US7075541B2 (en) | 2003-08-18 | 2006-07-11 | Nvidia Corporation | Adaptive load balancing in a multi-processor graphics processing system |
| US8077181B2 (en) | 2003-08-18 | 2011-12-13 | Nvidia Corporation | Adaptive load balancing in a multi processor graphics processing system |
| WO2005020157A1 (en) * | 2003-08-18 | 2005-03-03 | Nvidia Corporation | Adaptive load balancing in a multi-processor graphics processing system |
| US20070279411A1 (en) * | 2003-11-19 | 2007-12-06 | Reuven Bakalash | Method and System for Multiple 3-D Graphic Pipeline Over a Pc Bus |
| US20110072056A1 (en) * | 2003-11-19 | 2011-03-24 | Reuven Bakalash | Internet-based graphics application profile management system for updating graphic application profiles stored within the multi-gpu graphics rendering subsystems of client machines running graphics-based applications |
| US20080100629A1 (en) * | 2003-11-19 | 2008-05-01 | Reuven Bakalash | Computing system capable of parallelizing the operation of multiple graphics processing units (GPUS) supported on a CPU/GPU fusion-type chip and/or multiple GPUS supported on an external graphics card |
| US8085273B2 (en) | 2003-11-19 | 2011-12-27 | Lucid Information Technology, Ltd | Multi-mode parallel graphics rendering system employing real-time automatic scene profiling and mode control |
| US20080117217A1 (en) * | 2003-11-19 | 2008-05-22 | Reuven Bakalash | Multi-mode parallel graphics rendering system employing real-time automatic scene profiling and mode control |
| US20080117219A1 (en) * | 2003-11-19 | 2008-05-22 | Reuven Bakalash | PC-based computing system employing a silicon chip of monolithic construction having a routing unit, a control unit and a profiling unit for parallelizing the operation of multiple GPU-driven pipeline cores according to the object division mode of parallel operation |
| EP1687732A2 (en) * | 2003-11-19 | 2006-08-09 | Lucid Information Technology Ltd. | Method and system for multiple 3-d graphic pipeline over a pc bus |
| US20080122851A1 (en) * | 2003-11-19 | 2008-05-29 | Reuven Bakalash | PC-based computing systems employing a bridge chip having a routing unit for distributing geometrical data and graphics commands to parallelized GPU-driven pipeline cores during the running of a graphics application |
| US7777748B2 (en) | 2003-11-19 | 2010-08-17 | Lucid Information Technology, Ltd. | PC-level computing system with a multi-mode parallel graphics rendering subsystem employing an automatic mode controller, responsive to performance data collected during the run-time of graphics applications |
| US7796129B2 (en) | 2003-11-19 | 2010-09-14 | Lucid Information Technology, Ltd. | Multi-GPU graphics processing subsystem for installation in a PC-based computing system having a central processing unit (CPU) and a PC bus |
| US7796130B2 (en) | 2003-11-19 | 2010-09-14 | Lucid Information Technology, Ltd. | PC-based computing system employing multiple graphics processing units (GPUS) interfaced with the central processing unit (CPU) using a PC bus and a hardware hub, and parallelized according to the object division mode of parallel operation |
| US20080136825A1 (en) * | 2003-11-19 | 2008-06-12 | Reuven Bakalash | PC-based computing system employing a multi-GPU graphics pipeline architecture supporting multiple modes of GPU parallelization dymamically controlled while running a graphics application |
| US7961194B2 (en) | 2003-11-19 | 2011-06-14 | Lucid Information Technology, Ltd. | Method of controlling in real time the switching of modes of parallel operation of a multi-mode parallel graphics processing subsystem embodied within a host computing system |
| US20080165197A1 (en) * | 2003-11-19 | 2008-07-10 | Reuven Bakalash | Multi-GPU graphics processing subsystem for installation in a PC-based computing system having a central processing unit (CPU) and a PC bus |
| US20080165198A1 (en) * | 2003-11-19 | 2008-07-10 | Reuven Bakalash | Method of providing a PC-based computing system with parallel graphics processing capabilities |
| US8125487B2 (en) | 2003-11-19 | 2012-02-28 | Lucid Information Technology, Ltd | Game console system capable of paralleling the operation of multiple graphic processing units (GPUS) employing a graphics hub device supported on a game console board |
| US20080238917A1 (en) * | 2003-11-19 | 2008-10-02 | Lucid Information Technology, Ltd. | Graphics hub subsystem for interfacing parallalized graphics processing units (GPUS) with the central processing unit (CPU) of a PC-based computing system having an CPU interface module and a PC bus |
| EP1687732A4 (en) * | 2003-11-19 | 2008-11-19 | Lucid Information Technology Ltd | Method and system for multiple 3-d graphic pipeline over a pc bus |
| US8134563B2 (en) | 2003-11-19 | 2012-03-13 | Lucid Information Technology, Ltd | Computing system having multi-mode parallel graphics rendering subsystem (MMPGRS) employing real-time automatic scene profiling and mode control |
| US7944450B2 (en) | 2003-11-19 | 2011-05-17 | Lucid Information Technology, Ltd. | Computing system having a hybrid CPU/GPU fusion-type graphics processing pipeline (GPPL) architecture |
| US7940274B2 (en) | 2003-11-19 | 2011-05-10 | Lucid Information Technology, Ltd | Computing system having a multiple graphics processing pipeline (GPPL) architecture supported on multiple external graphics cards connected to an integrated graphics device (IGD) embodied within a bridge circuit |
| US20090027402A1 (en) * | 2003-11-19 | 2009-01-29 | Lucid Information Technology, Ltd. | Method of controlling the mode of parallel operation of a multi-mode parallel graphics processing system (MMPGPS) embodied within a host comuting system |
| US7800611B2 (en) | 2003-11-19 | 2010-09-21 | Lucid Information Technology, Ltd. | Graphics hub subsystem for interfacing parallalized graphics processing units (GPUs) with the central processing unit (CPU) of a PC-based computing system having an CPU interface module and a PC bus |
| US20080088630A1 (en) * | 2003-11-19 | 2008-04-17 | Reuven Bakalash | Multi-mode parallel graphics rendering and display subsystem employing a graphics hub device (GHD) for interconnecting CPU memory space and multple graphics processing pipelines (GPPLs) employed with said system |
| US7843457B2 (en) | 2003-11-19 | 2010-11-30 | Lucid Information Technology, Ltd. | PC-based computing systems employing a bridge chip having a routing unit for distributing geometrical data and graphics commands to parallelized GPU-driven pipeline cores supported on a plurality of graphics cards and said bridge chip during the running of a graphics application |
| US8284207B2 (en) | 2003-11-19 | 2012-10-09 | Lucid Information Technology, Ltd. | Method of generating digital images of objects in 3D scenes while eliminating object overdrawing within the multiple graphics processing pipeline (GPPLS) of a parallel graphics processing system generating partial color-based complementary-type images along the viewing direction using black pixel rendering and subsequent recompositing operations |
| US20090128550A1 (en) * | 2003-11-19 | 2009-05-21 | Reuven Bakalash | Computing system supporting parallel 3D graphics processes based on the division of objects in 3D scenes |
| US7800610B2 (en) | 2003-11-19 | 2010-09-21 | Lucid Information Technology, Ltd. | PC-based computing system employing a multi-GPU graphics pipeline architecture supporting multiple modes of GPU parallelization dymamically controlled while running a graphics application |
| US8754894B2 (en) | 2003-11-19 | 2014-06-17 | Lucidlogix Software Solutions, Ltd. | Internet-based graphics application profile management system for updating graphic application profiles stored within the multi-GPU graphics rendering subsystems of client machines running graphics-based applications |
| US7800619B2 (en) | 2003-11-19 | 2010-09-21 | Lucid Information Technology, Ltd. | Method of providing a PC-based computing system with parallel graphics processing capabilities |
| US20090179894A1 (en) * | 2003-11-19 | 2009-07-16 | Reuven Bakalash | Computing system capable of parallelizing the operation of multiple graphics processing pipelines (GPPLS) |
| US9584592B2 (en) | 2003-11-19 | 2017-02-28 | Lucidlogix Technologies Ltd. | Internet-based graphics application profile management system for updating graphic application profiles stored within the multi-GPU graphics rendering subsystems of client machines running graphics-based applications |
| US7812846B2 (en) | 2003-11-19 | 2010-10-12 | Lucid Information Technology, Ltd | PC-based computing system employing a silicon chip of monolithic construction having a routing unit, a control unit and a profiling unit for parallelizing the operation of multiple GPU-driven pipeline cores according to the object division mode of parallel operation |
| US7808499B2 (en) | 2003-11-19 | 2010-10-05 | Lucid Information Technology, Ltd. | PC-based computing system employing parallelized graphics processing units (GPUS) interfaced with the central processing unit (CPU) using a PC bus and a hardware graphics hub having a router |
| US7340547B1 (en) | 2003-12-02 | 2008-03-04 | Nvidia Corporation | Servicing of multiple interrupts using a deferred procedure call in a multiprocessor system |
| US7812845B2 (en) | 2004-01-28 | 2010-10-12 | Lucid Information Technology, Ltd. | PC-based computing system employing a silicon chip implementing parallelized GPU-driven pipelines cores supporting multiple modes of parallelization dynamically controlled while running a graphics application |
| US7808504B2 (en) | 2004-01-28 | 2010-10-05 | Lucid Information Technology, Ltd. | PC-based computing system having an integrated graphics subsystem supporting parallel graphics processing operations across a plurality of different graphics processing units (GPUS) from the same or different vendors, in a manner transparent to graphics applications |
| US7812844B2 (en) | 2004-01-28 | 2010-10-12 | Lucid Information Technology, Ltd. | PC-based computing system employing a silicon chip having a routing unit and a control unit for parallelizing multiple GPU-driven pipeline cores according to the object division mode of parallel operation during the running of a graphics application |
| US8754897B2 (en) | 2004-01-28 | 2014-06-17 | Lucidlogix Software Solutions, Ltd. | Silicon chip of a monolithic construction for use in implementing multiple graphic cores in a graphics processing and display subsystem |
| US7834880B2 (en) | 2004-01-28 | 2010-11-16 | Lucid Information Technology, Ltd. | Graphics processing and display system employing multiple graphics cores on a silicon chip of monolithic construction |
| US20060279577A1 (en) * | 2004-01-28 | 2006-12-14 | Reuven Bakalash | Graphics processing and display system employing multiple graphics cores on a silicon chip of monolithic construction |
| US20080129745A1 (en) * | 2004-01-28 | 2008-06-05 | Lucid Information Technology, Ltd. | Graphics subsytem for integation in a PC-based computing system and providing multiple GPU-driven pipeline cores supporting multiple modes of parallelization dynamically controlled while running a graphics application |
| US20060232590A1 (en) * | 2004-01-28 | 2006-10-19 | Reuven Bakalash | Graphics processing and display system employing multiple graphics cores on a silicon chip of monolithic construction |
| US20080129744A1 (en) * | 2004-01-28 | 2008-06-05 | Lucid Information Technology, Ltd. | PC-based computing system employing a silicon chip implementing parallelized GPU-driven pipelines cores supporting multiple modes of parallelization dynamically controlled while running a graphics application |
| US9659340B2 (en) | 2004-01-28 | 2017-05-23 | Lucidlogix Technologies Ltd | Silicon chip of a monolithic construction for use in implementing multiple graphic cores in a graphics processing and display subsystem |
| US7289125B2 (en) | 2004-02-27 | 2007-10-30 | Nvidia Corporation | Graphics device clustering with PCI-express |
| US20050190190A1 (en) * | 2004-02-27 | 2005-09-01 | Nvidia Corporation | Graphics device clustering with PCI-express |
| US20050282538A1 (en) * | 2004-05-28 | 2005-12-22 | Marc Balon | Method and system for improving mobile radio communications |
| US7721118B1 (en) | 2004-09-27 | 2010-05-18 | Nvidia Corporation | Optimizing power and performance for multi-processor graphics processing |
| US8066515B2 (en) | 2004-11-17 | 2011-11-29 | Nvidia Corporation | Multiple graphics adapter connection systems |
| US7477256B1 (en) | 2004-11-17 | 2009-01-13 | Nvidia Corporation | Connecting graphics adapters for scalable performance |
| US7576745B1 (en) | 2004-11-17 | 2009-08-18 | Nvidia Corporation | Connecting graphics adapters |
| US20060274073A1 (en) * | 2004-11-17 | 2006-12-07 | Johnson Philip B | Multiple graphics adapter connection systems |
| US8134568B1 (en) | 2004-12-15 | 2012-03-13 | Nvidia Corporation | Frame buffer region redirection for multiple graphics adapters |
| US8212831B1 (en) | 2004-12-15 | 2012-07-03 | Nvidia Corporation | Broadcast aperture remapping for multiple graphics adapters |
| US7525549B1 (en) | 2004-12-16 | 2009-04-28 | Nvidia Corporation | Display balance/metering |
| US7545380B1 (en) | 2004-12-16 | 2009-06-09 | Nvidia Corporation | Sequencing of displayed images for alternate frame rendering in a multi-processor graphics system |
| US7796135B1 (en) | 2004-12-16 | 2010-09-14 | Nvidia Corporation | Coherence of displayed images for split-frame rendering in multi-processor graphics system |
| US7522167B1 (en) | 2004-12-16 | 2009-04-21 | Nvidia Corporation | Coherence of displayed images for split-frame rendering in multi-processor graphics system |
| US7372465B1 (en) | 2004-12-17 | 2008-05-13 | Nvidia Corporation | Scalable graphics processing for remote display |
| US20090096798A1 (en) * | 2005-01-25 | 2009-04-16 | Reuven Bakalash | Graphics Processing and Display System Employing Multiple Graphics Cores on a Silicon Chip of Monolithic Construction |
| US10614545B2 (en) | 2005-01-25 | 2020-04-07 | Google Llc | System on chip having processing and graphics units |
| US10867364B2 (en) | 2005-01-25 | 2020-12-15 | Google Llc | System on chip having processing and graphics units |
| US11341602B2 (en) | 2005-01-25 | 2022-05-24 | Google Llc | System on chip having processing and graphics units |
| US7383412B1 (en) | 2005-02-28 | 2008-06-03 | Nvidia Corporation | On-demand memory synchronization for peripheral systems with multiple parallel processors |
| US7602395B1 (en) | 2005-04-22 | 2009-10-13 | Nvidia Corporation | Programming multiple chips from a command buffer for stereo image generation |
| US8035645B2 (en) | 2005-04-25 | 2011-10-11 | Nvidia Corporation | Graphics processing system including at least three bus devices |
| US20100053177A1 (en) * | 2005-04-25 | 2010-03-04 | Nvidia Corporation | Graphics processing system including at least three bus devices |
| US7616207B1 (en) | 2005-04-25 | 2009-11-10 | Nvidia Corporation | Graphics processing system including at least three bus devices |
| US20060267990A1 (en) * | 2005-05-27 | 2006-11-30 | Rogers Philip J | Multiple video processor unit (VPU) memory mapping |
| US8654133B2 (en) | 2005-05-27 | 2014-02-18 | Ati Technologies Ulc | Dynamic load balancing in multiple video processing unit (VPU) systems |
| US20100085365A1 (en) * | 2005-05-27 | 2010-04-08 | Ati Technologies, Inc. | Dynamic Load Balancing in Multiple Video Processing Unit (VPU) Systems |
| US8054314B2 (en) | 2005-05-27 | 2011-11-08 | Ati Technologies, Inc. | Applying non-homogeneous properties to multiple video processing units (VPUs) |
| US7663635B2 (en) | 2005-05-27 | 2010-02-16 | Ati Technologies, Inc. | Multiple video processor unit (VPU) memory mapping |
| US7649537B2 (en) | 2005-05-27 | 2010-01-19 | Ati Technologies, Inc. | Dynamic load balancing in multiple video processing unit (VPU) systems |
| US20060267991A1 (en) * | 2005-05-27 | 2006-11-30 | Preetham Arcot J | Antialiasing system and method |
| US20060267993A1 (en) * | 2005-05-27 | 2006-11-30 | James Hunkins | Compositing in multiple video processing unit (VPU) systems |
| US8781260B2 (en) | 2005-05-27 | 2014-07-15 | Ati Technologies Ulc | Compositing in multiple video processing unit (VPU) systems |
| US20060267988A1 (en) * | 2005-05-27 | 2006-11-30 | Hussain Syed A | Synchronizing multiple cards in multiple video processing unit (VPU) systems |
| US20060271717A1 (en) * | 2005-05-27 | 2006-11-30 | Raja Koduri | Frame synchronization in multiple video processing unit (VPU) systems |
| WO2006126092A3 (en) * | 2005-05-27 | 2007-04-26 | Ati Technologies Inc | Dynamic load balancing in multiple video processing unit (vpu) systems |
| US8681160B2 (en) | 2005-05-27 | 2014-03-25 | Ati Technologies, Inc. | Synchronizing multiple cards in multiple video processing unit (VPU) systems |
| US7613346B2 (en) | 2005-05-27 | 2009-11-03 | Ati Technologies, Inc. | Compositing in multiple video processing unit (VPU) systems |
| WO2006126092A2 (en) * | 2005-05-27 | 2006-11-30 | Ati Technologies, Inc. | Dynamic load balancing in multiple video processing unit (vpu) systems |
| US8212838B2 (en) | 2005-05-27 | 2012-07-03 | Ati Technologies, Inc. | Antialiasing system and method |
| US20060267989A1 (en) * | 2005-05-27 | 2006-11-30 | Campbell Jonathan L | Dynamic load balancing in multiple video processing unit (VPU) systems |
| EP2390835A3 (en) * | 2005-05-27 | 2012-10-10 | ATI Technologies Inc. | Dynamic load balancing in multiple video processing (VPU) systems |
| US8400457B2 (en) | 2005-05-27 | 2013-03-19 | Ati Technologies, Inc. | Dynamic load balancing in multiple video processing unit (VPU) systems |
| US8427486B2 (en) | 2005-05-27 | 2013-04-23 | Ati Technologies Ulc | Applying non-homogeneous properties to multiple video processing units (VPUs) |
| US8452128B2 (en) | 2005-05-27 | 2013-05-28 | Ati Technologies Ulc | Compositing in multiple video processing unit (VPU) systems |
| US10026140B2 (en) | 2005-06-10 | 2018-07-17 | Nvidia Corporation | Using a scalable graphics system to enable a general-purpose multi-user computer system |
| US8106913B1 (en) | 2005-06-15 | 2012-01-31 | Nvidia Corporation | Graphical representation of load balancing and overlap |
| US7456833B1 (en) | 2005-06-15 | 2008-11-25 | Nvidia Corporation | Graphical representation of load balancing and overlap |
| US7629978B1 (en) | 2005-10-31 | 2009-12-08 | Nvidia Corporation | Multichip rendering with state control |
| US9324174B2 (en) | 2005-10-31 | 2016-04-26 | Nvidia Corporation | Multi-chip rendering with state control |
| US20080284677A1 (en) * | 2005-12-06 | 2008-11-20 | Dolby Laboratories Licensing Corporation | Modular Electronic Displays |
| US9324253B2 (en) * | 2005-12-06 | 2016-04-26 | Dolby Laboratories Licensing Corporation | Modular electronic displays |
| US8004532B2 (en) * | 2006-03-29 | 2011-08-23 | Casio Computer Co., Ltd | Server apparatus and server control method in computer system |
| US20070245021A1 (en) * | 2006-03-29 | 2007-10-18 | Casio Computer Co., Ltd. | Server apparatus and server control method in computer system |
| US20080158236A1 (en) * | 2006-12-31 | 2008-07-03 | Reuven Bakalash | Parallel graphics system employing multiple graphics pipelines wtih multiple graphics processing units (GPUs) and supporting the object division mode of parallel graphics rendering using pixel processing resources provided therewithin |
| US8497865B2 (en) | 2006-12-31 | 2013-07-30 | Lucid Information Technology, Ltd. | Parallel graphics system employing multiple graphics processing pipelines with multiple graphics processing units (GPUS) and supporting an object division mode of parallel graphics processing using programmable pixel or vertex processing resources provided with the GPUS |
| US20090141033A1 (en) * | 2007-11-30 | 2009-06-04 | Qualcomm Incorporated | System and method for using a secondary processor in a graphics system |
| US8922565B2 (en) * | 2007-11-30 | 2014-12-30 | Qualcomm Incorporated | System and method for using a secondary processor in a graphics system |
| US20090208098A1 (en) * | 2008-02-15 | 2009-08-20 | Microsoft Corporation | Tiling and merging framework for segmenting large images |
| US8086037B2 (en) * | 2008-02-15 | 2011-12-27 | Microsoft Corporation | Tiling and merging framework for segmenting large images |
| US20100153842A1 (en) * | 2008-12-12 | 2010-06-17 | Microsoft Corporation | Rendering source content for display |
| US8587610B2 (en) * | 2008-12-12 | 2013-11-19 | Microsoft Corporation | Rendering source content for display |
| US8214763B2 (en) * | 2009-03-24 | 2012-07-03 | International Business Machines Corporation | Auto-positioning a context menu on a GUI |
| US20100251175A1 (en) * | 2009-03-24 | 2010-09-30 | International Business Machines Corporation | Auto-positioning a context menu on a gui |
| US9479358B2 (en) | 2009-05-13 | 2016-10-25 | International Business Machines Corporation | Managing graphics load balancing strategies |
| US20100289803A1 (en) * | 2009-05-13 | 2010-11-18 | International Business Machines Corporation | Managing graphics load balancing strategies |
| WO2013068498A3 (en) * | 2011-11-08 | 2013-08-15 | Telefonaktiebolaget L M Ericsson (Publ) | Tile size in video coding |
| US20130222395A1 (en) * | 2012-02-29 | 2013-08-29 | Joaquin Cruz Blas, JR. | Dynamic Splitting of Content |
| US9269176B2 (en) | 2012-02-29 | 2016-02-23 | Adobe Systems Incorporated | Dynamic splitting of content |
| US9153058B2 (en) * | 2012-02-29 | 2015-10-06 | Adobe Systems Incorporated | Dynamic splitting of content |
| EP2674939A1 (en) * | 2012-06-11 | 2013-12-18 | QNX Software Systems Limited | Cell-based composited windowing system |
| US8994750B2 (en) | 2012-06-11 | 2015-03-31 | 2236008 Ontario Inc. | Cell-based composited windowing system |
| US9292950B2 (en) | 2012-06-11 | 2016-03-22 | 2236008 Ontario, Inc. | Cell-based composited windowing system |
| US9704212B2 (en) | 2013-02-07 | 2017-07-11 | Nvidia Corporation | System and method for image processing |
| GB2558885A (en) * | 2017-01-12 | 2018-07-25 | Imagination Tech Ltd | Graphics processing units and methods for subdividing a set of one or more tiles of a rendering space for rendering |
| US10387990B2 (en) | 2017-01-12 | 2019-08-20 | Imagination Technologies Limited | Graphics processing units and methods for subdividing a set of one or more tiles of a rendering space for rendering |
| GB2558885B (en) * | 2017-01-12 | 2021-04-07 | Imagination Tech Ltd | Graphics processing units and methods for subdividing a set of one or more tiles of a rendering space for rendering |
| US10937119B2 (en) * | 2018-03-15 | 2021-03-02 | Intel Corporation | Apparatus and method for virtualized scheduling of multiple duplicate graphics engines |
| US20230106345A1 (en) * | 2021-10-01 | 2023-04-06 | Sap Se | Printing electronic documents from large html screens |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US6191800B1 (en) | Dynamic balancing of graphics workloads using a tiling strategy | |
| US7800610B2 (en) | PC-based computing system employing a multi-GPU graphics pipeline architecture supporting multiple modes of GPU parallelization dymamically controlled while running a graphics application | |
| US7590947B1 (en) | Intelligent automatic window sizing | |
| US5289574A (en) | Multiple virtual screens on an "X windows" terminal | |
| KR101930565B1 (en) | Customization of an immersive environment | |
| US20090322760A1 (en) | Dynamic animation scheduling | |
| WO2004061598A2 (en) | System, method, and computer program product for near-real time load balancing across multiple rendering pipelines | |
| JP2003167659A (en) | Information processor and method for displaying information object | |
| JP2005018613A (en) | Information processor, method for controlling window display and program | |
| Ban et al. | Adaptively stepped SPH for fluid animation based on asynchronous time integration | |
| Dong et al. | Screen Partitioning Load Balancing for Parallel Rendering on a Multi-GPU Multi-Display Workstation. | |
| CN106547505B (en) | Method and system for real-time sliding display of scanned image | |
| KR20130106556A (en) | Apparatus and method for drawing vector image | |
| US7203359B1 (en) | Split screen technique for improving bandwidth utilization when transferring changing images | |
| JP2947984B2 (en) | Figure Drawing Method in Multiprocessor System | |
| Krogh et al. | Parallel sphere rendering | |
| Peek et al. | Using integrated GPUs to perform image warping for HMDs | |
| Carlbom et al. | Quantitative analysis of vector graphics system performance | |
| Ma et al. | SPIDER: An Effective, Efficient and Robust Load Scheduler for Real-time Split Frame Rendering | |
| Nam et al. | Multiuser-centered resource scheduling for collaborative display wall environments | |
| KR20220032736A (en) | Distributed rendering method based on multiple graphic processing units and apparatus therefor | |
| Kawanabe et al. | Showing Ultra-High-Resolution Images in VDA-Based Scalable Displays | |
| JP2887807B2 (en) | Document creation device | |
| Kontio | 51074C | |
| Eilemann | Recent Advances in the Equalizer Parallel Rendering Framework |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| AS | Assignment |
Owner name: INTERNATIONAL BUSINESS MACHINES CORPORATION, NEW Y Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNORS:ARENBURG, ROBERT T.;TAYLOR, ANDREW K.;REEL/FRAME:009385/0897 Effective date: 19980730 |
|
| FEPP | Fee payment procedure |
Free format text: PAYOR NUMBER ASSIGNED (ORIGINAL EVENT CODE: ASPN); ENTITY STATUS OF PATENT OWNER: LARGE ENTITY |
|
| STCF | Information on status: patent grant |
Free format text: PATENTED CASE |
|
| REMI | Maintenance fee reminder mailed | ||
| FPAY | Fee payment |
Year of fee payment: 4 |
|
| SULP | Surcharge for late payment | ||
| FPAY | Fee payment |
Year of fee payment: 8 |
|
| REMI | Maintenance fee reminder mailed | ||
| FPAY | Fee payment |
Year of fee payment: 12 |
|
| SULP | Surcharge for late payment |
Year of fee payment: 11 |