US20030190655A1 - Method and system for identifying commercially distributed organisms - Google Patents
Method and system for identifying commercially distributed organisms Download PDFInfo
- Publication number
- US20030190655A1 US20030190655A1 US10/363,464 US36346403A US2003190655A1 US 20030190655 A1 US20030190655 A1 US 20030190655A1 US 36346403 A US36346403 A US 36346403A US 2003190655 A1 US2003190655 A1 US 2003190655A1
- Authority
- US
- United States
- Prior art keywords
- sequences
- sequence
- organism
- individuals
- organisms
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Abandoned
Links
Images

Classifications
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B50/00—ICT programming tools or database systems specially adapted for bioinformatics
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
Definitions
- the present invention relates to a method and system for identifying commercially distributed organisms and/or offspring thereof. More particularly, the present invention relates to (i) genetically marked organisms; and (ii) a database server and a method for assigning sequences to be used to genetically mark organisms and for book keeping data pertaining to the genetically marked organisms and/or their owner, producer or source.
- IP intellectual property
- Transgenic organisms bacterial or fungal strains, crop varieties, or animal strains need by identifiable for recognition of source.
- Organisms which serve as biocontrol agents should be tagged for reasons of liability. It will be appreciated in this respect that the use of live organisms to control weed, bacterial, fungal, or insect pests is increasing. Many of the agents are closely related to known pathogens or pests and there have already been claims that a biocontrol organism changed its host range and attacked valuable species. In all probability, the related species was the culprit. There are few easy methods to ascertain causality with accuracy in some cases. There are also fears that biocontrol agents will mutate or introgress with other organisms, and there are needs to know whether the biocontrol agent changed host range (with consequences of liability) or whether an epidemic was due to wild strains. These issues with biocontrol agents will become more acute with transgenically-enhanced biocontrol agents.
- a method of marking individuals of commercially distributed organism or organisms and offspring thereof comprising the step of genetically marking a plurality of individuals of the organism or organisms with a plurality of unique DNA sequences, each of the unique DNA sequences includes a variable region, so as to produce artificial, inherited and detectable genetic variability among the plurality of individuals of the commercially distributed organism or organisms.
- a method of identifying individuals belonging to a commercially distributed organism comprising the steps of (a) genetically marking a plurality of individuals of the organism with a plurality of unique DNA sequences, each of the unique DNA sequences includes at least one variable region; (b) providing a database server including a lookup table associating each of the plurality of individuals with one of the plurality of unique DNA sequences; and (c) identifying whether an examined individual of the organism being one of the plurality of individuals or offspring thereof, and if so, which of the plurality of individuals or offspring thereof, by (i) determining a presence or absence, and if present, a nucleotide sequence of a unique DNA sequence of the plurality of unique DNA sequences by which the examined individual being genetically marked; and (ii) identifying the examined individual by associating the nucleotide sequence to one of the plurality of individuals via the lookup table of the database server.
- an organism having a genome, the organism being genetically marked by (a) at least one unique DNA sequence which is known in public; and (b) at least one unique DNA sequence that is unknown, at least not as a genetic mark, in public.
- a system for assigning DNA sequences to serve as genetic markers of commercially distributed organisms comprising a database server being designed and constructed for managing a sequences database and serving for (a) assigning at least one sequence of the sequences to an assignee upon request; and (b) book-keeping data pertaining to step (a).
- a method assigning DNA sequences to serve as genetic markers of commercially distributed organisms is effected by a data processor operatively communicating with a sequences data base and comprising the steps of (a) assigning at least one sequence of the sequences to an assignee upon request; and (b) book-keeping data pertaining to step (a).
- the request is effected via a communications network, such as the Internet
- the data pertaining to step (a) includes an identity of the assignee and/or an identity of an organism.
- the database server further serves for debiting the assignee and the method further comprising the step of debiting the assignee
- each of the sequences includes a variable region.
- each of the sequences includes a pair of universal regions, one on each side of the variable region.
- the database server further serves for (i) receiving a sequence input from a user and comparing the sequence input to sequences of the sequences database which have already been assigned; and, if no matching sequence is found (ii) identifying the user as an assignee of the sequence input.
- the method further comprising the steps of (c) receiving a sequence input from a user and comparing the sequence input to sequences of the sequences database which have already been assigned; and, if no matching sequence is found; (d) identifying the user as an assignee of the sequence input.
- the system further comprising a DNA synthesizer being in data communication with the database server, the DNA synthesizer serving for automatically synthesizing assigned sequences.
- the method thus, further comprising the step of communicating assigned sequences to a DNA synthesizer.
- the database server includes an application selected from the group consisting of (i) determining sequence identity; (ii) determining sequence homology and degree thereof; (iii) generating artificial sequences; (iv) combining sequences of different origins; (v) generating random sequences; (vi) evaluating a coding potential of a sequence; and (vii) scoring a coding potential of a sequence.
- kits for marking individuals of commercially distributed organism or organisms and offspring thereof comprising a plurality of containers containing a plurality of DNA molecules, each of the DNA molecules having a variable region being flanked by a pair of universal regions.
- the kit preferably further comprising, in a separate container, at least one amplification primer being hybridizable to the universal regions, so as to enable amplification of the variable region of each of the DNA molecules.
- Additional components of the kit may include reagents required for PCR amplification.
- each of the DNA molecules forms a part of a vector.
- nucleic acid microarray for determining an identity of an organism, the nucleic acid microarray comprising a solid support and a plurality of single stranded polynucleotides, each of a predetermined base sequence, being attached to the solid support at a predetermined location, the predetermined base sequence of the plurality of single stranded polynucleotides being designed for hybridizing with a plurality of variable sequences of genetic marks, such that a hybridization pattern with each of the variable sequences of the genetic marks is indicative of an identity of the genetic mark.
- the present invention successfully addresses the shortcomings of the presently known configurations by providing a database server and a method for assigning sequences to be used to genetically mark organisms and for book keeping data pertaining to the genetically marked organisms their owner, producer or source.
- Implementation of the method and system of the present invention involves performing or completing selected tasks or steps manually, automatically, or a combination thereof.
- several selected steps could be implemented by hardware or by software on any operating system of any firmware or a combination thereof.
- selected steps of the invention could be implemented as a chip or a circuit.
- selected steps of the invention could be implemented as a plurality of software instructions being executed by a computer using any suitable operating system.
- selected steps of the method and system of the invention could be described as being performed by a data processor, such as a computing platform for executing a plurality of instructions.
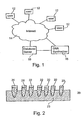
- FIG. 1 is a simplified depiction of a system according to the present invention
- FIG. 2 is a side view of a kit according to the present invention.
- FIG. 3 is a perspective view of a nucleic acid microarray according to the present invention.
- the present invention is of a method and system which can be used for identifying commercially distributed organisms and/or offspring thereof. Specifically, the present invention provides a database server and a method for assigning sequences to be used to genetically mark organisms and for book keeping data pertaining to the genetically marked organisms and/or their owner, producer or source
- the present invention provides a system and method for assigning DNA sequences to serve as genetic markers of commercially distributed organisms.
- the system includes a database server 10 which includes a data processor, is designed and constructed for managing a sequences database and which serves for (a) assigning at least one sequence of the sequences of the database to an assignee upon request; and (b) book-keeping data pertaining to step (a), data such as, but not limited to, particulars including the identity of the assignee and/or of an organism to be genetically marked.
- genetic mark is used herein distinctively from the common term “genetic marker”. While the latter term refers to naturally occurring genetic variations among individuals in a population, the term genetic mark as used herein specifically refers to artificial (man generated), inherited and detectable genetic variability.
- DNA segments In order to serve as genetic marks, DNA segments must have (i) a sequence which is appropriate (e.g., unique) to the genome of the organism in which it is present; and (ii) sequence variability, so as to enable the identification of different individuals of the organism.
- PCR polymerase chain reaction
- a DNA sequence which is used according to the present invention to genetically mark an organism preferably includes the variable region flanked by a pair of common or universal regions.
- a genetic mark according to the present invention can also include an identifier region, located, for example, alongside the variable region and which provides a more general type of identification.
- variable and in particular, the common regions of a genetic mark according to the present invention are selected unique to the genome of the organism of choice, or preferably to a genus, family, order or kingdom of organisms to which the organism of choice classifies.
- variable and universal regions of the mark are “non-sense” sequences, i.e., sequences that do not include an “open reading frame”.
- stop codons are preferably introduced into the sequences in all reading frames in predetermined intervals, e.g., every 2 to 20 codons.
- nucleotide repertoire used in a genetic mark of the present invention will be similar to the nucleotides repertoire characterizing the organism of choice.
- a similarly AT rich genetic mark will be employed, especially in the variable region of the genetic mark, whereas for an organism having a GC rich genome, a similarly GC rich genetic mark will be employed.
- the degree of sequence variability among genetic marks of the present invention should be set such that even if one or several mutations are introduced thereto along generations, still mark identity is maintained. This is especially true for organisms characterized by high reproduction rates, such as bacteria. Variability of at least 1-5% among marks would typically suffice for marks of about 1000 bp. Higher percentage should be used for shorter marks.
- Kit 20 for marking individuals of commercially distributed organism or organisms and offspring thereof.
- Kit 20 includes a plurality of containers 22 held in a suitable rack 23 .
- Containers 22 contain a plurality of DNA molecules, each of the DNA molecules is characterized by a variable region flanked by a pair of universal (common) regions.
- the kit preferably further includes, in at least one separate container 24 , at least one amplification primer which is hybridizable to the universal regions, so as to enable amplification of the variable region of each of the DNA molecules.
- kits may include reagents required for PCR amplification, such as, but not limited to, a concentrated (e.g., 10 ⁇ ) PCR buffer, a thermostable DNA polymerase, such as, but not limited to, thermophilus aquaticus (Taq) DNA polymerase and the four nucleoside tri phosphates (dNTPs).
- a thermostable DNA polymerase such as, but not limited to, thermophilus aquaticus (Taq) DNA polymerase and the four nucleoside tri phosphates (dNTPs).
- each of the DNA molecules forms a part of a vector, which can be a plasmid, a viral vector, a cosmid, a bacmid and the like.
- Viral packaging reagents may also be included in the kit.
- Each of the containers of the kit is identified for its content
- the sequence of each of the DNA molecules contained in the kit is identified directly or by a code referring to a list of sequences which is either provided with the
- a genetic mark may be cointegrated into a locus of the genome of an organism along with additional genetic material which is used to genetically modify the organism. This can be achieved either by using a single vector for introducing the mark and the additional genetic material or by employing cotransformation by two independent vectors, which, in most cases, results in a shared integration site.
- a request by a user 12 for a sequence is effected, according to a preferred embodiment of the present invention via a communications network 14 , such as, but not limited to, the Internet.
- a communications network 14 such as, but not limited to, the Internet.
- the term “user” or “user client” generally refers to a computer and includes, but is not limited to, personal computers (PC) having an operating system such as DOS, WindowsTM, OS/2TM or Linux; MacintoshTM computers; computers having JAVATM-OS as the operating system; and graphical workstations such as the computers of Sun MicrosystemsTM and Silicon GraphicsTM, and other computers having some version of the UNIX operating system such as AIXTM or SOLARISTM of Sun MicrosystemsTM; or any other known and available operating system; personal digital assistants (PDA), cellular telephones having Internet browsing capabilities and Web TVs.
- PC personal computers
- an operating system such as DOS, WindowsTM, OS/2TM or Linux
- MacintoshTM computers computers having JAVATM-OS as the operating system
- graphical workstations such as the computers of Sun MicrosystemsTM and Silicon GraphicsTM, and other computers having some version of the UNIX operating system such as AIXTM or SOLARISTM of Sun MicrosystemsTM; or any other known and
- WindowsTM includes, but is not limited to, Windows2000TM Windows95TM, Windows 3.xTM in which “x” is an integer such as “1”, Windows NTTM, Windows98TM, Windows2000TM, Windows CETM and any upgraded versions of these operating systems by Microsoft Corp. (USA).
- database server refers to any computing device or a plurality thereof acting in concert, capable of transferring, or serving, at least one electronic file to at least one other computing device.
- database server refers to any computing device capable of data processing.
- server and “user client” are indications of function rather than specific hardware configurations.
- the term “communications” refers to any means of information transfer, including, but not limited to, a telephone connection, a cellular telephone connection, an Internet connection, an Extranet connection, a satellite connection, cables connection, a local area network connection or a radio connection, or any other wired or unwired connection or any combination thereof.
- database server 10 also serves for debiting the assignee for services provided thereto.
- Such services include, as is mentioned hereinabove, the provision of unique sequence or sequences and the registry thereof as being associated with the assignee, etc.
- Debiting capabilities over the net are well known in the art and can be obtained by our sourcing from any one of a plurality of debiting service providers, which also provide for the security required for the execution of debiting.
- database server 10 preferably further serves for (i) receiving a sequence input from a user and comparing the sequence input to sequences of the sequences database which have already been assigned; and, if no matching sequence is found (ii) identifying the user as an assignee of the sequence input.
- Assignment of sequences according to the present invention may be of virtual sequences, i.e., their letter presentation, which can be used by the assignee to synthesize a molecule corresponding to the virtual sequence.
- assignment of sequences according to the present invention is accompanied by provision of an actual DNA molecule to be used by the assignee in the process of marking an organism.
- the system of the present invention further includes a DNA synthesizer 16 in data communication with database server 10 .
- DNA synthesizer 16 serves for automatically synthesizing assigned sequences.
- Synthesized sequences may then be shipped directly to the assignee or may be further processed using techniques such as restriction and ligation so as to be included in a vector which is adapted to introduce an assigned sequence into the genome of an organism to be genetically marked. Such further processing can also be executed using automated machinery, such that packaging, labeling and shipment procedures are all executed without direct man intervention. It will be appreciated that DNA synthesizer 16 need not be in proximity to database server 10 , as the data communication therebeween can be effected via any suitable communications network including the Internet, Intranet, Extranet, local area network, etc.
- DNA synthesizer refers to a complex machinery which stores suitable chemicals and is capable of solid phase synthesis of oligonucleotides. DNA synthesizers and the chemistry of oligonucleotide synthesis are well known in the art. To this end, see, for example, “Oligonucleotide Synthesis” Gait, M. J., ed. (1984).
- sequence management capabilities such as, but not limited to, (i) determining sequence identity; (ii) determining sequence homology and degree thereof; (iii) generating artificial sequences; (iv) combining sequences of different origins; (v) generating random sequences; (vi) evaluating a coding potential of a sequence; (vii) scoring a coding potential of a sequence and the like.
- sequence management capabilities such as, but not limited to, (i) determining sequence identity; (ii) determining sequence homology and degree thereof; (iii) generating artificial sequences; (iv) combining sequences of different origins; (v) generating random sequences; (vi) evaluating a coding potential of a sequence; (vii) scoring a coding potential of a sequence and the like.
- a method of marking individuals of commercially distributed organism or organisms and offspring thereof is effected by genetically marking a plurality of individuals of the organism or organisms with a plurality of unique DNA sequences, each of the unique DNA sequences includes a variable region, so as to produce artificial, inherited and detectable genetic variability among the plurality of individuals of the commercially distributed organism or organisms.
- a method of identifying individuals belonging to a commercially distributed organism is effected by (a) genetically marking a plurality of individuals of the organism with a plurality of unique DNA sequences, each of the unique DNA sequences includes at least one variable region; (b) providing a database server including a lookup table associating each of the plurality of individuals with one of the plurality of unique DNA sequences; and (c) identifying whether an examined individual of the organism being one of the plurality of individuals or offspring thereof, and if so, which of the plurality of individuals or offspring thereof, by (i) determining a presence or absence, and if present, a nucleotide sequence of a unique DNA sequence of the plurality of unique DNA sequences by which the examined individual being genetically marked; and (ii) identifying the examined individual by associating the nucleotide sequence to one of the plurality of individuals via the lookup table of the database server.
- database server 10 is constructed and designed so as to enable unlimited access to some of the data stored thereby and to restrict access to classified data stored thereby to authorized users only. Methods of achieving same are well known in the art.
- An intellectual property protected organism which is also subject to regulation will therefore be, according to a useful embodiment of the present invention, genetically marked by (a) at least one unique DNA sequence which is known in public; and (b) at least one unique DNA sequence that is unknown, at least not as a genetic mark, in public.
- sequence of a variable region of a genetic mark according to the present invention can be determined by conventional DNA sequencing of PCR amplified fragments. In a presently preferred embodiment, however, the sequence of a variable region of a genetic mark according to the present invention is determined by hybridization techniques, using a nucleic acid microarray, e.g., a DNA chip. DNA chips, their construction, methods of use and analysis of results are well known in the art.
- nucleic acid microarray 30 which is useful in determining an identity of an organism.
- Nucleic acid microarray 30 comprises a solid support 32 having a plurality of locations 33 and a plurality of single stranded polynucleotides 34 , each of a predetermined base-sequence, being attached to solid support 32 at predetermined locations of plurality of locations 33 .
- the predetermined base sequence of the plurality of single stranded polynucleotides 34 are designed for hybridizing with a plurality of variable sequences of genetic marks, such that a hybridization pattern with each of the variable sequences of the genetic marks is indicative of an identity of the genetic mark.
- Such hybridization pattern may include a single positive hybridization signal.
Abstract
A method of marking individuals of commercially distributed organism or organisms and offspring thereof is disclosed. The method is effected by genetically marking a plurality of individuals of the organism or organisms with a plurality of unique DNA sequences, each of the unique DNA sequences includes a variable region, so as to produce artificial, inherited and detectable genetic variability among the plurality of individuals of the commercially distributed organism or organisms.
Description
- The present invention relates to a method and system for identifying commercially distributed organisms and/or offspring thereof. More particularly, the present invention relates to (i) genetically marked organisms; and (ii) a database server and a method for assigning sequences to be used to genetically mark organisms and for book keeping data pertaining to the genetically marked organisms and/or their owner, producer or source.
- There are a variety of reasons to have organisms tagged with an “easy to read” code. Such reasons, include, but are not limited to, (i) recognition of source; (ii) ownership; (iii) regulation; and (iii) liability.
- For example, valuable bacterial or fungal strains, crop varieties, or animal strains need be identifiable for effectively effecting intellectual property (IP) rights or proof of ownership, as well as identity preservation.
- Transgenic organisms bacterial or fungal strains, crop varieties, or animal strains need by identifiable for recognition of source.
- In addition, regulatory authorities and various consumer groups are demanding labeling of certain transgenic commodities. They spend vast sums typically probing for common used promoters (35S, actin enhancer) or selectable marker genes (kanamycin or hygromycin resistance) and not for the trait genes, in an effort to save. Even when transgenics are discovered by such “kits”, there is no information as to source. Thus, regulatory authorities may wish to consider simple, common recognition sequences for detecting transgenics.
- Organisms which serve as biocontrol agents should be tagged for reasons of liability. It will be appreciated in this respect that the use of live organisms to control weed, bacterial, fungal, or insect pests is increasing. Many of the agents are closely related to known pathogens or pests and there have already been claims that a biocontrol organism changed its host range and attacked valuable species. In all probability, the related species was the culprit. There are few easy methods to ascertain causality with accuracy in some cases. There are also fears that biocontrol agents will mutate or introgress with other organisms, and there are needs to know whether the biocontrol agent changed host range (with consequences of liability) or whether an epidemic was due to wild strains. These issues with biocontrol agents will become more acute with transgenically-enhanced biocontrol agents.
- There is thus a great need for, and it would be highly advantageous to have, a database server and a method for assigning sequences to be used to genetically mark organisms and for book keeping data pertaining to the genetically marked organisms their owner, producer or source.
- According to one aspect of the present invention there is provided a method of marking individuals of commercially distributed organism or organisms and offspring thereof, the method comprising the step of genetically marking a plurality of individuals of the organism or organisms with a plurality of unique DNA sequences, each of the unique DNA sequences includes a variable region, so as to produce artificial, inherited and detectable genetic variability among the plurality of individuals of the commercially distributed organism or organisms.
- According to another aspect of the present invention there is provided a method of identifying individuals belonging to a commercially distributed organism, the method comprising the steps of (a) genetically marking a plurality of individuals of the organism with a plurality of unique DNA sequences, each of the unique DNA sequences includes at least one variable region; (b) providing a database server including a lookup table associating each of the plurality of individuals with one of the plurality of unique DNA sequences; and (c) identifying whether an examined individual of the organism being one of the plurality of individuals or offspring thereof, and if so, which of the plurality of individuals or offspring thereof, by (i) determining a presence or absence, and if present, a nucleotide sequence of a unique DNA sequence of the plurality of unique DNA sequences by which the examined individual being genetically marked; and (ii) identifying the examined individual by associating the nucleotide sequence to one of the plurality of individuals via the lookup table of the database server.
- According to yet another aspect of the present invention there is provided an organism having a genome, the organism being genetically marked by (a) at least one unique DNA sequence which is known in public; and (b) at least one unique DNA sequence that is unknown, at least not as a genetic mark, in public.
- According to still another aspect of the present invention there is provided a system for assigning DNA sequences to serve as genetic markers of commercially distributed organisms, the system comprising a database server being designed and constructed for managing a sequences database and serving for (a) assigning at least one sequence of the sequences to an assignee upon request; and (b) book-keeping data pertaining to step (a).
- According to an additional aspect of the present invention there is provided a method assigning DNA sequences to serve as genetic markers of commercially distributed organisms, the method is effected by a data processor operatively communicating with a sequences data base and comprising the steps of (a) assigning at least one sequence of the sequences to an assignee upon request; and (b) book-keeping data pertaining to step (a).
- According to further features in preferred embodiments of the invention described below, the request is effected via a communications network, such as the Internet
- According to still further features in the described preferred embodiments the data pertaining to step (a) includes an identity of the assignee and/or an identity of an organism.
- According to still further features in the described preferred embodiments the database server further serves for debiting the assignee and the method further comprising the step of debiting the assignee
- According to still further features in the described preferred embodiments each of the sequences includes a variable region. Preferably, each of the sequences includes a pair of universal regions, one on each side of the variable region.
- According to still further features in the described preferred embodiments the database server further serves for (i) receiving a sequence input from a user and comparing the sequence input to sequences of the sequences database which have already been assigned; and, if no matching sequence is found (ii) identifying the user as an assignee of the sequence input. Thus, the method further comprising the steps of (c) receiving a sequence input from a user and comparing the sequence input to sequences of the sequences database which have already been assigned; and, if no matching sequence is found; (d) identifying the user as an assignee of the sequence input.
- According to still further features in the described preferred embodiments the system further comprising a DNA synthesizer being in data communication with the database server, the DNA synthesizer serving for automatically synthesizing assigned sequences. The method, thus, further comprising the step of communicating assigned sequences to a DNA synthesizer.
- According to still further features in the described preferred embodiments the database server includes an application selected from the group consisting of (i) determining sequence identity; (ii) determining sequence homology and degree thereof; (iii) generating artificial sequences; (iv) combining sequences of different origins; (v) generating random sequences; (vi) evaluating a coding potential of a sequence; and (vii) scoring a coding potential of a sequence.
- According to another aspect of the present invention there is provided a kit for marking individuals of commercially distributed organism or organisms and offspring thereof, the kit comprising a plurality of containers containing a plurality of DNA molecules, each of the DNA molecules having a variable region being flanked by a pair of universal regions. The kit preferably further comprising, in a separate container, at least one amplification primer being hybridizable to the universal regions, so as to enable amplification of the variable region of each of the DNA molecules. Additional components of the kit may include reagents required for PCR amplification. Preferably, each of the DNA molecules forms a part of a vector.
- According to still another aspect of the present invention there is provided a nucleic acid microarray for determining an identity of an organism, the nucleic acid microarray comprising a solid support and a plurality of single stranded polynucleotides, each of a predetermined base sequence, being attached to the solid support at a predetermined location, the predetermined base sequence of the plurality of single stranded polynucleotides being designed for hybridizing with a plurality of variable sequences of genetic marks, such that a hybridization pattern with each of the variable sequences of the genetic marks is indicative of an identity of the genetic mark.
- The present invention successfully addresses the shortcomings of the presently known configurations by providing a database server and a method for assigning sequences to be used to genetically mark organisms and for book keeping data pertaining to the genetically marked organisms their owner, producer or source.
- Implementation of the method and system of the present invention involves performing or completing selected tasks or steps manually, automatically, or a combination thereof. Moreover, according to actual instrumentation and equipment of preferred embodiments of the method and system of the present invention, several selected steps could be implemented by hardware or by software on any operating system of any firmware or a combination thereof. For example, as hardware, selected steps of the invention could be implemented as a chip or a circuit. As software, selected steps of the invention could be implemented as a plurality of software instructions being executed by a computer using any suitable operating system. In any case, selected steps of the method and system of the invention could be described as being performed by a data processor, such as a computing platform for executing a plurality of instructions.
- The invention is herein described, by way of example only, with reference to the accompanying drawings. With specific reference now to the drawings in detail, it is stressed that the particulars shown are by way of example and for purposes of illustrative discussion of the preferred embodiments of the present invention only, and are presented in the cause of providing what is believed to be the most useful and readily understood description of the principles and conceptual aspects of the invention. In this regard, no attempt is made to show structural details of the invention in more detail than is necessary for a fundamental understanding of the invention, the description taken with the drawings making apparent to those skilled in the art how the several forms of the invention may be embodied in practice.
- In the drawings:
- FIG. 1 is a simplified depiction of a system according to the present invention;
- FIG. 2 is a side view of a kit according to the present invention; and
- FIG. 3 is a perspective view of a nucleic acid microarray according to the present invention.
- The present invention is of a method and system which can be used for identifying commercially distributed organisms and/or offspring thereof. Specifically, the present invention provides a database server and a method for assigning sequences to be used to genetically mark organisms and for book keeping data pertaining to the genetically marked organisms and/or their owner, producer or source
- The principles and operation of a system and method according to the present invention may be better understood with reference to the drawings and accompanying descriptions.
- Before explaining at least one embodiment of the invention in detail, it is to be understood that the invention is not limited in its application to the details of construction and the arrangement of the components set forth in the following description or illustrated in the drawings. The invention is capable of other embodiments or of being practiced or carried out in various ways. Also, it is to be understood that the phraseology and terminology employed herein is for the purpose of description and should not be regarded as limiting.
- In one aspect the present invention provides a system and method for assigning DNA sequences to serve as genetic markers of commercially distributed organisms. As shown in FIG. 1, the system according to this aspect of the invention includes a
database server 10 which includes a data processor, is designed and constructed for managing a sequences database and which serves for (a) assigning at least one sequence of the sequences of the database to an assignee upon request; and (b) book-keeping data pertaining to step (a), data such as, but not limited to, particulars including the identity of the assignee and/or of an organism to be genetically marked. - Methods of inserting specific DNA sequences at one or more locations, at random or in a targeted fashion to genomes of prokaryotes or eukaryotes, unicellular or multicellular organisms, including, but not limited to, plants, such as crop plants, bacteria, fungi, insects and higher animals, including, domesticated animals and live stock, are well known in the art. Such methods which are known as, or employ steps of, transformation, transfection, trangenization, bombardment and the like, are extensively described in the scientific literature and in laboratory manuals such as, for example, “Molecular Cloning: A laboratory Manual” Sambrook et al., (1989); “Current Protocols in Molecular Biology” Volumes I-III Ausubel, R. M., ed. (1994); Ausubel et al., “Current Protocols in Molecular Biology”, John Wiley and Sons, Baltimore, Md. (1989); Perbal, “A Practical Guide to Molecular Cloning”, John Wiley & Sons, New York (1988); Watson et al., “Recombinant DNA”, Scientific American Books, New York; Birren et al. (eds) “Genome Analysis: A Laboratory Manual Series”, Vols. 1-4, Cold Spring Harbor Laboratory Press, New York (1998); “Cell Biology: A Laboratory Handbook”, Volumes I-III Cellis, J. E., ed. (1994); “Culture of Animal Cells—A Manual of Basic Technique” by Freshney, Wiley-Liss, N. Y. (1994), Third Edition; “Oligonucleotide Synthesis” Gait, M. J., ed. (1984); “Nucleic Acid Hybridization” Hames, B. D., and Higgins S. J., eds. (1985); “Transcription and Translation” Hames, B. D., and Higgins S. J., eds. (1984); “Animal Cell Culture” Freshney, R. I., ed. (1986); “A Practical Guide to Molecular Cloning” Perbal, B., (1984); “PCR Protocols: A Guide To Methods And Applications”, Academic Press, San Diego, Calif. (1990); all of which are incorporated by reference as if fully set forth herein.
- Presently preferred characteristics of DNA sequences which are used according to the present invention to genetically mark and thereafter identify the organisms or their offspring are described in the following paragraphs.
- The term “genetic mark” is used herein distinctively from the common term “genetic marker”. While the latter term refers to naturally occurring genetic variations among individuals in a population, the term genetic mark as used herein specifically refers to artificial (man generated), inherited and detectable genetic variability.
- In order to serve as genetic marks, DNA segments must have (i) a sequence which is appropriate (e.g., unique) to the genome of the organism in which it is present; and (ii) sequence variability, so as to enable the identification of different individuals of the organism.
- With the advent of the polymerase chain reaction (PCR) technology and other amplification methods, it is nowadays relatively simple to determine the presence, absence and sequence of selected regions in genomes of organisms, provided that a sequence to be determined is either known or that regions flanking it from either side are known. Since sequence variability is required according to the present invention to produce specific identity, from a practical point of view, a DNA sequence which is used according to the present invention to genetically mark an organism preferably includes the variable region flanked by a pair of common or universal regions. A genetic mark according to the present invention can also include an identifier region, located, for example, alongside the variable region and which provides a more general type of identification. For example, different identifier regions can be associated with genetic marks used by different corporations and serve for fast identification using simple hybridization techniques to genomic DNA (e.g., dot blot hybridization). Thus, amplification primers which can hybridize with the universal regions of the mark can be used with PCR to amplify the variable region and its sequence can thereafter be determined. To prevent coamplification of sequences of the genome of the organism, the variable and in particular, the common regions of a genetic mark according to the present invention are selected unique to the genome of the organism of choice, or preferably to a genus, family, order or kingdom of organisms to which the organism of choice classifies. In addition, in order to prevent the possibility that the introduction of a genetic mark according to the present invention will result in expression of whatever genetic information encoded thereby, it is advantageous to select the variable and universal regions of the mark to be “non-sense” sequences, i.e., sequences that do not include an “open reading frame”. To ensure that this is indeed the case, stop codons are preferably introduced into the sequences in all reading frames in predetermined intervals, e.g., every 2 to 20 codons.
- In addition, it may be desired that the nucleotide repertoire used in a genetic mark of the present invention will be similar to the nucleotides repertoire characterizing the organism of choice. Thus, for example, for an organism having an AT rich genome, a similarly AT rich genetic mark will be employed, especially in the variable region of the genetic mark, whereas for an organism having a GC rich genome, a similarly GC rich genetic mark will be employed.
- Furthermore, the degree of sequence variability among genetic marks of the present invention should be set such that even if one or several mutations are introduced thereto along generations, still mark identity is maintained. This is especially true for organisms characterized by high reproduction rates, such as bacteria. Variability of at least 1-5% among marks would typically suffice for marks of about 1000 bp. Higher percentage should be used for shorter marks.
- Genetic marks of the present invention may be provided to users in contained in dedicated kits. As shown in FIG. 2, according to another aspect of the present invention there is provided a
kit 20 for marking individuals of commercially distributed organism or organisms and offspring thereof.Kit 20 includes a plurality ofcontainers 22 held in asuitable rack 23.Containers 22 contain a plurality of DNA molecules, each of the DNA molecules is characterized by a variable region flanked by a pair of universal (common) regions. The kit preferably further includes, in at least oneseparate container 24, at least one amplification primer which is hybridizable to the universal regions, so as to enable amplification of the variable region of each of the DNA molecules. Additional components of the kit may include reagents required for PCR amplification, such as, but not limited to, a concentrated (e.g., 10×) PCR buffer, a thermostable DNA polymerase, such as, but not limited to, thermophilus aquaticus (Taq) DNA polymerase and the four nucleoside tri phosphates (dNTPs). Preferably, each of the DNA molecules forms a part of a vector, which can be a plasmid, a viral vector, a cosmid, a bacmid and the like. Viral packaging reagents may also be included in the kit. Each of the containers of the kit is identified for its content In particular, the sequence of each of the DNA molecules contained in the kit is identified directly or by a code referring to a list of sequences which is either provided with the kit or otherwise made available to the user. - A genetic mark may be cointegrated into a locus of the genome of an organism along with additional genetic material which is used to genetically modify the organism. This can be achieved either by using a single vector for introducing the mark and the additional genetic material or by employing cotransformation by two independent vectors, which, in most cases, results in a shared integration site.
- As is further shown in FIG. 1, a request by a
user 12 for a sequence is effected, according to a preferred embodiment of the present invention via acommunications network 14, such as, but not limited to, the Internet. - For purposes of this specification and the accompanying claims, the term “user” or “user client” generally refers to a computer and includes, but is not limited to, personal computers (PC) having an operating system such as DOS, Windows™, OS/2™ or Linux; Macintosh™ computers; computers having JAVA™-OS as the operating system; and graphical workstations such as the computers of Sun Microsystems™ and Silicon Graphics™, and other computers having some version of the UNIX operating system such as AIX™ or SOLARIS™ of Sun Microsystems™; or any other known and available operating system; personal digital assistants (PDA), cellular telephones having Internet browsing capabilities and Web TVs.
- For purposes of this specification and the accompanying claims, the term “Windows™” includes, but is not limited to, Windows2000™ Windows95™, Windows 3.x™ in which “x” is an integer such as “1”, Windows NT™, Windows98™, Windows2000™, Windows CE™ and any upgraded versions of these operating systems by Microsoft Corp. (USA).
- For purposes of this specification and the accompanying claims, the term “database server” refers to any computing device or a plurality thereof acting in concert, capable of transferring, or serving, at least one electronic file to at least one other computing device.
- For purposes of this specification and the accompanying claims, the term “database server” refers to any computing device capable of data processing.
- For purposes of this specification and the accompanying claims, “server” and “user client” are indications of function rather than specific hardware configurations.
- For purposes of this specification and the accompanying claims, the term “communications” refers to any means of information transfer, including, but not limited to, a telephone connection, a cellular telephone connection, an Internet connection, an Extranet connection, a satellite connection, cables connection, a local area network connection or a radio connection, or any other wired or unwired connection or any combination thereof.
- In a preferred embodiment of the present invention,
database server 10 also serves for debiting the assignee for services provided thereto. Such services, include, as is mentioned hereinabove, the provision of unique sequence or sequences and the registry thereof as being associated with the assignee, etc. Debiting capabilities over the net are well known in the art and can be obtained by our sourcing from any one of a plurality of debiting service providers, which also provide for the security required for the execution of debiting. - In some cases, a user may desire to design his own unique sequence and deposit that sequence in a depository, so as to prevent a case where a another party will use the same sequence as a genetic mark. To this end,
database server 10 preferably further serves for (i) receiving a sequence input from a user and comparing the sequence input to sequences of the sequences database which have already been assigned; and, if no matching sequence is found (ii) identifying the user as an assignee of the sequence input. - Assignment of sequences according to the present invention may be of virtual sequences, i.e., their letter presentation, which can be used by the assignee to synthesize a molecule corresponding to the virtual sequence. Preferably, assignment of sequences according to the present invention is accompanied by provision of an actual DNA molecule to be used by the assignee in the process of marking an organism. To this end, the system of the present invention further includes a
DNA synthesizer 16 in data communication withdatabase server 10.DNA synthesizer 16 serves for automatically synthesizing assigned sequences. - Synthesized sequences may then be shipped directly to the assignee or may be further processed using techniques such as restriction and ligation so as to be included in a vector which is adapted to introduce an assigned sequence into the genome of an organism to be genetically marked. Such further processing can also be executed using automated machinery, such that packaging, labeling and shipment procedures are all executed without direct man intervention. It will be appreciated that
DNA synthesizer 16 need not be in proximity todatabase server 10, as the data communication therebeween can be effected via any suitable communications network including the Internet, Intranet, Extranet, local area network, etc. - As used herein the term “DNA synthesizer” refers to a complex machinery which stores suitable chemicals and is capable of solid phase synthesis of oligonucleotides. DNA synthesizers and the chemistry of oligonucleotide synthesis are well known in the art. To this end, see, for example, “Oligonucleotide Synthesis” Gait, M. J., ed. (1984).
- Efficiently managing sequence depository data which will comply with the requirements imposed by the present invention, that is to ensure that a given sequence is assigned only once and further that the identity of an assignee or organism is associated with the appropriate sequences, calls for certain sequence management capabilities, such as, but not limited to, (i) determining sequence identity; (ii) determining sequence homology and degree thereof; (iii) generating artificial sequences; (iv) combining sequences of different origins; (v) generating random sequences; (vi) evaluating a coding potential of a sequence; (vii) scoring a coding potential of a sequence and the like. Such computational functions are well known in the art and can be readily integrated into a comprehensive system acting in concert to serve registry functions as herein described.
- Thus, according to the present invention there is provided a method of marking individuals of commercially distributed organism or organisms and offspring thereof. The method according to the present invention is effected by genetically marking a plurality of individuals of the organism or organisms with a plurality of unique DNA sequences, each of the unique DNA sequences includes a variable region, so as to produce artificial, inherited and detectable genetic variability among the plurality of individuals of the commercially distributed organism or organisms.
- Also according to the present invention there is provided a method of identifying individuals belonging to a commercially distributed organism. The method is effected by (a) genetically marking a plurality of individuals of the organism with a plurality of unique DNA sequences, each of the unique DNA sequences includes at least one variable region; (b) providing a database server including a lookup table associating each of the plurality of individuals with one of the plurality of unique DNA sequences; and (c) identifying whether an examined individual of the organism being one of the plurality of individuals or offspring thereof, and if so, which of the plurality of individuals or offspring thereof, by (i) determining a presence or absence, and if present, a nucleotide sequence of a unique DNA sequence of the plurality of unique DNA sequences by which the examined individual being genetically marked; and (ii) identifying the examined individual by associating the nucleotide sequence to one of the plurality of individuals via the lookup table of the database server.
- For some, e.g., regulatory, purposes it may be desired to mark commercially distributed organisms with publicly known marks, so as to enable regulatory authorities to readily identify the mark, and, by using the system and method of the invention, to identify the manufacturer, distributor, owner or user of the marked organism. For other purposes secrecy may be advantageous. The latter is true, for example, for preventing an attempt to genetically modify the genetic mark of a supreme strain protected by intellectual property laws. Thus, according to a preferred embodiment of the present invention,
database server 10 is constructed and designed so as to enable unlimited access to some of the data stored thereby and to restrict access to classified data stored thereby to authorized users only. Methods of achieving same are well known in the art. - An intellectual property protected organism which is also subject to regulation will therefore be, according to a useful embodiment of the present invention, genetically marked by (a) at least one unique DNA sequence which is known in public; and (b) at least one unique DNA sequence that is unknown, at least not as a genetic mark, in public.
- The sequence of a variable region of a genetic mark according to the present invention can be determined by conventional DNA sequencing of PCR amplified fragments. In a presently preferred embodiment, however, the sequence of a variable region of a genetic mark according to the present invention is determined by hybridization techniques, using a nucleic acid microarray, e.g., a DNA chip. DNA chips, their construction, methods of use and analysis of results are well known in the art.
- Hence, according to another aspect of the present invention, as shown in FIG. 3, there is provided a
nucleic acid microarray 30 which is useful in determining an identity of an organism.Nucleic acid microarray 30 comprises asolid support 32 having a plurality oflocations 33 and a plurality of single strandedpolynucleotides 34, each of a predetermined base-sequence, being attached tosolid support 32 at predetermined locations of plurality oflocations 33. The predetermined base sequence of the plurality of single strandedpolynucleotides 34 are designed for hybridizing with a plurality of variable sequences of genetic marks, such that a hybridization pattern with each of the variable sequences of the genetic marks is indicative of an identity of the genetic mark. Such hybridization pattern may include a single positive hybridization signal. - Although the invention has been described in conjunction with specific embodiments thereof, it is evident that many alternatives, modifications and variations will be apparent to those skilled in the art. Accordingly, it is intended to embrace all such alternatives, modifications and variations that fall within the spirit and broad scope of the appended claims. All publications, patents and patent applications mentioned in this specification are herein incorporated in their entirety by reference into the specification, to the same extent as if each individual publication, patent or patent application was specifically and individually indicated to be incorporated herein by reference. In addition, citation or identification of any reference in this application shall not be construed as an admission that such reference is available as prior art to the present invention.
Claims (34)
1. A method of marking individuals of commercially distributed organism or organisms and offspring thereof, the method comprising the step of genetically marking a plurality of individuals of the organism or organisms with a plurality of unique DNA sequences, each of said unique DNA sequences includes a variable region selected so as to produce artificial, inherited and detectable genetic variability among said plurality of individuals of the commercially distributed organism or organisms.
2. The method of claim 1 , wherein each of said unique DNA sequences further includes a pair of universal regions one on each side of said variable region.
3. A method of identifying individuals belonging to a commercially distributed organism, the method comprising the steps of:
(a) genetically marking a plurality of individuals of the organism with a plurality of unique DNA sequences, each of said unique DNA sequences includes at least one variable region;
(b) providing a database server including a lookup table associating each of said plurality of individuals with one of said plurality of unique DNA sequences; and
(c) identifying whether an examined individual of said organism being one of said plurality of individuals or offspring thereof, and if so, which of said plurality of individuals or offspring thereof, by:
(i) determining a presence or absence, and if present, a nucleotide sequence of a unique DNA sequence of said plurality of unique DNA sequences by which said examined individual being genetically marked; and
(ii) identifying said examined individual by associating said nucleotide sequence to one of said plurality of individuals via said lookup table of said database server.
4. The method of claim 3 , wherein each of said unique DNA sequences further includes a pair of universal regions, one on each side of said variable region.
5. The method of claim 3 , wherein said nucleotide sequence of said unique DNA sequence of said plurality of unique DNA sequences by which said examined individual being genetically marked, is effected by a nucleic acid microarray hybridization technique.
6. An organism having a genome, said organism being genetically marked by:
(a) at least one unique DNA sequence which is known in public; and
(b) at least one unique DNA sequence that is unknown, at least not as a genetic mark, in public.
7. A system for Assigning DNA sequences to serve as genetic markers of commercially distributed organisms, the system comprising a database server being designed and constructed for managing a sequences database and serving for:
(a) assigning at least one sequence of said sequences to an assignee upon request; and
(b) book-keeping data pertaining to step (a).
8. The system of claim 7 , wherein said request is effected via a communications network.
9. The system of claim 8 , wherein said communications network is the Internet.
10. The system of claim 7 , wherein said data pertaining to step (a) includes an identity of said assignee.
11. The system of claim 7 , wherein said data pertaining to step (a) includes an identity of an organism.
12. The system of claim 7 , wherein said database server further serves for debiting said assignee.
13. The system of claim 7 , wherein each of said sequences includes a variable region.
14. The system of claim 13 , wherein each of said sequences includes a pair of universal regions, one on each side of said variable region.
15. The system of claim 7 , wherein said database server further serves for receiving a sequence input from a user.
16. The system of claim 7 , wherein said database server further serves for receiving a sequence input from a user and comparing said sequence input to said sequences database.
17. The system of claim 7 , wherein said database server further serves for:
(i) receiving a sequence input from a user and comparing said sequence input to sequences of said sequences database which have already been assigned; and, if no matching sequence is found
(ii) identifying said user as an assignee of said sequence input.
18. The system of claim 7 , further comprising a DNA synthesizer being in data communication with said database server, said DNA synthesizer serving for automatically synthesizing assigned sequences.
19. The system of claim 7 , wherein said database server includes an application selected from the group consisting of:
(i) determining sequence identity;
(ii) determining sequence homology and degree thereof;
(iii) generating artificial sequences;
(iv) combining sequences of different origins;
(v) generating random sequences;
(vi) evaluating a coding potential of a sequence; and
(vii) scoring a coding potential of a sequence.
20. A method assigning DNA sequences to serve as genetic markers of commercially distributed organisms, the method is effected by a data processor operatively communicating with a sequences data base and comprising the steps of:
(a) assigning at least one sequence of said sequences to an assignee upon request; and
(b) book-keeping data pertaining to step (a).
21. The method of claim 20 , wherein said request is effected via a communications network.
22. The method of claim 21 , wherein said communications network is the Internet.
23. The method of claim 20 , wherein said data pertaining to step (a) includes an identity of said assignee.
24. The method of claim 20 , wherein said data pertaining to step (a) includes an identity of an organism.
25. The method of claim 20 , further comprising the step of debiting said assignee.
26. The method of claim 20 , wherein each of said sequences includes a variable region.
27. The method of claim 26 , wherein each of said sequences includes a pair of universal regions, one on each side of said variable region.
28. The method of claim 20 , further comprising the steps of:
(c) receiving a sequence input from a user and comparing said sequence input to sequences of said sequences database which have already been assigned; and, if no matching sequence is found
(d) identifying said user as an assignee of said sequence input.
29. The method of claim 20 , further comprising the step of communicating assigned sequences to a DNA synthesizer.
30. The method of claim 20 , wherein said data processor operates an application selected from the group consisting of:
(i) determining sequence identity;
(ii) determining sequence homology and degree thereof;
(iii) generating artificial sequences;
(iv) combining sequences of different origins;
(v) generating random sequences;
(vi) evaluating a coding potential of a sequence; and
(vii) scoring a coding potential of a sequence.
31. A kit for marking individuals of commercially distributed organism or organisms and offspring thereof, the kit comprising a plurality of containers each containing a DNA molecule having a unique variable region being flanked by a pair of universal regions, said unique variable region being selected so as to produce artificial, inherited and detectable genetic variability among the individuals of commercially distributed organism or organisms and offspring thereof.
32. The kit of claim 31 , further comprising at least one amplification primer being hybridizable to said universal regions, so as to enable amplification of said unique variable region of said DNA molecule.
33. The kit of claim 31 , wherein said DNA molecule forms a part of a vector.
34. A nucleic acid microarray for determining an identity of an organism, the nucleic acid microarray comprising a solid support and a plurality of single stranded polynucleotides, each of a predetermined base sequence, being attached to said solid support at a predetermined location, said predetermined base sequence of said plurality of single stranded polynucleotides being designed for hybridizing with a plurality of variable sequences of genetic marks, such that a hybridization pattern with each of said variable sequences of said genetic marks is indicative of an identity of the genetic mark.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US09/655,960 US6629038B1 (en) | 2000-09-05 | 2000-09-05 | Method and system for identifying commercially distributed organisms |
| PCT/IL2001/000783 WO2002021418A2 (en) | 2000-09-05 | 2001-08-21 | Method and system for identifying commercially distributed organisms |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| US20030190655A1 true US20030190655A1 (en) | 2003-10-09 |
Family
ID=24631075
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US09/655,960 Expired - Fee Related US6629038B1 (en) | 2000-09-05 | 2000-09-05 | Method and system for identifying commercially distributed organisms |
| US10/363,464 Abandoned US20030190655A1 (en) | 2000-09-05 | 2001-08-21 | Method and system for identifying commercially distributed organisms |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US09/655,960 Expired - Fee Related US6629038B1 (en) | 2000-09-05 | 2000-09-05 | Method and system for identifying commercially distributed organisms |
Country Status (6)
| Country | Link |
|---|---|
| US (2) | US6629038B1 (en) |
| EP (1) | EP1374134A2 (en) |
| AU (1) | AU2001282469A1 (en) |
| CA (1) | CA2421203A1 (en) |
| IL (1) | IL154742A0 (en) |
| WO (1) | WO2002021418A2 (en) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE10321480B4 (en) * | 2003-05-13 | 2005-07-21 | Universität Potsdam | Method for identifying cell lines |
| US7425171B2 (en) * | 2004-02-13 | 2008-09-16 | Kathy Maupin | Post surgical binder |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5451505A (en) * | 1989-05-22 | 1995-09-19 | Hoffmann-La Roche Inc. | Methods for tagging and tracing materials with nucleic acids |
| US5643728A (en) * | 1992-08-26 | 1997-07-01 | Slater; James Howard | Method of marking a liquid |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP0834576B1 (en) * | 1990-12-06 | 2002-01-16 | Affymetrix, Inc. (a Delaware Corporation) | Detection of nucleic acid sequences |
| AU701932B2 (en) * | 1994-12-08 | 1999-02-11 | Pabio | Chemical labelling of objects |
| US7321828B2 (en) * | 1998-04-13 | 2008-01-22 | Isis Pharmaceuticals, Inc. | System of components for preparing oligonucleotides |
-
2000
- 2000-09-05 US US09/655,960 patent/US6629038B1/en not_active Expired - Fee Related
-
2001
- 2001-08-21 AU AU2001282469A patent/AU2001282469A1/en not_active Abandoned
- 2001-08-21 WO PCT/IL2001/000783 patent/WO2002021418A2/en not_active Application Discontinuation
- 2001-08-21 US US10/363,464 patent/US20030190655A1/en not_active Abandoned
- 2001-08-21 EP EP01961091A patent/EP1374134A2/en not_active Withdrawn
- 2001-08-21 CA CA002421203A patent/CA2421203A1/en not_active Abandoned
- 2001-08-21 IL IL15474201A patent/IL154742A0/en unknown
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5451505A (en) * | 1989-05-22 | 1995-09-19 | Hoffmann-La Roche Inc. | Methods for tagging and tracing materials with nucleic acids |
| US5643728A (en) * | 1992-08-26 | 1997-07-01 | Slater; James Howard | Method of marking a liquid |
Also Published As
| Publication number | Publication date |
|---|---|
| US6629038B1 (en) | 2003-09-30 |
| AU2001282469A1 (en) | 2002-03-22 |
| IL154742A0 (en) | 2003-10-31 |
| CA2421203A1 (en) | 2002-03-14 |
| WO2002021418A3 (en) | 2003-10-09 |
| EP1374134A2 (en) | 2004-01-02 |
| WO2002021418A2 (en) | 2002-03-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Casa et al. | The MITE family Heartbreaker (Hbr): molecular markers in maize | |
| Stekel | Microarray bioinformatics | |
| Davey et al. | RADSeq: next-generation population genetics | |
| Song et al. | A new integrated genetic linkage map of the soybean | |
| Davoli et al. | Isolation of porcine expressed sequence tags for the construction of a first genomic transcript map of the skeletal muscle in pig | |
| Corradi et al. | Gene copy number polymorphisms in an arbuscular mycorrhizal fungal population | |
| Biedler et al. | Non-LTR retrotransposons in the African malaria mosquito, Anopheles gambiae: unprecedented diversity and evidence of recent activity | |
| Nesvold et al. | Design of a DNA chip for detection of unknown genetically modified organisms (GMOs) | |
| Drechsler et al. | What remains from a 454 run: estimation of success rates of microsatellite loci development in selected newt species (C alotriton asper, L issotriton helveticus, and T riturus cristatus) and comparison with Illumina‐based approaches | |
| Nie et al. | Development of chromosome‐arm‐specific microsatellite markers in Triticum aestivum (Poaceae) using NGS technology | |
| Han et al. | Spy: a new group of eukaryotic DNA transposons without target site duplications | |
| Bertozzi et al. | Anonymous nuclear loci in non-model organisms: making the most of high-throughput genome surveys | |
| Lohse et al. | Developing EPIC markers for chalcidoid Hymenoptera from EST and genomic data | |
| Xu et al. | A novel set of 223 EST-SSR markers in Casuarina L. ex Adans.: polymorphisms, cross-species transferability, and utility for commercial clone genotyping | |
| Cera et al. | Functionally related genes cluster into genomic regions that coordinate transcription at a distance in Saccharomyces cerevisiae | |
| Batley et al. | Identification and characterization of simple sequence repeat markers from Brassica napus expressed sequences | |
| Huang et al. | Genome‐wide expression quantitative trait locus analysis in a recombinant inbred line population for trait dissection in peanut | |
| Nguyen et al. | Amplification of multiple copies of mitochondrial Cytochrome b gene fragments in the Australian freshwater crayfish, Cherax destructor Clark (Parastacidae: Decapoda) | |
| Bontemps et al. | Microarray-based detection and typing of the Rhizobium nodulation gene nodC: potential of DNA arrays to diagnose biological functions of interest | |
| US6629038B1 (en) | Method and system for identifying commercially distributed organisms | |
| Ganal et al. | Sequencing of cDNA clones from the genetic map of tomato (Lycopersicon esculentum) | |
| Arias et al. | Sixteen draft genome sequences representing the genetic diversity of Aspergillus flavus and Aspergillus parasiticus colonizing peanut seeds in Ethiopia | |
| Biedler et al. | Transposable element (TE) display and rapid detection of TE insertion polymorphism in the Anopheles gambiae species complex | |
| Khodosevich et al. | Large‐scale determination of the methylation status of retrotransposons in different tissues using a methylation tags approach | |
| US8433522B2 (en) | Information processing system using nucleotide sequence-related information |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| AS | Assignment |
Owner name: YEDA RESEARCH AND DEVELOPMENT CO., LTD., ISRAEL Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNOR:GRESSEL, JONATHAN;REEL/FRAME:013934/0965 Effective date: 20030227 |
|
| STCB | Information on status: application discontinuation |
Free format text: ABANDONED -- FAILURE TO RESPOND TO AN OFFICE ACTION |